C#에서 PDF 파일 읽기

이 문서는 PDF 문서를 구문 분석하고 문자열 변수에 저장하는 방법에 관한 것입니다. 이 변수는 C# 프로그램에서 여러 용도로 사용할 수 있습니다.
C#에서 PDF 구문 분석
C#에서 PDF로 간단하게 작업하고 C#의 라이브러리를 사용하여 PDF 파일을 구문 분석하는 것을 포함하여 .NET 애플리케이션에 필요한 모든 기능을 사용할 수 있습니다. 이 자습서에서는 IronPDF 및 iTextSharp라는 두 가지 C# 라이브러리를 사용하여 몇 가지 간단한 단계로 이를 수행합니다.
IronPDF를 사용하여 C#에서 PDF 파일 읽기/파싱
IronPDF는 PDF 문서를 생성하고 구문 분석하기 위해 C#으로 개발된 상용 라이브러리입니다. 문자열 또는 HTML에서 PDF를 생성하는 기능이 있습니다.
모든 유형의 .NET 응용 프로그램, 데스크톱 응용 프로그램, 웹 응용 프로그램, 서버 응용 프로그램 또는 WPF 응용 프로그램에서도 작동합니다.
라이브러리를 사용하여 PDF 파일을 읽는 단계는 다음과 같습니다.
-
NuGet 패키지 설치 관리자를 사용하여 Visual Studio에서 IronPDF 라이브러리를 다운로드합니다.
-
솔루션 탐색기 창에서 프로젝트 이름을 마우스 오른쪽 단추로 클릭하고 NuGet 패키지 관리를 선택합니다.
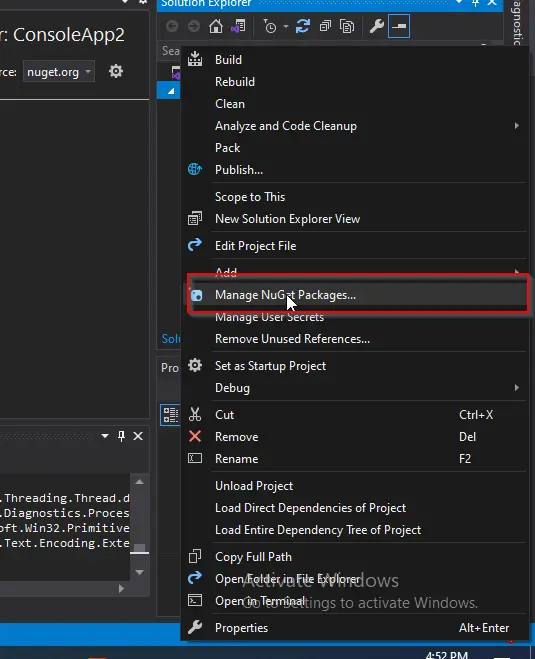
-
NuGet 패키지 창이 나타납니다. 해당 창의 찾아보기 탭에서 IronPDF를 검색한 다음 첫 번째 라이브러리를 선택합니다.
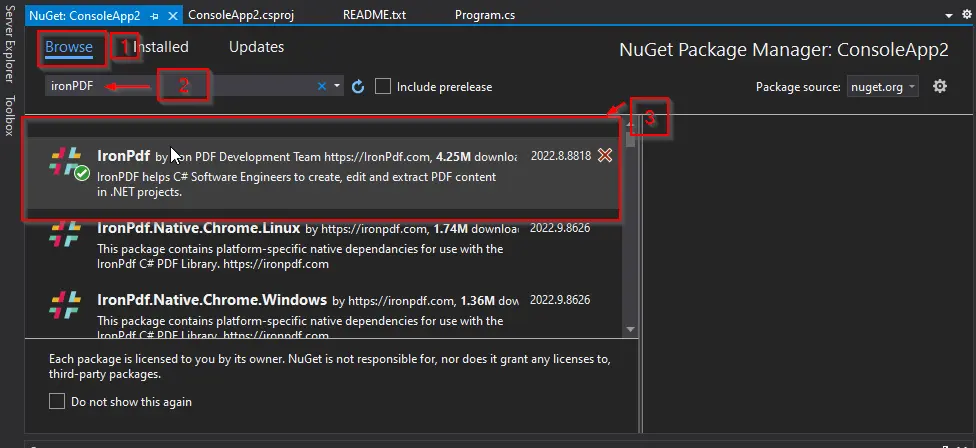
-
PDF 문서를 구문 분석하는 코드를 작성합니다.
IronPDF를 가지고 놀면 C#에서 PDF 파일 작업을 더 간단하게 만드는 기능이 얼마나 많은지 알 수 있습니다. 주로 필요한 형식으로 PDF 파일을 생성, 읽기 및 편집하는 것과 관련이 있습니다.
PDF 파일을 쉽게 파싱할 수 있습니다.
ExtractAllText() 메서드는 전체 PDF 파일에서 모든 단일 텍스트 줄을 검색하기 위해 아래 코드에서 사용됩니다. 나중에 PDF 파일의 내용을 보여주는 출력을 볼 수 있습니다.
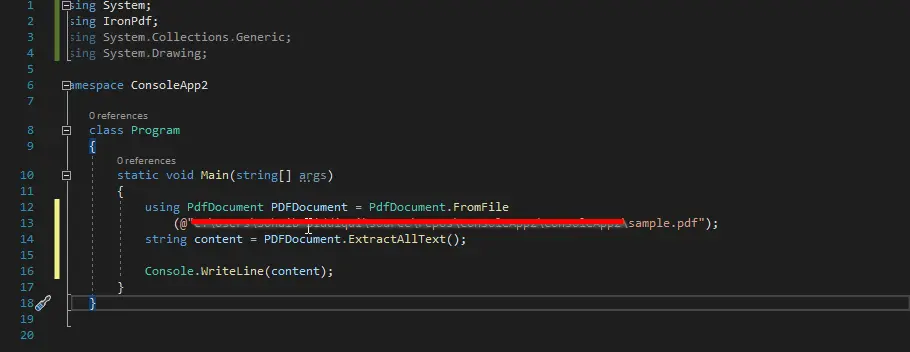
코드에서 우리가 먼저 PdfDocument 객체를 생성하고 이를 파싱할 파일의 경로에 전달한 것을 볼 수 있습니다.
그런 다음 ExtractAllText() 메서드를 호출하고 문자열 변수 content에 모든 내용을 저장했습니다. 그런 다음 해당 변수를 화면에 표시했습니다.
매우 간단하고 직관적인 작업입니다. 아래 출력을 볼 수 있습니다.
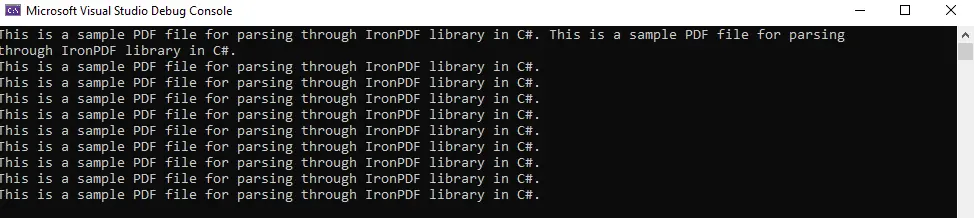
iTextSharp를 사용하여 C#에서 PDF 파일 읽기/파싱
iTextSharp는 복잡한 PDF 보고서를 만들기 위한 고급 도구인 또 다른 C# 라이브러리입니다. 이러한 보고서는 Android, IOS 또는 Java와 같은 여러 플랫폼 애플리케이션에서 사용할 수 있습니다. 데이터베이스 또는 XML 형식의 데이터를 사용하여 PDF를 생성하고 PDF 문서를 병합하거나 분할할 수 있는 기능이 있습니다.
iTextSharp를 사용하여 PDF 파일을 읽는 단계는 다음과 같습니다.
-
NuGet 패키지 설치 관리자를 사용하여 Visual Studio에서 iTextSharp 라이브러리를 다운로드합니다.
-
솔루션 탐색기 창에서 프로젝트 이름을 마우스 오른쪽 단추로 클릭하고 NuGet 패키지 관리를 선택합니다.
-
NuGet 패키지 창이 나타납니다. 해당 창의 찾아보기 탭에서 iTextSharp를 검색하고 첫 번째 라이브러리를 선택한 다음 설치를 선택합니다.
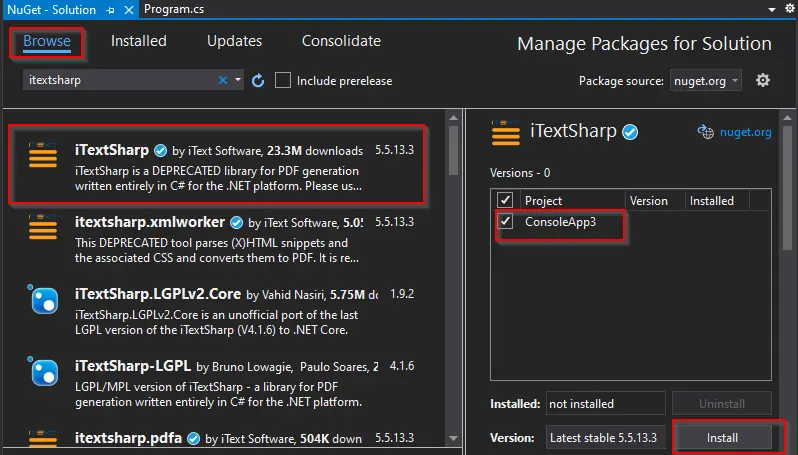
-
cs파일에 다음 라이브러리를 포함합니다.using iTextSharp.text.pdf; using iTextSharp.text.pdf.parser; -
이제 PDF 파일을 읽고 문자열 변수에서 해당 PDF 파일을 구문 분석하는 함수를 만들어 보겠습니다.
public static string parsePDFDocument(string filePath) { using (PdfReader read = new PdfReader(filePath)) { StringBuilder convertedText = new StringBuilder(); for (int p = 1; p <= read.NumberOfPages; p++) { convertedText.Append(PdfTextExtractor.GetTextFromPage(read, p)); } return convertedText.ToString(); } }
이 코드 조각에서는 iTextSharp 라이브러리의 일부인 PdfReader 클래스의 개체를 만들었습니다. 이 개체는 구문 분석할 PDF 문서의 파일 경로를 사용합니다.
그런 다음 StringBuilder 클래스를 사용하여 PDF 파일의 텍스트를 포함할 수 있는 문자열을 만들었습니다.
그런 다음 루프는 첫 번째 페이지부터 PDF 문서의 총 페이지 수까지 시작됩니다. 루프 내에서 생성된 문자열 개체의 텍스트를 페이지별로 추가했습니다.
결국 함수가 호출될 지점까지 문자열이 반환됩니다.
Main 기능은 다음과 같습니다.
static void Main(string[] args) {
var ExtractedTextFromPDF = parsePDFDocument([path to PDF file]);
Console.WriteLine(ExtractedTextFromPDF);
}
전체 경로와 함께 PDF 파일을 전달해야 합니다. 컴파일 후 다음과 같은 결과가 출력됩니다.
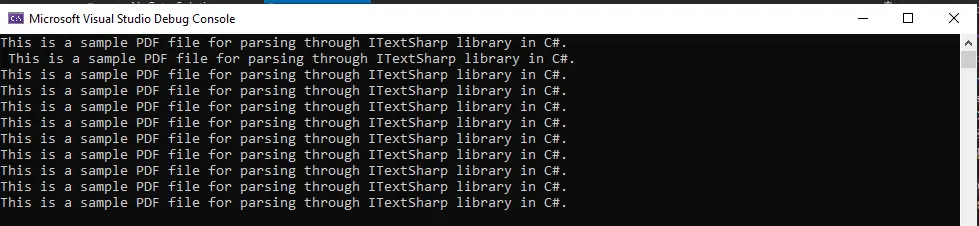
출력은 전체 PDF 파일이 텍스트로 변환되어 화면에 표시됨을 보여줍니다.
이 라이브러리는 페이지 번호를 기준으로 문서를 분할하는 방법을 제공합니다. 또한 PDF를 만드는 기능도 이 라이브러리에서 사용할 수 있습니다.