How to Read PDF File in C#
-
PDF Parsing in
C# -
Use IronPDF to Read/Parse PDF File in
C# -
Use iTextSharp to Read/Parse PDF File in
C#

This article is about parsing a PDF document and storing it in a string variable. This variable can be used for multiple purposes in a C# program.
PDF Parsing in C#
It can be simple to work with PDFs in C# and use all the functionality required for a .NET application, including using C#’s library to parse PDF files. This tutorial will accomplish that in just a few simple steps using two different C# libraries, IronPDF and iTextSharp.
Use IronPDF to Read/Parse PDF File in C#
IronPDF is a commercial library developed in C# for generating and parsing PDF documents. It has the feature of generating PDFs from strings or even HTML.
It works for all types of .NET applications, desktop applications, web applications, server applications, or even WPF applications.
The steps for using the library to read a PDF file are enumerated below:
-
Download the IronPDF library in your Visual Studio using the NuGet Package installer.
-
Right-click on your project name in the Solution Explorer window and select Manage NuGet Packages.
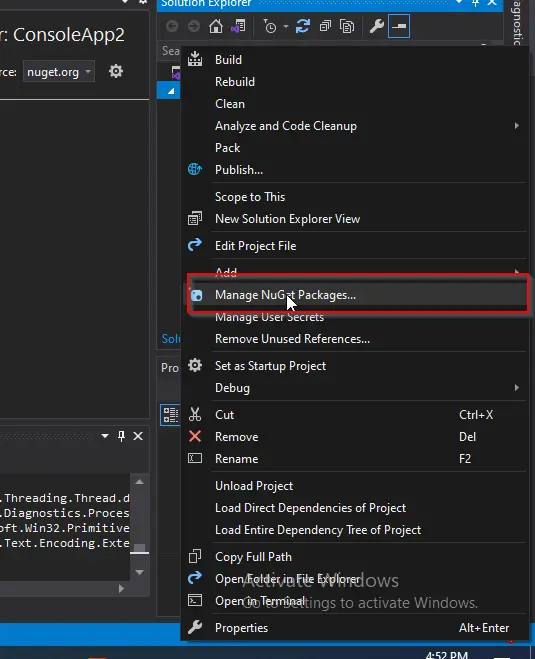
-
The NuGet Package window will appear. In that window, in the Browse tab, search for IronPDF and then select the first library.
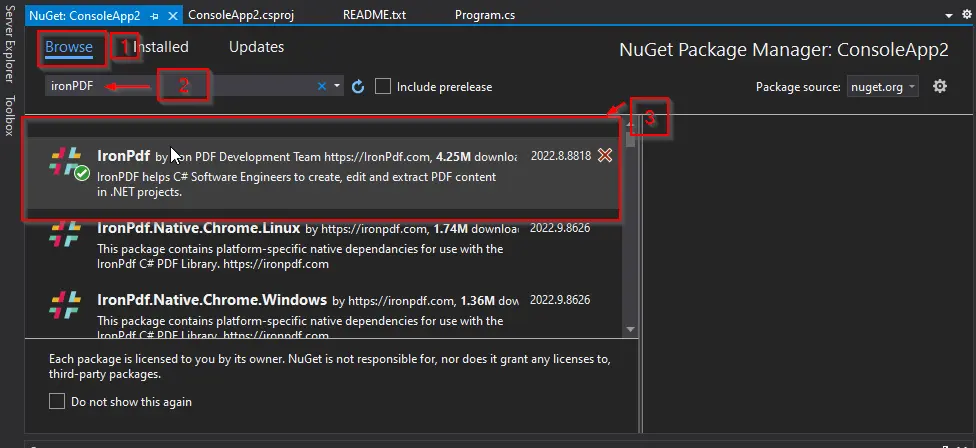
-
Write the code to parse PDF documents.
Playing around with IronPDF will show you how many features it has to make working with PDF files in C# simpler. It is primarily concerned with producing, reading, and editing any PDF file in the formats required.
PDF files can be easily parsed.
The ExtractAllText() method is used in the code below to retrieve every single text line from the entire PDF file. You can later view the output, which shows the PDF file’s content.
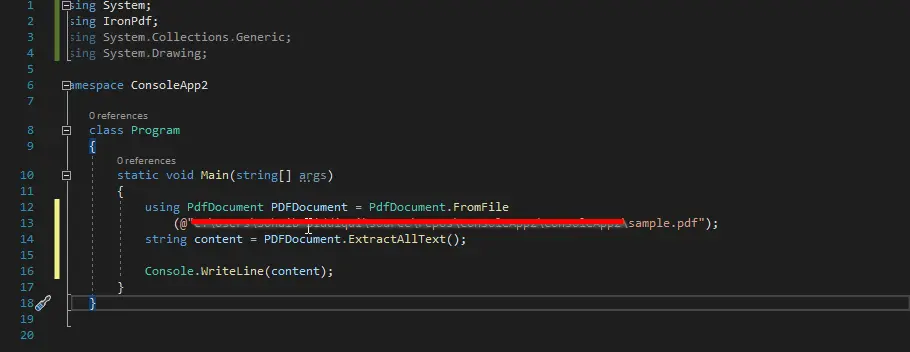
You can see from the code that we first created an object of PdfDocument and passed it to the path of the file to be parsed.
Then we called a method ExtractAllText() and stored all the content in a string variable content. Then we displayed that variable on the screen.
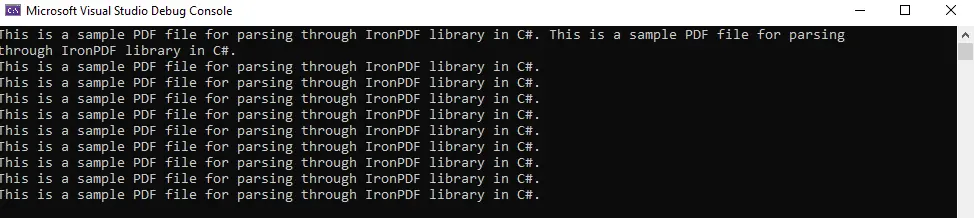
It is a very simple and straightforward task. You can see the output below:
Use iTextSharp to Read/Parse PDF File in C#
iTextSharp is another C# library that is an advanced tool for creating complex PDF reports; these reports can be used by multiple platform applications, like Android, IOS, or Java. It has functionalities that can create PDFs using the data from the database or XML formats and merge or split down any PDF document.
The steps for using iTextSharp to read a PDF file are shown below:
-
Download the iTextSharp library in your Visual Studio using the NuGet Package installer.
-
Right-click on your project name in the Solution Explorer window and select Manage NuGet Packages.
-
The NuGet Package window will appear. In that window, in the Browse tab, search for iTextSharp, select the first library and choose Install.
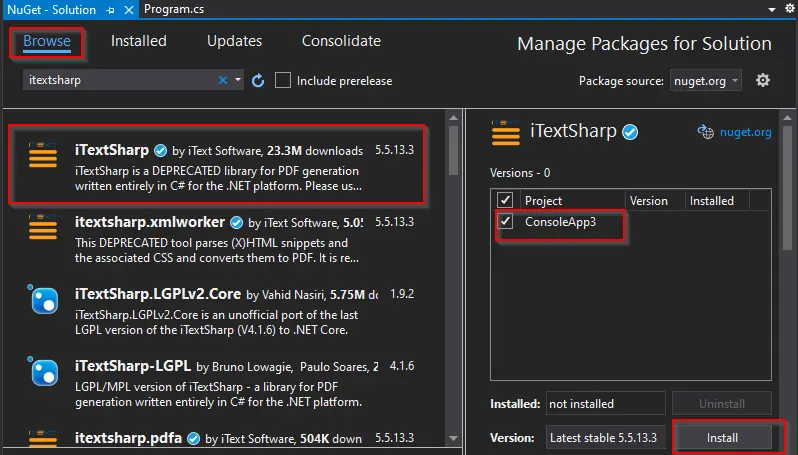
-
Include the following libraries in your
csfile:using iTextSharp.text.pdf; using iTextSharp.text.pdf.parser; -
Let us now create a function that will read a PDF file and parse that PDF file in a string variable.
public static string parsePDFDocument(string filePath) { using (PdfReader read = new PdfReader(filePath)) { StringBuilder convertedText = new StringBuilder(); for (int p = 1; p <= read.NumberOfPages; p++) { convertedText.Append(PdfTextExtractor.GetTextFromPage(read, p)); } return convertedText.ToString(); } }
In this code snippet, we have created an object of the PdfReader class, which is a part of the iTextSharp library. This object takes a file path of the PDF document to be parsed.
After that, we created a string using the StringBuilder class that can contain the text from a PDF file.
The loop then starts from the first page to the total number of pages in the PDF document. Inside the loop, we have appended the text in the created string object page by page.
In the end, the string is returned to the point where the function will be called.
Our Main function will look like this:
static void Main(string[] args) {
var ExtractedTextFromPDF = parsePDFDocument([path to PDF file]);
Console.WriteLine(ExtractedTextFromPDF);
}
Make sure to pass the PDF file with its complete path. After compilation, it will give the following output:
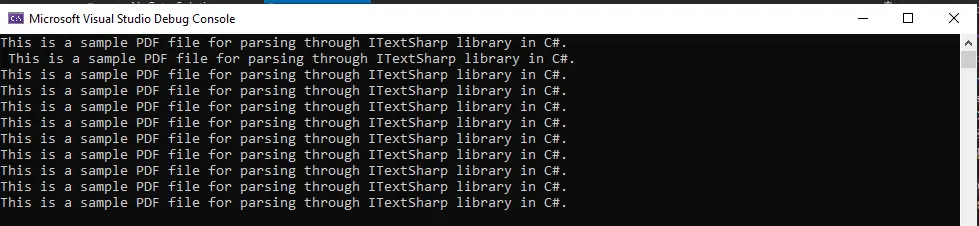
The output shows that the entire PDF file is converted to text and displayed on the screen.
This library provides methods to split the document based on page numbers. Furthermore, the functionalities to create PDFs are also available in this library.