How to Scroll Down a Website Using Python Selenium
- Install Selenium and Chrome WebDriver
- Scroll Down a Website Using Python Selenium
- Scroll Browser to a Target Element Using Selenium in Python

Sometimes we may want to automate tasks in a browser, like scrolling on a website. Python has a powerful web automation tool known as Selenium.
It takes control of the web browser and allows us to perform specific actions automatically. We can write a script that automatically scrolls horizontally and vertically on a website.
Install Selenium and Chrome WebDriver
To install Selenium, we use the following command.
#Python 3.x
pip install selenium
ChromeDriver is another executable that Selenium WebDriver uses to interact with Chrome. If we want to automate tasks on the Chrome web browser, we also need to install ChromeDriver.
According to the version of the Chrome browser, we need to select a compatible driver for it. Following are the steps to install and configure the Chrome driver:
- Click on this link. Download Chrome driver according to the version of your Chrome browser and the type of operating system.
- If you want to find the version of your Chrome browser, click on the three dots on the top right corner of Chrome, click on Help, and select About Google Chrome. You can see the Chrome version in the about section.
- Extract the zip file and run the Chrome driver.
Scroll Down a Website Using Python Selenium
Syntax:
driver.execute_script("window.scrollBy(x_pixels, y_pixels);")
Here, the x_pixels indicate the number of pixels to scroll horizontally (on the x-axis), and the y_pixels refer to the number of pixels to scroll vertically (on the y axis). In this guide, we scroll only vertically so that the x_pixels will be 0.
Scroll Down by Specified Pixels
We created the WebDriver instance in the following code and specified the path to the Chrome driver. Then we have set the URL of the target website to the driver instance using the get() method.
It will open the target website in the desired browser. We have maximized Chrome’s window for a better picture using the maximize_window().
Selenium has the feature to execute JavaScript commands through the execute_script() method. We have automated scrolling down by 1000 pixels using the method window.scrollBy() and passed this command to the JavaScript executer.
The website will automatically scroll down vertically by 1000 pixels.
Example code:
# Python 3.x
from selenium import webdriver
driver = webdriver.Chrome(r"E:\download\chromedriver.exe")
driver.get("https://www.verywellmind.com/what-is-personality-testing-2795420")
driver.maximize_window()
driver.execute_script("window.scrollBy(0, 1000);")
Output:
![]()
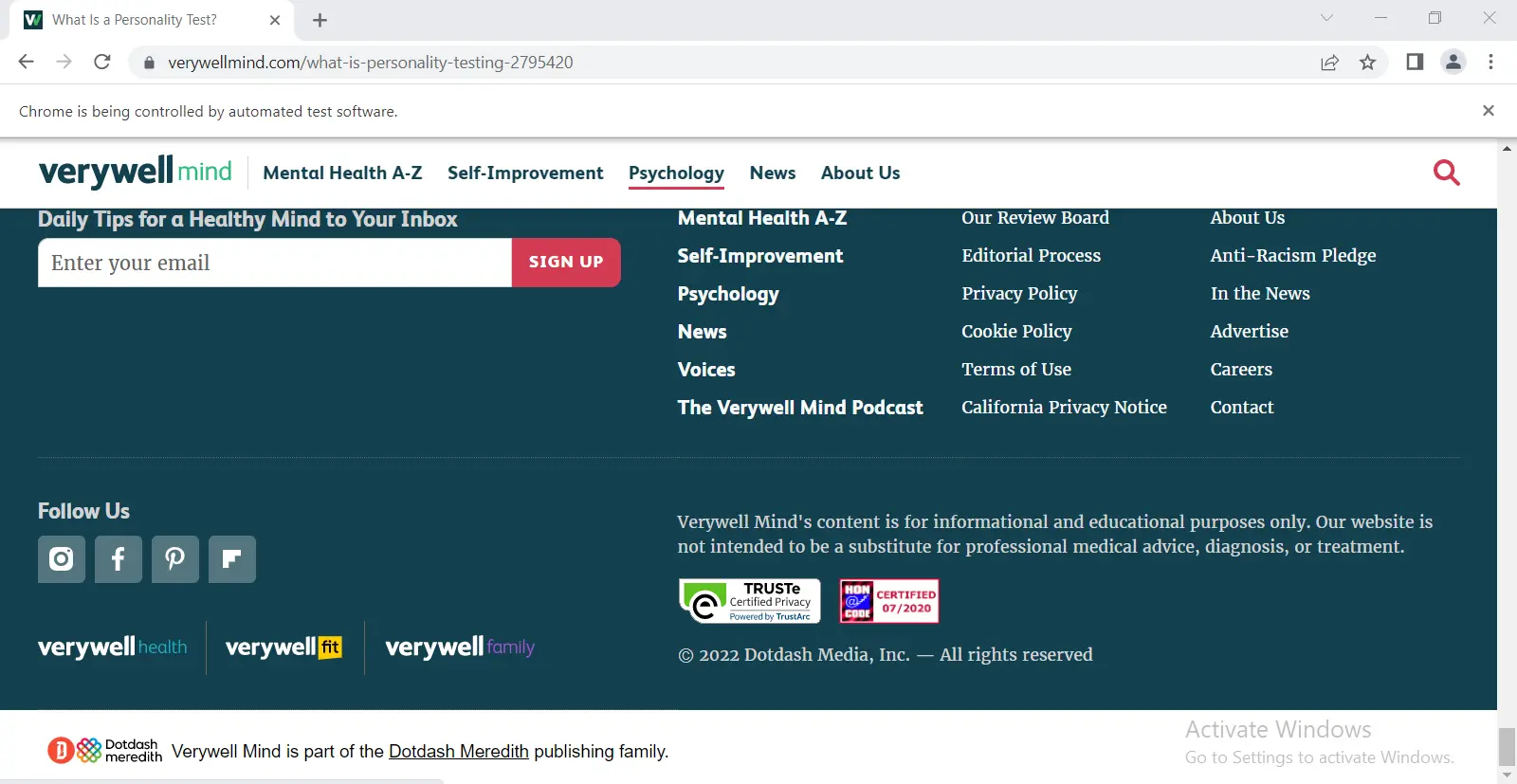
Scroll Down to the Bottom of the Website
Suppose we want to scroll down to the complete bottom of the page. The document.body.scrollHeight will give the total height of the page in pixels.
We will specify this height as the number of pixels to scroll down.
Example code:
# Python 3.x
from selenium import webdriver
driver = webdriver.Chrome(r"E:\download\chromedriver.exe")
driver.get("https://www.verywellmind.com/what-is-personality-testing-2795420")
driver.maximize_window()
driver.execute_script("window.scrollBy(0, document.body.scrollHeight);")
Output:
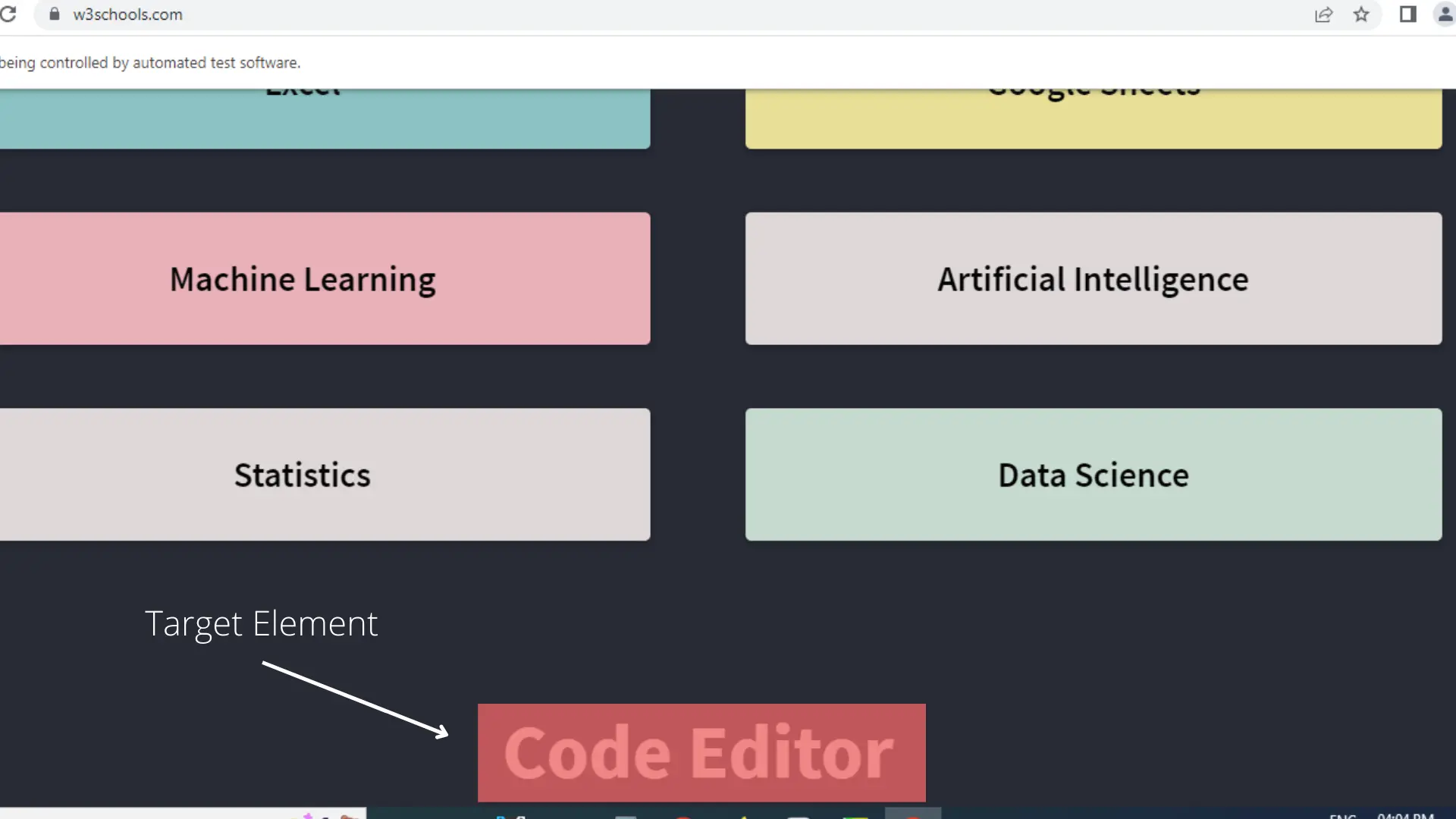
Scroll Browser to a Target Element Using Selenium in Python
This article section explains how to find an element in a webpage and scroll the browser up to it. Three things must be known to achieve this outcome.
- The URL of the webpage.
- The
XPathof the target element. - The average time it takes to load the page.
The URL of the webpage can be fetched from the search bar of any browser. If the target element is inside one of the subpages, then the subpage’s address must be given instead of the website’s home page.
XPath is a language that makes navigation easier inside web pages. Like every webpage has a URL, the elements inside the webpage have unique paths.
Fetch XPath of the Website
To fetch the XPath, go to the webpage, press F12, or right-click and choose inspect element. A panel will appear at the bottom of the browser.
A small icon of a black cursor over a square box appears on the top left-hand side of the panel.
Clicking on the icon puts the browser on an object selection mode, where hovering the cursor over the elements of the webpage will highlight it with blue color.
Clicking on an element inside object selection mode will display the HTML of that element. Right-click over the highlight HTML inside inspect panel, go to copy, and select copy XPath.
This will copy the XPath inside the clipboard.
Imports
The program requires two import packages - webdriver sub package of Selenium library and By sub package from selenium.webdriver.common.by library.
Import Driver and Fetching Target Element
This program requires chromedriver, which can be downloaded from here.
Unzip the downloaded package and copy the path of the .exe file inside the syntax parameters below.
driver = webdriver.Chrome()
The URL of the webpage needs to be put inside the parameters of syntax driver.get().
The syntax driver.find_element() searches for an element, while (By.XPATH, "your XPath") searches element for the given XPath. The XPath is put inside the double-quotes.
The contents from the XPath of the webpage get stored inside a variable el, while el.click executes a click command on the element to check its behavior.
time.sleep() puts a timeout that closes the browser when the process is finished or when no elements are found.
driver.quit releases the driver.
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(
"C:/Users/Win 10/Downloads/chromedriver_win32/chromedriver.exe"
)
driver.maximize_window()
driver.get("https://www.w3schools.com/")
el = driver.find_element(By.XPATH, "/html/body/div[5]/div[9]/div/h1")
el.click()
time.sleep(10)
driver.quit()
Output:

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedInRelated Article - Python Selenium
- How to Check if Element Exists Using Selenium Python
- How to Refresh Page in Python Selenium
- WebDriverException: Message: Geckodriver Executable Needs to Be in PATH Error in Python
- How to Install Python Selenium in macOS
- How to Login to a Website Using Selenium Python
- How to Open and Close Tabs in a Browser Using Selenium Python