How to Find and Delete Duplicate Records in a Database in PostgreSQL
- PostgreSQL Database Schema
- PostgreSQL Database State
- Find Duplicate Records in PostgreSQL
- Delete Duplicate Records in PostgreSQL
- Conclusion

This article describes finding and deleting duplicate records in PostgreSQL using different commands.
Numerous queries can be written and used to look for duplicate records in the database. The same queries can then be tweaked to delete the duplicate records in the database.
Some of the queries are mentioned below to help you find duplicate records. Various alternative queries exist for the same purpose, so you can keep experimenting and finding new solutions.
PostgreSQL Database Schema
A schema designed below will be followed throughout the article to allow you to focus on the queries only. All the queries are designed according to the schema to understand the working of the queries better.
CREATE TABLE Student (
sid INT PRIMARY KEY,
sname VARCHAR (50),
sage INT,
semail VARCHAR(80)
);
PostgreSQL Database State
The following records are added to the Student table to populate them with records.
INSERT INTO Student VALUES (1, 'A', 15, 'a@gmail.com');
INSERT INTO Student VALUES (2, 'A', 17, 'ab@gmail.com');
INSERT INTO Student VALUES (3, 'B', 17, 'b@gmail.com');
INSERT INTO Student VALUES (4, 'AB', 21, 'ab@gmail.com');
The database schema and state clearly show that only the sid column in the table is unique; otherwise, all the columns can hold duplicate records.
The state of the Student table after successful insertion of all the records is shown below:
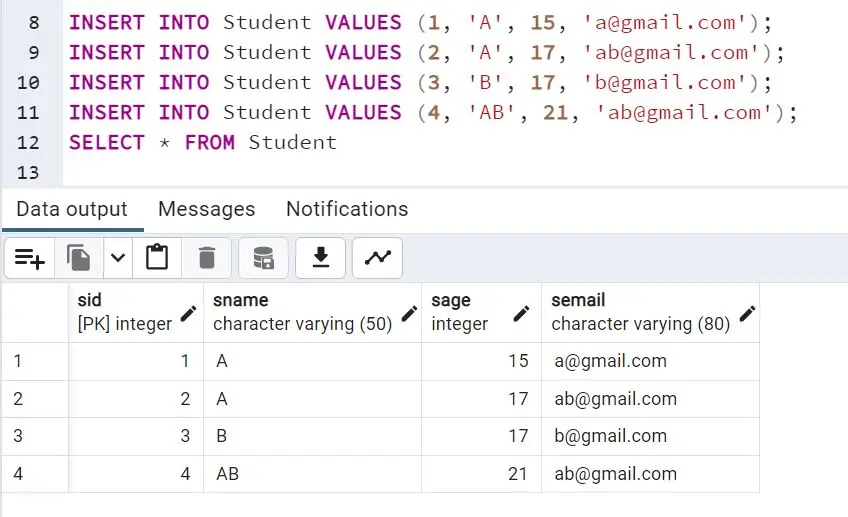
Duplicate values in sname, sage, and semail can be seen.
Find Duplicate Records in PostgreSQL
An error will be generated if you apply a unique constraint on a column that already contains duplicate records. Having different records to apply a unique constraint on that attribute later is essential.
There may be several other reasons to find duplicate records. You can write queries in PostgreSQL to filter out duplicate records.
Here are the following queries:
Query 1
A very basic query that can help you find duplicate records is as follows:
SELECT sname, count(*)
FROM Student
GROUP BY sname
HAVING count(*) >1
The query above is quite basic. It groups the data according to the sname column and displays the number of times it finds a student with the same name.
The query result is as follows:
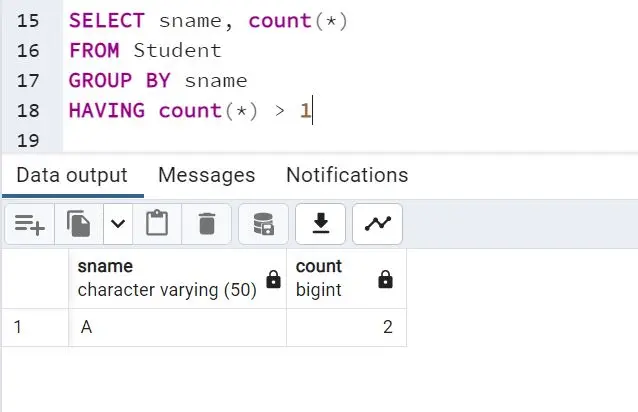
Note: If you wish to check duplicates in the
sagecolumn, replace it with thesnamecolumn in the query. In addition, if you wish to find a duplicate record with the same name and age, add both columns to the query.
Query 2
If you are well versed with nested queries, this might be an easy solution for you to check for duplicate values. It is a similar query to the one written above; however, it includes the concept of nested queries:
SELECT *
FROM Student ou
WHERE (
SELECT count(*)
FROM Student inr
WHERE inr.sname = ou.sname
) > 1
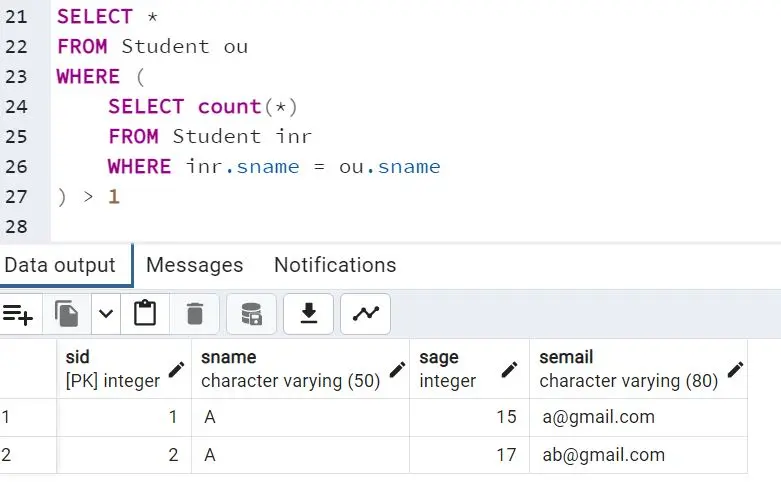
The query provides the same result as expected. It displays the entire record of the sname that has duplicate records.
If you want to find duplicate records in other attributes, you can replace the sname in the query above with the attribute of your choice.
The result generated from the query is as follows:
Query 3
To find entire duplicate records that have the same value in every attribute here is a simple query:
SELECT (Student.*)::text, count(*)
FROM Student
GROUP BY Student.*
HAVING count(*) > 1
The query above takes all the attributes. In this case, it will take sid, sname, sage, and semail and counts the number of times the same record is repeated with exact values in all attributes.
In this schema, the sid attribute is the primary key; hence, it does not allow for complete record duplication. Thus, the query generates no result:
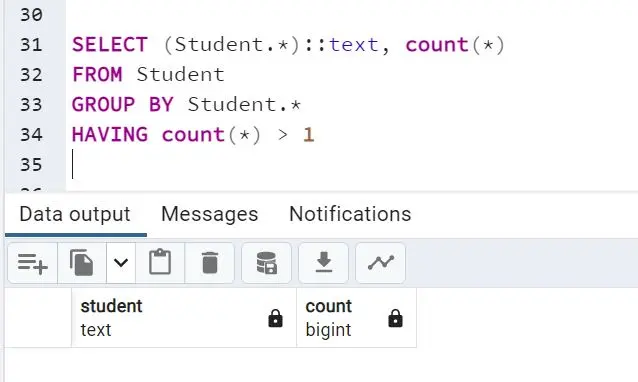
Query 4
Another query that can be used to find duplicate records in a specific table is mentioned below:
SELECT *
FROM (
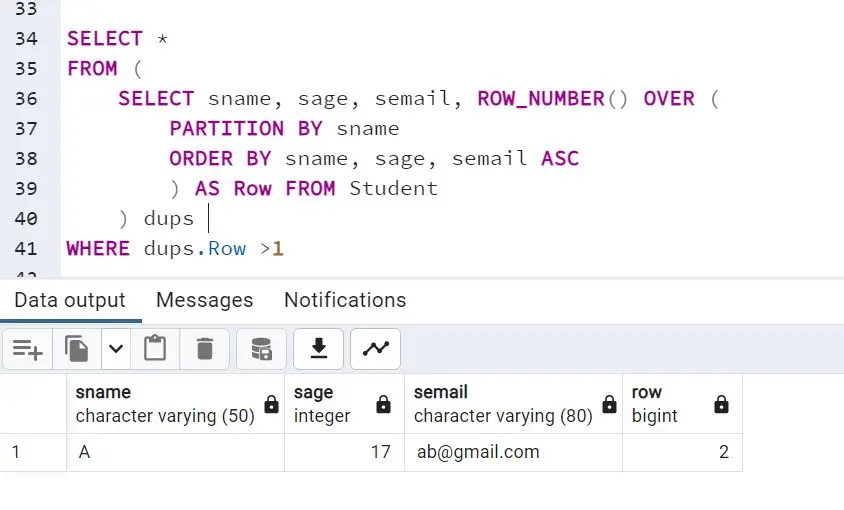
SELECT sname, sage, semail, ROW_NUMBER() OVER
(
PARTITION BY sname
ORDER BY sname, sage, semail ASC
) AS Row FROM Student
) dups
WHERE dups.Row >1
This is a nested query that finds duplicate rows and displays the sname, sage, and semail of the duplicate records. The query result is as follows:
Delete Duplicate Records in PostgreSQL
After finding the duplicate records, you might want to delete them from the table. Several queries can be used to delete duplicate records; however, this article includes one such query only.
Query 1
The four queries mentioned above can be used by tweaking to delete duplicate records. You can try and experiment with those queries yourself as an exercise.
We have included another query to delete the duplicate records from the table in this article.
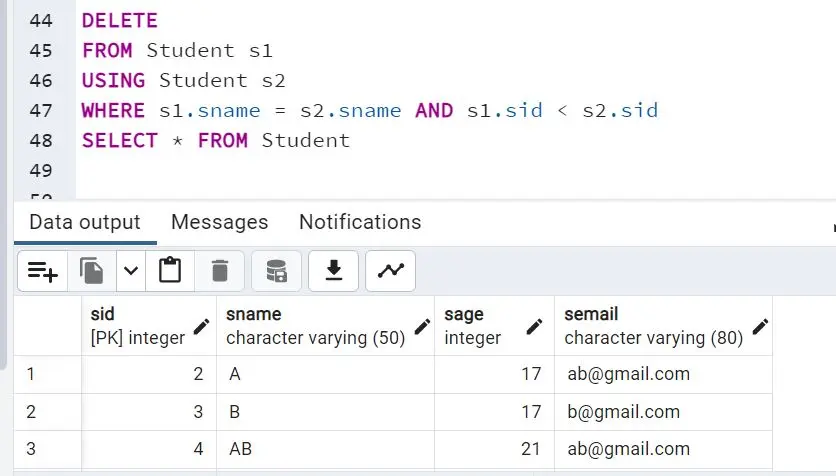
DELETE
FROM Student s1
USING Student s2
WHERE s1.sname = s2.sname AND s1.sid < s2.sid
The above query deletes one record from the Student table with the name A. The query deletes all the records except the latest one and generates a message of success.
The state of the table after deletion can be seen below:
Conclusion
Numerous queries can be used to find duplicate records in a database. Tweaking those queries can help you delete those records as well.
Keep experimenting with different queries to find the best one that suits your requirements.

Hello, I am Bilal, a research enthusiast who tends to break and make code from scratch. I dwell deep into the latest issues faced by the developer community and provide answers and different solutions. Apart from that, I am just another normal developer with a laptop, a mug of coffee, some biscuits and a thick spectacle!
GitHub