Función SciPy stats.kurtosis
La Kurtosis en estadística ayuda a encontrar la diferencia entre el peso de las colas de una distribución particular y el peso de las colas de una distribución normal de datos dados. Entonces, esta medida estadística ayuda a identificar si las colas de una distribución particular consisten en un valor extremo.
Junto a esta medida estadística, existe una métrica más conocida como exceso de curtosis. Esta medida ayuda a comparar la curtosis de una distribución particular con la curtosis de una distribución normal. El exceso de curtosis se puede calcular de la siguiente manera.
Excess Kurtosis = Kurtosis - 3
Hay tres tipos de kurtosis. El tipo de Kurtosis se define por el exceso de curtosis de una distribución específica.
- Mesokúrtica: si un dato dado representa una distribución mesocúrtica, muestra un exceso de curtosis que es cero o cercano a cero. En otras palabras, un dato dado sigue una distribución mesocúrtica si muestra una distribución normal.
- Leptokurtic - Leptokurtic muestra un exceso de curtosis positivo. La distribución leptocúrtica representa colas muy pesadas en ambos lados, lo que denota algunos valores a una distancia poco común de otros valores en los datos, también conocidos como
outliers. - Platykurtic - La distribución platykurtic representa un exceso de curtosis negativo. La curtosis muestra una distribución que tiene colas planas. Las colas planas en una distribución indican que hay pequeños valores atípicos presentes.
La función scipy.stats.kurtosis
La función scipy.stats.kurtosis de la biblioteca SciPy ayuda a calcular la Kurtosis de un conjunto de datos determinado.
Sintaxis
scipy.stats.kurtosis(a, axis=0, fisher=True, bias=True, nan_policy="raise")
Parámetros
a (array) |
Define los datos de entrada para los que se calcula la curtosis. | |
axis (int) |
Define el eje a lo largo del cual se calcula la curtosis de los datos de entrada. El valor por defecto de este parámetro es 0. Si el valor es None, entonces la función simplemente calcula sobre todos los datos de entrada. |
|
fisher (bool) |
Un parámetro booleano. Si el valor de este parámetro es True, se utiliza la definición de Fisher, es decir, normal ==> 0.0. Y si el valor del parámetro es False, se utiliza la definición de Pearson, es decir, normal ==> 3.0. |
|
bias (bool) |
Este también es un parámetro booleano. Si el valor de este parámetro es False, todos los cálculos se corrigen por el sesgo estadístico. |
|
nan_policy |
Este parámetro decide cómo tratar cuando hay valores de NaN en los datos de entrada. Hay tres parámetros de decisión en el parámetro, propagate, raise, omit. propagate simplemente devuelve el valor de NaN, raise devuelve un error y omit simplemente ignora los valores de NaN y la función continúa con el cálculo. Estos parámetros de decisión se definen entre comillas simples ''. El valor por defecto de este parámetro es propagate. |
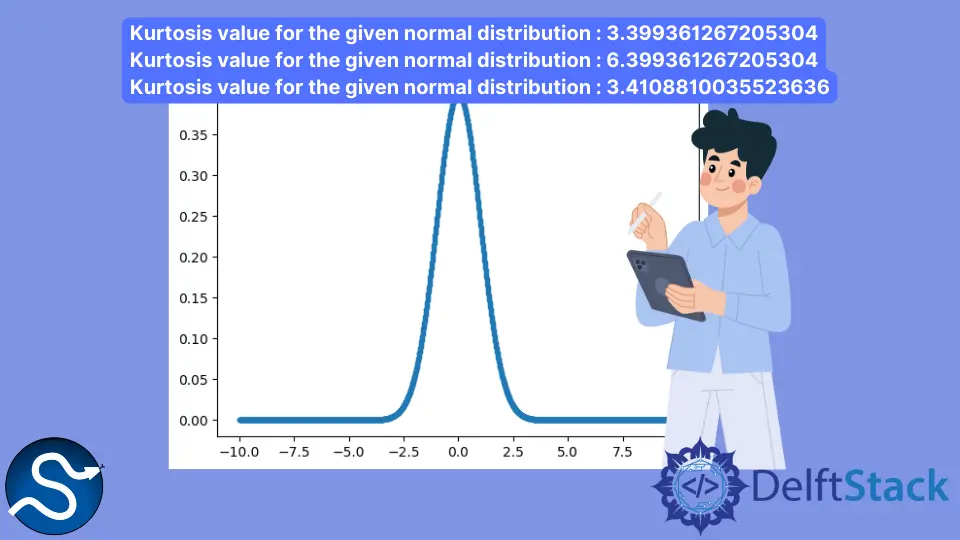
Ejemplo de curtosis
from scipy.stats import kurtosis
import numpy as np
import pylab as p
a = np.linspace(-10, 10, 2000)
b = 1 / (np.sqrt(2 * np.pi)) * np.exp(-0.5 * (a) ** 2)
p.plot(a, b, ".")
print("Kurtosis value for the given normal distribution :", kurtosis(b))
print("Kurtosis value for the given normal distribution :", kurtosis(b, fisher=False))
print(
"Kurtosis value for the given normal distribution :",
kurtosis(b, fisher=True, bias=False),
)
Producción:
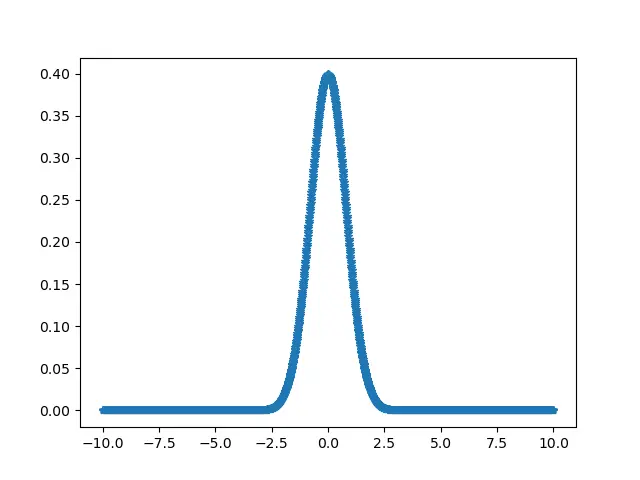
Kurtosis value for the given normal distribution : 3.399361267205304
Kurtosis value for the given normal distribution : 6.399361267205304
Kurtosis value for the given normal distribution : 3.4108810035523636

Lakshay Kapoor is a final year B.Tech Computer Science student at Amity University Noida. He is familiar with programming languages and their real-world applications (Python/R/C++). Deeply interested in the area of Data Sciences and Machine Learning.
LinkedIn