SciPy stats.normaltest Funktion
-
Die
scipy.stats.normaltest-Funktion -
scipy.stats.normaltestFunktion mitnumpy.linspace() -
scipy.stats.normaltestFunktion, die Zufallsdaten verwendet
Der Normalitätstest in der Statistik hilft zu berechnen, wie eine Zufallsvariable in einem gegebenen Datensatz normalverteilt ist. Außerdem wird dieser Test verwendet, um vorherzusagen, wie gut ein bestimmter Datensatz durch die Normalverteilung strukturiert ist.
Die scipy.stats.normaltest-Funktion
Die Funktion scipy.stats.normaltest der SciPy-Bibliothek wird verwendet, um zu prüfen, ob ein gegebener Stichprobenwert von der Normalverteilung des Datensatzes abweicht. Diese Funktion prüft auch, ob es einen Unterschied zwischen einigen Merkmalen der Daten gibt oder nicht. Dieser Vorgang wird auch als Nullhypothese bezeichnet. Diese Funktion ist definiert als scipy.stats.normaltest(a, axis, nan_policy)
Nachfolgend sind die Parameter der Funktion scipy.stats.normaltest aufgeführt.
a (Array) |
definiert das Eingabearray, das die zu testenden Beispieldaten enthält. |
axis (int) |
definiert die Achse, entlang der die Funktion den Test der Beispieldaten durchführt. Der Standardwert ist 0, d. h. die Funktion berechnet den Test über das gesamte Array. |
nan_policy |
Es bestimmt, wie mit NaN-Werten in den Eingabedaten umgegangen wird. Im Parameter gibt es drei Entscheidungsparameter, propagate, raise, omit. propagate gibt einfach den NaN-Wert zurück, raise gibt einen Fehler zurück und omit ignoriert einfach die NaN-Werte und die Funktion fährt mit der Berechnung fort. Diese Entscheidungsparameter werden in einfachen Anführungszeichen ' ' definiert. Außerdem ist die Voreinstellung auf propagate gesetzt. |
Alle Parameter außer dem Parameter a (array) sind optional. Das bedeutet, dass sie nicht jedes Mal neu definiert werden müssen, wenn die Funktion scipy.stats.normaltest verwendet wird.
scipy.stats.normaltest Funktion mit numpy.linspace()
Die Funktion linespace() der Bibliothek NumPy hilft beim Erstellen zufälliger Zahlenfolgen mit gleichen Abständen.
from scipy.stats import normaltest
import numpy as np
import pylab as p
a = np.linspace(-10, 10, 2000)
b = 1 / (np.sqrt(2 * np.pi)) * np.exp(-0.8 * (a) ** 2)
p.plot(a, b, "*")
print("Normal test of the data = \n ", normaltest(b))
Ausgabe:
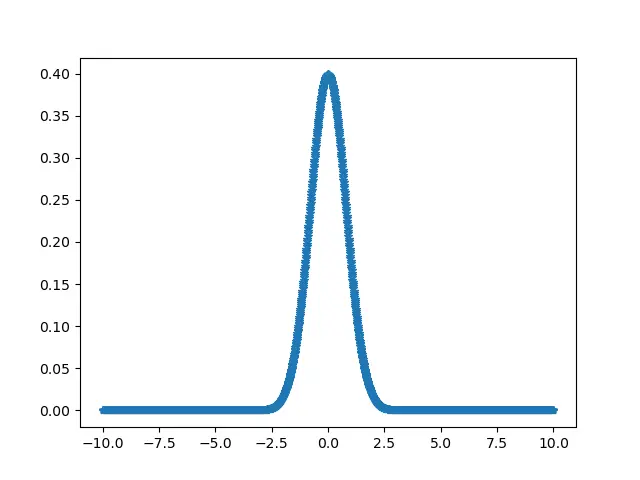
scipy.stats.normaltest Funktion, die Zufallsdaten verwendet
Bei dieser Methode wird die Funktion np.random.normal der Bibliothek NumPy verwendet. Diese Funktion hilft beim Erstellen eines Arrays mit einer bestimmten Form und Größe, das aus zufälligen Werten besteht, die tatsächlich Teil der Gaußschen Verteilung sind.
from scipy.stats import normaltest
import numpy as np
n = np.random.normal(0, 10, 10000)
print("N : ", n)
print("Normal test for input data : ", normaltest(n))
Ausgabe:
N : [ 3.66175422 6.36095281 -0.84266502 ... -3.8817569 2.72610919
1.80849087]
Normal test for input data : NormaltestResult(statistic=4.626780379099072, pvalue=0.09892530688176408)

Lakshay Kapoor is a final year B.Tech Computer Science student at Amity University Noida. He is familiar with programming languages and their real-world applications (Python/R/C++). Deeply interested in the area of Data Sciences and Machine Learning.
LinkedIn