SciPy stats.normaltest Fucntion
-
the
scipy.stats.normaltestFunction -
scipy.stats.normaltestFunction Usingnumpy.linspace() -
scipy.stats.normaltestFunction Using Random Data
The normality test in statistics helps calculate how a random variable in a given data set is normally distributed. Also, this test is used to predicted how well is a given set of data structured by the normal distribution.
the scipy.stats.normaltest Function
The scipy.stats.normaltest function of the SciPy library is used to check if a given sample value varies from the normal distribution of the data set. This function also checks if there is any difference between some characteristics of the data or not. This process is also known as the null hypothesis. This function is defined as scipy.stats.normaltest(a, axis, nan_policy)
Following are the parameters of the scipy.stats.normaltest function.
a (array) |
defines the input array that contains the sample data that has to be tested. |
axis (int) |
defines the axis along which the function performs the test of the sample data. The default value is 0 i.e, the function computes the test over the whole array. |
nan_policy |
It determines how to deal when there are NaN values in the input data. There are three decision parameters in the parameter, propagate, raise, omit. propagate simply returns the NaN value, raise returns an error and omit simply ignores the NaN values and the function continues with computation. These decision parameters are defined in single quotes ' '. Also, the default is set to propagate. |
All the parameters except the a (array) parameter are optional. That means it is not necessary to define them every time while using the scipy.stats.normaltest function.
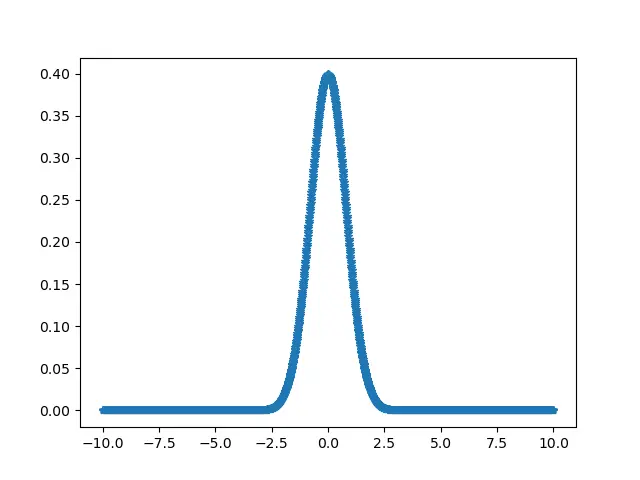
scipy.stats.normaltest Function Using numpy.linspace()
The linespace() function of the NumPy library helps in creating random numerical sequences that are evenly spaced.
from scipy.stats import normaltest
import numpy as np
import pylab as p
a = np.linspace(-10, 10, 2000)
b = 1 / (np.sqrt(2 * np.pi)) * np.exp(-0.8 * (a) ** 2)
p.plot(a, b, "*")
print("Normal test of the data = \n ", normaltest(b))
Output:
scipy.stats.normaltest Function Using Random Data
The np.random.normal function of the NumPy library is used in this method. This function helps create an array of a specified shape and size that consists of random values that are actually part of the gaussian distribution.
from scipy.stats import normaltest
import numpy as np
n = np.random.normal(0, 10, 10000)
print("N : ", n)
print("Normal test for input data : ", normaltest(n))
Output:
N : [ 3.66175422 6.36095281 -0.84266502 ... -3.8817569 2.72610919
1.80849087]
Normal test for input data : NormaltestResult(statistic=4.626780379099072, pvalue=0.09892530688176408)

Lakshay Kapoor is a final year B.Tech Computer Science student at Amity University Noida. He is familiar with programming languages and their real-world applications (Python/R/C++). Deeply interested in the area of Data Sciences and Machine Learning.
LinkedIn