Bigrams in Python
- Bigrams in Python
- Form Bigrams From a List of Words in Python
- Form Bigrams in Python Using the NLTK Library
- Advantages of Bigrams
- Disadvantages of Bigrams
- Conclusion
A pair of consecutive words in a text is called a bigram. These are commonly used in statistical language processing and are also used to identify the most common words in a text.
Bigrams can be used to find the most common words in a text and can also be used to generate new text. For example, the bigrams I like and like to can be used to create the sentence I like to eat.
Bigrams in Python
You can use the NLTK library to find bigrams in a text in Python. This library has a function called bigrams() that takes a list of words as input and returns a list of bigrams.
Bigrams can also be used to improve the accuracy of language models. Language models are used to predict the next word in a text, and bigrams can be used to increase the accuracy of these predictions.
So, what are bigrams suitable for? Bigrams can be used for various tasks, including finding the most common words in a text, generating new text, and improving the accuracy of language models.
Example Code:
ans = []
text = ["cant railway station", "citadel hotel", " police stn"]
for line in text:
arr = line.split()
for i in range(len(arr) - 1):
ans.append([[arr[i]], [arr[i + 1]]])
print(ans)
Output:
[[['cant'], ['railway']], [['railway'], ['station']], [['citadel'], ['hotel']], [['police'], ['stn']]]
Form Bigrams From a List of Words in Python
A bigram is used for a pair of words usually found together in a text. To form bigrams, we first need to tokenize the text into a list of words.
Then, we can iterate from the list, and for each word, check to see if the word before it is also in the list. If so, we add the two words to a bigram list.
These are the core steps to forming bigrams in Python.
-
To form bigrams, we need to make a vocabulary.
-
We need to get a list of sentences for our corpus.
-
At the end, we will create bigrams of all the words available in the corpus.
Bigrams can be helpful for language modeling, as they can give us a better idea of the likelihood of certain words appearing together. You can also use them for other tasks, such as spell checking and information retrieval.
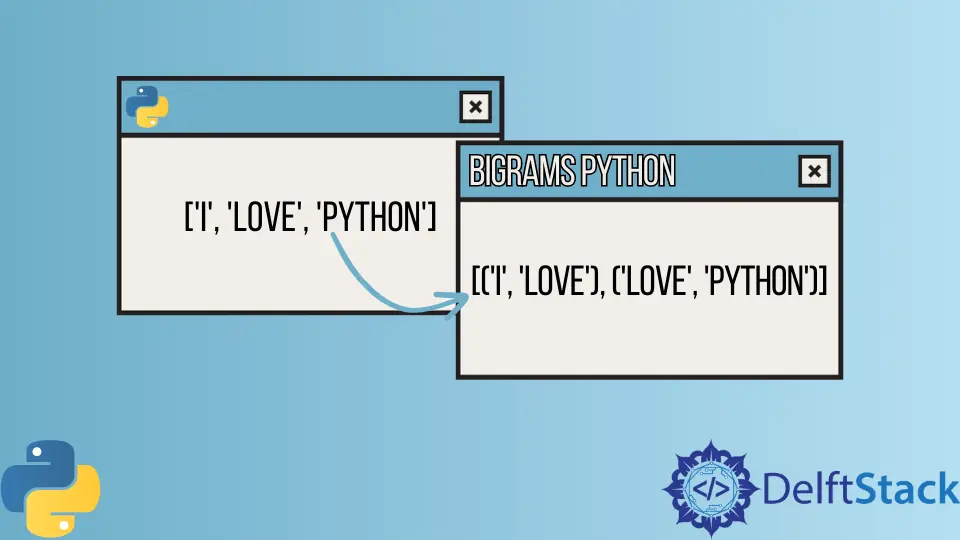
Python provides a simple way to form bigrams from a list of words. The bigrams() function will accept a list of words and return a list of bigrams; each bigram is a tuple of two words.
For example, if we have a list of words ['I', 'love', 'python'], the bigrams() function will return [('I', 'love'), ('love', 'python')].
Example Code:
text = ["this is a sentence", "so is this one"]
bigrams = [b for l in text for b in zip(l.split(" ")[:-1], l.split(" ")[1:])]
print(bigrams)
Output:
[('this', 'is'), ('is', 'a'), ('a', 'sentence'), ('so', 'is'), ('is', 'this'), ('this', 'one')]
Form Bigrams in Python Using the NLTK Library
The code below shows how to use the NLTK library to form bigrams from a list of words. NLTK is a popular library for natural language processing in Python.
Example Code:
import nltk
words = ["please", "turn", "off", "the", "light"]
bigrams = nltk.bigrams(words)
for bigram in bigrams:
print(bigram)
Output:
('please', 'turn')
('turn', 'off')
('off', 'the')
('the', 'light')
Advantages of Bigrams
There are some significant advantages to using bigrams when analyzing text data.
- First, bigrams can help to identify words that are often used together, which can help understand the overall meaning of a text.
- Additionally, bigrams can create more accurate models for predictive tasks such as text classification.
- Finally, bigrams can also help to reduce the dimensionality of data, which can be helpful when working with large text corpora.
Disadvantages of Bigrams
While bigrams can be helpful in some situations, they also have disadvantages.
- One downside is that they can be more difficult to compute than other methods, such as unigrams.
- Bigrams can sometimes produce less accurate results than other methods.
- Finally, bigrams can be more difficult to interpret than other methods, making it more difficult to understand what the results mean.
Conclusion
Bigrams and trigrams can capture the co-occurrence and co-location patterns of words in a text. For example, the bigram red wine is likely to appear in a text about wine, while the trigram the red wine is likely to appear in a text about wine tasting.
These patterns can help identify a text’s topic or generate new text similar to a given text.

Zeeshan is a detail oriented software engineer that helps companies and individuals make their lives and easier with software solutions.
LinkedInRelated Article - Python List
- How to Convert a Dictionary to a List in Python
- How to Remove All the Occurrences of an Element From a List in Python
- How to Remove Duplicates From List in Python
- How to Get the Average of a List in Python
- What Is the Difference Between List Methods Append and Extend
- How to Convert a List to String in Python