バイグラムパイソン
- Python のバイグラム
- Python で単語のリストからバイグラムを形成する
- NLTK ライブラリを使用して Python でバイグラムを形成する
- バイグラムの利点
- バイグラムのデメリット
- まとめ
テキスト内の連続した単語のペアはバイグラムと呼ばれます。 これらは統計的言語処理で一般的に使用され、テキスト内で最も一般的な単語を識別するためにも使用されます。
バイグラムは、テキスト内で最も一般的な単語を見つけるために使用でき、新しいテキストを生成するためにも使用できます。 たとえば、バイグラム I like と like to を使用して、I like to eat という文を作成できます。
Python のバイグラム
NLTK ライブラリを使用して、Python でテキスト内のバイグラムを見つけることができます。 このライブラリには bigrams() という関数があり、入力として単語のリストを受け取り、バイグラムのリストを返します。
バイグラムは、言語モデルの精度を向上させるためにも使用できます。 言語モデルを使用してテキスト内の次の単語を予測し、バイグラムを使用してこれらの予測の精度を高めることができます。
では、バイグラムは何に適しているのでしょうか? バイグラムは、テキスト内の最も一般的な単語の検索、新しいテキストの生成、言語モデルの精度の向上など、さまざまなタスクに使用できます。
コード例:
ans = []
text = ["cant railway station", "citadel hotel", " police stn"]
for line in text:
arr = line.split()
for i in range(len(arr) - 1):
ans.append([[arr[i]], [arr[i + 1]]])
print(ans)
出力:
[[['cant'], ['railway']], [['railway'], ['station']], [['citadel'], ['hotel']], [['police'], ['stn']]]
Python で単語のリストからバイグラムを形成する
バイグラムは、テキスト内で通常一緒に使用される単語のペアに使用されます。 バイグラムを形成するには、まずテキストを単語のリストにトークン化する必要があります。
次に、リストから繰り返し、単語ごとに、その前の単語もリストに含まれているかどうかを確認します。 その場合、2つの単語をバイグラム リストに追加します。
これらは、Python でバイグラムを形成するための主要な手順です。
-
バイグラムを形成するには、語彙を作成する必要があります。
-
コーパスの文のリストを取得する必要があります。
-
最後に、コーパスで利用可能なすべての単語のバイグラムを作成します。
バイグラムは、特定の単語が一緒に出現する可能性をより正確に把握できるため、言語モデリングに役立ちます。 また、スペル チェックや情報検索など、他のタスクにも使用できます。
Python は、単語のリストからバイグラムを作成する簡単な方法を提供します。 bigrams() 関数は、単語のリストを受け取り、バイグラムのリストを返します。 各バイグラムは 2つの単語のタプルです。
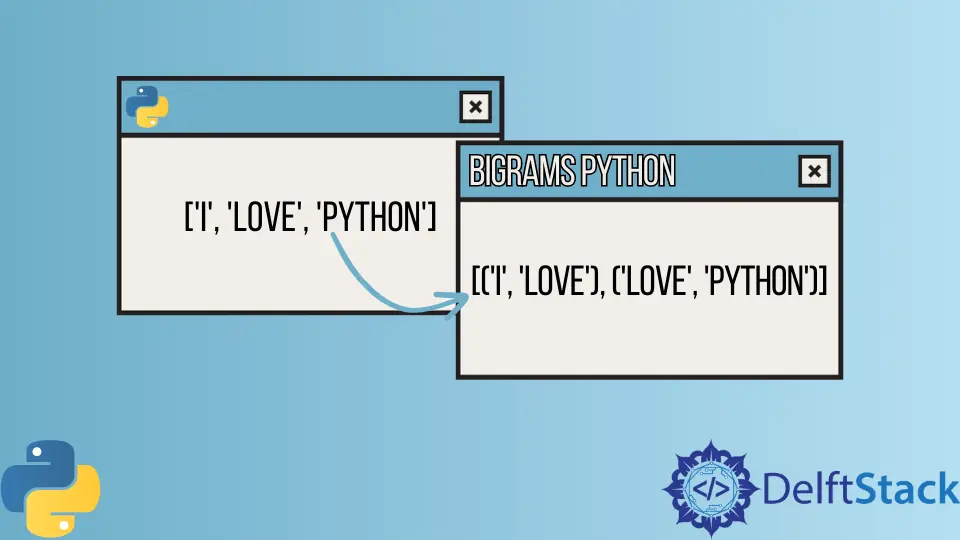
たとえば、['I', 'love', 'python'] という単語のリストがある場合、bigrams() 関数は [('I', 'love'), ('love', 'python')].
コード例:
text = ["this is a sentence", "so is this one"]
bigrams = [b for l in text for b in zip(l.split(" ")[:-1], l.split(" ")[1:])]
print(bigrams)
出力:
[('this', 'is'), ('is', 'a'), ('a', 'sentence'), ('so', 'is'), ('is', 'this'), ('this', 'one')]
NLTK ライブラリを使用して Python でバイグラムを形成する
以下のコードは、NLTK ライブラリを使用して、単語のリストからバイグラムを形成する方法を示しています。 NLTK は、Python で自然言語処理を行うための一般的なライブラリです。
コード例:
import nltk
words = ["please", "turn", "off", "the", "light"]
bigrams = nltk.bigrams(words)
for bigram in bigrams:
print(bigram)
出力:
('please', 'turn')
('turn', 'off')
('off', 'the')
('the', 'light')
バイグラムの利点
テキストデータを分析するときにバイグラムを使用すると、いくつかの大きな利点があります。
- まず、バイグラムは、一緒に使用されることが多い単語を識別するのに役立ち、テキストの全体的な意味を理解するのに役立ちます。
- さらに、バイグラムは、テキスト分類などの予測タスク用のより正確なモデルを作成できます。
- 最後に、バイグラムはデータの次元を削減するのにも役立ちます。これは、大きなテキスト コーパスを扱う場合に役立ちます。
バイグラムのデメリット
バイグラムは状況によっては役立つ場合もありますが、欠点もあります。
- 1つの欠点は、ユニグラムなどの他の方法よりも計算が難しいことです。
- バイグラムは、他の方法よりも精度の低い結果を生成する場合があります。
- 最後に、バイグラムは他の方法よりも解釈が難しく、結果の意味を理解するのが難しくなります。
まとめ
バイグラムとトライグラムは、テキスト内の単語の共起パターンと共起パターンをキャプチャできます。 たとえば、バイグラム 赤ワイン はワインに関するテキストに表示される可能性が高く、トリグラム 赤ワイン はワインのテイスティングに関するテキストに表示される可能性が高い.
これらのパターンは、テキストのトピックを識別したり、特定のテキストに類似した新しいテキストを生成したりするのに役立ちます。

Zeeshan is a detail oriented software engineer that helps companies and individuals make their lives and easier with software solutions.
LinkedIn