PDF-Datei in C# lesen
-
PDF-Parsing in
C# -
Verwenden Sie IronPDF zum Lesen/Parsen von PDF-Dateien in
C# -
Verwenden Sie iTextSharp zum Lesen/Parsen von PDF-Dateien in
C#

In diesem Artikel geht es darum, ein PDF-Dokument zu parsen und in einer String-Variablen zu speichern. Diese Variable kann in einem C#-Programm für mehrere Zwecke verwendet werden.
PDF-Parsing in C#
Es kann einfach sein, mit PDFs in C# zu arbeiten und alle Funktionen zu nutzen, die für eine .NET-Anwendung erforderlich sind, einschließlich der Verwendung der C#-Bibliothek zum Analysieren von PDF-Dateien. Dieses Tutorial wird dies in nur wenigen einfachen Schritten mit zwei verschiedenen C#-Bibliotheken, IronPDF und iTextSharp, erreichen.
Verwenden Sie IronPDF zum Lesen/Parsen von PDF-Dateien in C#
IronPDF ist eine in C# entwickelte kommerzielle Bibliothek zum Generieren und Analysieren von PDF-Dokumenten. Es hat die Funktion, PDFs aus Strings oder sogar HTML zu generieren.
Es funktioniert für alle Arten von .NET-Anwendungen, Desktopanwendungen, Webanwendungen, Serveranwendungen oder sogar WPF-Anwendungen.
Die Schritte zum Verwenden der Bibliothek zum Lesen einer PDF-Datei sind unten aufgeführt:
-
Laden Sie die IronPDF-Bibliothek mithilfe des NuGet-Paketinstallationsprogramms in Visual Studio herunter.
-
Klicken Sie im Projektmappen-Explorer-Fenster mit der rechten Maustaste auf Ihren Projektnamen, und wählen Sie NuGet-Pakete verwalten aus.
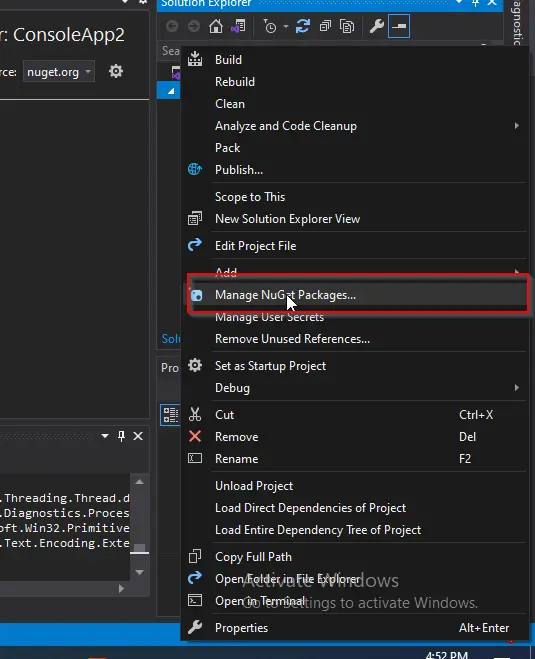
-
Das NuGet-Paketfenster wird angezeigt. Suchen Sie in diesem Fenster auf der Registerkarte Durchsuchen nach IronPDF und wählen Sie dann die erste Bibliothek aus.
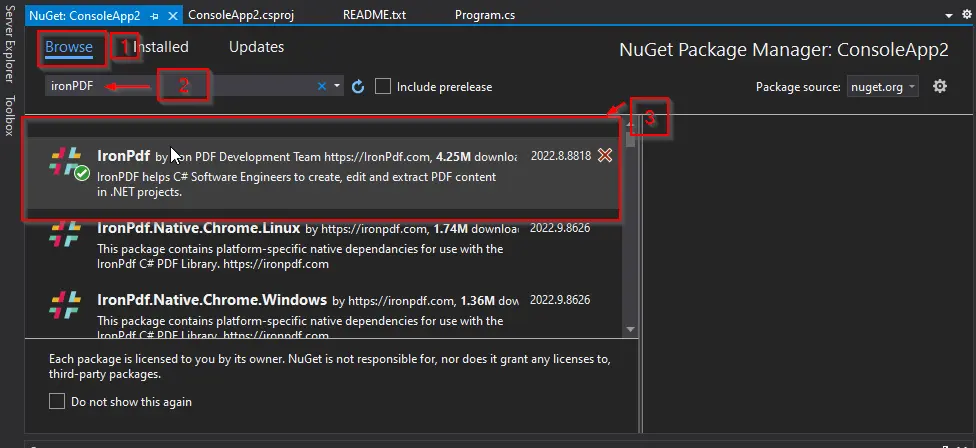
-
Schreiben Sie den Code zum Analysieren von PDF-Dokumenten.
Wenn Sie mit IronPDF herumspielen, werden Sie sehen, wie viele Funktionen es hat, um die Arbeit mit PDF-Dateien in C# zu vereinfachen. Es befasst sich hauptsächlich mit dem Erstellen, Lesen und Bearbeiten von PDF-Dateien in den erforderlichen Formaten.
PDF-Dateien können einfach analysiert werden.
Die Methode ExtractAllText() wird im folgenden Code verwendet, um jede einzelne Textzeile aus der gesamten PDF-Datei abzurufen. Sie können später die Ausgabe anzeigen, die den Inhalt der PDF-Datei zeigt.
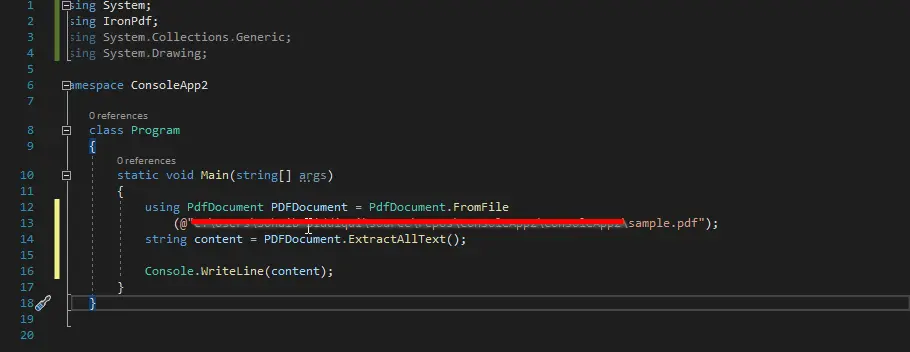
Sie können aus dem Code ersehen, dass wir zuerst ein Objekt von PdfDocument erstellt und es an den Pfad der zu analysierenden Datei übergeben haben.
Dann haben wir eine Methode ExtractAllText() aufgerufen und den gesamten Inhalt in einer String-Variablen content gespeichert. Dann haben wir diese Variable auf dem Bildschirm angezeigt.
Es ist eine sehr einfache und unkomplizierte Aufgabe. Sie können die Ausgabe unten sehen:
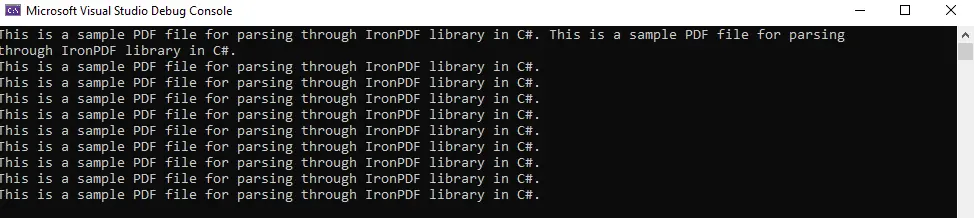
Verwenden Sie iTextSharp zum Lesen/Parsen von PDF-Dateien in C#
iTextSharp ist eine weitere C#-Bibliothek, die ein fortschrittliches Tool zum Erstellen komplexer PDF-Berichte ist; Diese Berichte können von mehreren Plattformanwendungen wie Android, IOS oder Java verwendet werden. Es verfügt über Funktionen, die PDFs mit den Daten aus der Datenbank oder XML-Formaten erstellen und beliebige PDF-Dokumente zusammenführen oder aufteilen können.
Die Schritte zum Verwenden von iTextSharp zum Lesen einer PDF-Datei sind unten dargestellt:
-
Laden Sie die iTextSharp-Bibliothek mithilfe des NuGet-Paketinstallationsprogramms in Visual Studio herunter.
-
Klicken Sie im Projektmappen-Explorer-Fenster mit der rechten Maustaste auf Ihren Projektnamen, und wählen Sie NuGet-Pakete verwalten aus.
-
Das NuGet-Paketfenster wird angezeigt. Suchen Sie in diesem Fenster auf der Registerkarte Durchsuchen nach iTextSharp, wählen Sie die erste Bibliothek aus und wählen Sie Installieren.
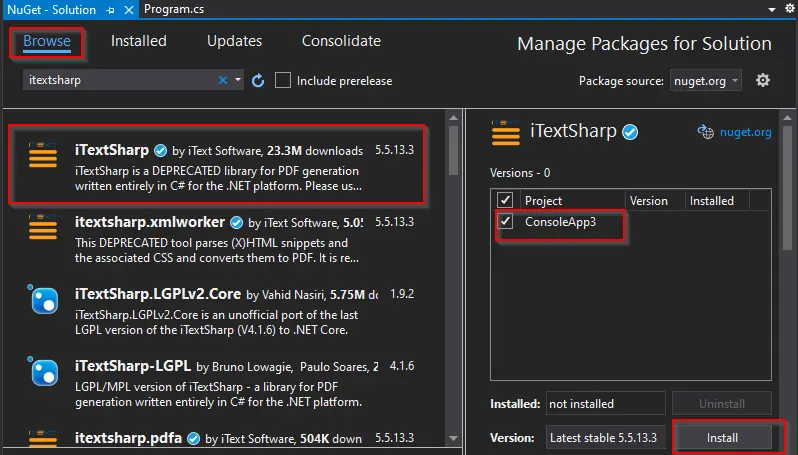
-
Binden Sie die folgenden Bibliotheken in Ihre
cs-Datei ein:using iTextSharp.text.pdf; using iTextSharp.text.pdf.parser; -
Lassen Sie uns nun eine Funktion erstellen, die eine PDF-Datei liest und diese PDF-Datei in einer String-Variablen analysiert.
public static string parsePDFDocument(string filePath) { using (PdfReader read = new PdfReader(filePath)) { StringBuilder convertedText = new StringBuilder(); for (int p = 1; p <= read.NumberOfPages; p++) { convertedText.Append(PdfTextExtractor.GetTextFromPage(read, p)); } return convertedText.ToString(); } }
In diesem Code-Snippet haben wir ein Objekt der Klasse PdfReader erstellt, das Teil der iTextSharp-Bibliothek ist. Dieses Objekt übernimmt einen Dateipfad des zu analysierenden PDF-Dokuments.
Danach haben wir mit der Klasse StringBuilder einen String erstellt, der den Text aus einer PDF-Datei enthalten kann.
Die Schleife beginnt dann von der ersten Seite bis zur Gesamtseitenzahl im PDF-Dokument. Innerhalb der Schleife haben wir den Text Seite für Seite an das erstellte String-Objekt angehängt.
Am Ende wird der String an die Stelle zurückgegeben, an der die Funktion aufgerufen wird.
Unsere Main-Funktion sieht so aus:
static void Main(string[] args) {
var ExtractedTextFromPDF = parsePDFDocument([path to PDF file]);
Console.WriteLine(ExtractedTextFromPDF);
}
Stellen Sie sicher, dass Sie die PDF-Datei mit ihrem vollständigen Pfad übergeben. Nach der Kompilierung wird folgende Ausgabe ausgegeben:
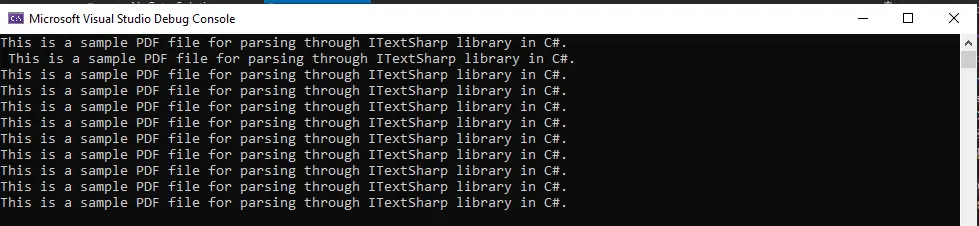
Die Ausgabe zeigt, dass die gesamte PDF-Datei in Text konvertiert und auf dem Bildschirm angezeigt wird.
Diese Bibliothek bietet Methoden zum Teilen des Dokuments basierend auf Seitenzahlen. Darüber hinaus stehen in dieser Bibliothek auch die Funktionalitäten zum Erstellen von PDFs zur Verfügung.