Función SciPy stats.normaltest
-
La función
scipy.stats.normaltest -
Función
scipy.stats.normaltestutilizandonumpy.linspace() -
Función
scipy.stats.normaltestutilizando datos aleatorios
La prueba de normalidad en estadística ayuda a calcular cómo se distribuye normalmente una variable aleatoria en un conjunto de datos determinado. Además, esta prueba se utiliza para predecir qué tan bien está estructurado un conjunto dado de datos por la distribución normal.
La función scipy.stats.normaltest
La función scipy.stats.normaltest de la biblioteca SciPy se utiliza para verificar si un valor de muestra dado varía de la distribución normal del conjunto de datos. Esta función también comprueba si hay alguna diferencia entre algunas características de los datos o no. Este proceso también se conoce como la hipótesis nula. Esta función se define como scipy.stats.normaltest(a, axis, nan_policy)
Los siguientes son los parámetros de la función scipy.stats.normaltest.
a (matriz) |
define el array de entrada que contiene los datos de muestra que deben probarse. |
axis(int) |
define el eje a lo largo del cual la función realiza la prueba de los datos de muestra. El valor predeterminado es 0, es decir, la función calcula la prueba en toda el array. |
nan_policy |
Determina cómo tratar cuando hay valores de NaN en los datos de entrada. Hay tres parámetros de decisión en el parámetro, propagate, raise, omit. El parámetro propagate simplemente devuelve el valor de NaN, raise devuelve un error y omit simplemente ignora los valores de NaN y la función continúa con el cálculo. Estos parámetros de decisión se definen entre comillas simples ' '. Además, el valor predeterminado está configurado para propagate. |
Todos los parámetros excepto el parámetro a (array) son opcionales. Eso significa que no es necesario definirlos cada vez que se usa la función scipy.stats.normaltest.
Función scipy.stats.normaltest utilizando numpy.linspace()
La función linespace() de la biblioteca NumPy ayuda a crear secuencias numéricas aleatorias que están espaciadas uniformemente.
from scipy.stats import normaltest
import numpy as np
import pylab as p
a = np.linspace(-10, 10, 2000)
b = 1 / (np.sqrt(2 * np.pi)) * np.exp(-0.8 * (a) ** 2)
p.plot(a, b, "*")
print("Normal test of the data = \n ", normaltest(b))
Producción:
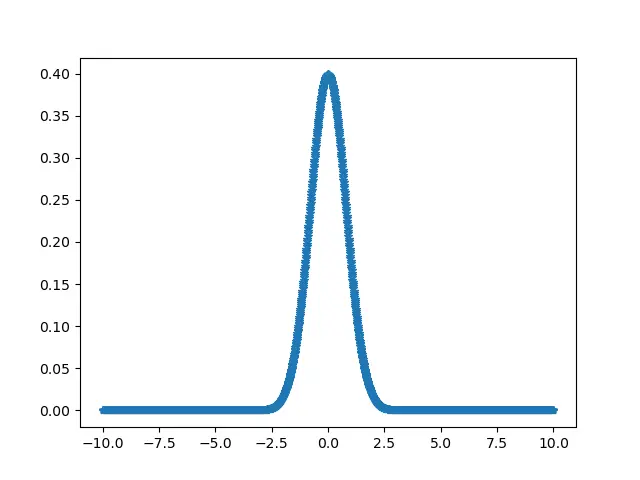
Función scipy.stats.normaltest utilizando datos aleatorios
En este método se utiliza la función np.random.normal de la biblioteca NumPy. Esta función ayuda a crear una matriz de una forma y tamaño especificados que consta de valores aleatorios que en realidad son parte de la distribución gaussiana.
from scipy.stats import normaltest
import numpy as np
n = np.random.normal(0, 10, 10000)
print("N : ", n)
print("Normal test for input data : ", normaltest(n))
Producción:
N : [ 3.66175422 6.36095281 -0.84266502 ... -3.8817569 2.72610919
1.80849087]
Normal test for input data : NormaltestResult(statistic=4.626780379099072, pvalue=0.09892530688176408)

Lakshay Kapoor is a final year B.Tech Computer Science student at Amity University Noida. He is familiar with programming languages and their real-world applications (Python/R/C++). Deeply interested in the area of Data Sciences and Machine Learning.
LinkedIn