How to Implement Lasso Regression in Python
Regression, a statistical technique, determines the relationship between dependent and independent variables. We can use regression as an ML model for predictive analysis in Python.
Linear and logistic regression were the most common regression techniques. It has evolved, and now improved versions of regression have been introduced.
There can be some concerns regarding the accuracy of the technique.
It has been discussed and proved that the traditional regression techniques lead to a problem of overfitting when the number of independent variables increases, increasing the degree of the polynomial simultaneously.
Another vital factor for overfitting is noisy and inconsistent data, leading to inaccurate results.
Regularization was introduced to counter this problem. Lasso Regression is one such technique that uses regularization and variable selection in predictive analysis.
The Lasso Regression in Python
Lasso regression helps tackle situations with more irrelevant features in the dataset. We need to reduce the coefficient of these features to the least possible to nullify their effect on the prediction.
Lasso regression introduces a value in the cost function called the L1 penalty. During the gradient optimization process, weights of the irrelevant features are reduced to a minimum (almost 0) with the L1 penalty.
These shrunken weights are not considered in the function to remove their relevance.
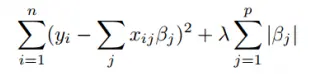
The mathematical equation of Lasso regression is shown in the above figure. Here, the value of λ is the shrinkage parameter determining the shrinkage amount.
A higher value means more bias and less variance. For λ = 0, all features are considered equivalent, and a value of infinity determines that no feature is considered.
The main concept of inducing the L1 penalty with the parameter is to decrease the weights of the feature when the parameter value increases.
Implement Lasso Regression in Python
We use the sklearn.linear_model.Lasso class to implement Lasso regression in Python. We can create a model using this class and use it with the required train and test data to make the predictions.
It takes the parameter alpha, the constant value that multiplies the L1 penalty. Other parameters like fit_intercept, normalize, precompute, copy_X, and more are also accepted in this object.
Let us implement an example of Lasso regression in Python.
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn import datasets
data = datasets.load_boston()
x_data = data.data
y_data = data.target
train_x, test_x, train_y, test_y = train_test_split(
x_data, y_data, test_size=0.3, random_state=42
)
lasso = Lasso(alpha=1.0)
lasso.fit(train_x, train_y)
print(lasso.score(test_x, test_y) * 100)
Output:
65.59060829154339
In the example above, we load a sample dataset from the sklearn module, and it is split into x_data and y_data. We use the train_test_split class to divide the dataset into train and test datasets.
We use the training dataset to train the Lasso regression model using the fit() function. Then, we check the score of the predicted data using the score() function.
The output shows that this model predicted the data with 65.59% accuracy.
We can perform cross-validation to find the optimal value for the alpha parameter of the Lasso model. This involves using techniques such as K-Fold Cross-Validation. For more details on the implementation of K-Fold, refer to our article on K-Fold Cross-Validation in Python.
We can import the sklearn.linear_model.LassoCV class. Then, we can specify the number of folds in the cross-validation technique.
See the code below.
from sklearn.linear_model import LassoCV
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn import datasets
data = datasets.load_boston()
x_data = data.data
y_data = data.target
train_x, test_x, train_y, test_y = train_test_split(
x_data, y_data, test_size=0.3, random_state=42
)
lassocv = LassoCV(cv=5, random_state=0, max_iter=10000)
lassocv.fit(train_x, train_y)
al = lassocv.alpha_
print(al)
lasso = Lasso(alpha=al)
lasso.fit(train_x, train_y)
print(lasso.score(test_x, test_y) * 100)
Output:
0.7051444556162024
67.48582731460068
In the above example, we find the optimal value for the alpha value, and then this value is used to train and test the previous model. The model’s accuracy with the new alpha value is 67.48%.

Manav is a IT Professional who has a lot of experience as a core developer in many live projects. He is an avid learner who enjoys learning new things and sharing his findings whenever possible.
LinkedIn