How to Select Random Rows in PostgreSQL
-
a Basic Implementation Using
Random()for Row Selection in PostgreSQL - Random Rows Selection for Bigger Tables in PostgreSQL
-
Use
OFFSET FLOORto Random Sample aTABLEin PostgreSQL -
Use
RANDOMonOIDto Get Rows From a Table in PostgreSQL

Today in PostgreSQL, we will learn to select random rows from a table. You must have guessed from the name that this would tend to work on returning random, unplanned rows or uncalled for.
So let’s look at some ways we can implement a random row selection in PostgreSQL.
a Basic Implementation Using Random() for Row Selection in PostgreSQL
RANDOM() tends to be a function that returns a random value in the range defined; 0.0 <= x < 1.0. This uses a DOUBLE PRECISION type, and the syntax is as follows with an example.
random ( ) → double precision
random() → 0.897124072839091 - (example)
Now we can use this RANDOM() function to get unique and arbitrary values. So if we want to query, let’s say, a SELECT operation for data sets from a table only if the RANDOM() value tends to be somewhere around 0.05, then we can be sure that there will be different results obtained each time.
We can prove this by querying something as follows.
select * from DOGGY where random() <= 0.02
We have used the DOGGY table, which contains a set of TAGS and OWNER_IDs. So what happens if we run the above?
Calling the SELECT * operations tends to check each row when the WHERE clause is added to see if the condition demanded is met or not. In other words, it will check the TABLE for data where the RANDOM() value is less than or equal to 0.02.
So each time it receives a row from the TABLE under SELECT, it will call the RANDOM() function, receive a unique number, and if that number is less than the pre-defined value (0.02), it will return that ROW in our final result.
Else, that row will be skipped, and the succeeding rows will be checked. This tends to be the simplest method of querying random rows from the PostgreSQL table.
Similar Manipulations to the SELECT Query for Random Rows
One other very easy method that can be used to get entirely random rows is to use the ORDER BY clause rather than the WHERE clause. ORDER BY will sort the table with a condition defined in the clause in that scenario.
If that is the case, we can sort by a RANDOM value each time to get a certain set of desired results.
select * from DOGGY order by random();
Processing the above would return different results each time. Below are two output results of querying this on the DOGGY table.
Output 1:
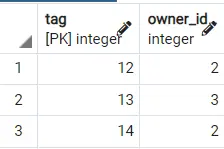
Output 2:
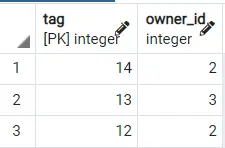
Hence we can see how different results are obtained. To make it even better, you can use the LIMIT [NUMBER] clause to get the first 2,3 etc., rows from this randomly sorted table, which we desire.
Querying something as follows will work just fine.
select * from DOGGY order by random() limit 2;
Short Note on Best Method Amongst the Above for Random Row Selection:
The second method using the ORDER BY clause tends to be much better than the former. Because in many cases, RANDOM() may tend to provide a value that may not be less or more than a pre-defined number or meet a certain condition for any row.
This may, in the end, lead to incorrect results or even an empty table. And hence, the latter wins in this case.
Ordered rows may be the same in different conditions, but there will never be an empty result.
Random Rows Selection for Bigger Tables in PostgreSQL
Efficient and immediate results tend to be much better when considering queries. Many tables may have more than a million rows, and the larger the amount of data, the greater the time needed to query something from the table.
We look at solutions to reduce overhead and provide faster speeds in such a scenario. To begin with, we’ll use the same table, DOGGY and present different ways to reduce overheads, after which we will move to the main RANDOM selection methodology.
One of the ways to reduce overheads is to estimate the important data inside a table much earlier rather than waiting for the execution of the main query and then using this.
PostgreSQL tends to have very slow COUNT operations for larger data. Why?
If let’s say that in a table of 5 million, you were to add each row and then count it, with 5 seconds for 1 million rows, you’d end up consuming 25 seconds just for the COUNT to complete. One of the ways to get the count rather than calling COUNT(*) is to use something known as RELTUPLE.
RELTUPLE tends to estimate the data present in a table after being ANALYZED. We can go ahead and run something as follows.
analyze doggy;
select reltuples as estimate from pg_class where relname = 'doggy';
You can then check the results and notice that the value obtained from this query is the same as the one obtained from COUNT. Let’s generate some RANDOM numbers for our data.
We will follow a simple process for a large table to be more efficient and reduce large overheads.
- Not allowing duplicate random values to be generated
- Removing excess results in the final table
- Using
JOINto fasten our random table result
A query such as the following will work nicely.
SELECT (r.tag::int / random())::int as x
FROM (
SELECT Distinct * from generate_series(6, 7) as tag limit 1
) r
JOIN DOGGY USING (tag)
This will return us a table from DOGGY with values that match the random value R.TAG received from the calculation. Using the LIMIT 1 in the SUB-QUERY tends to get a single random number to join our DOGGY table.
Of course, this is for testing purposes. You may go ahead and manipulate this to some other number.
LIMIT 2 or 3 would be nice, considering that DOGGY contains 3 rows. This serves as a much better solution and is faster than its predecessors.
One of the ways we can remove duplicate values inside a table is to use UNION. We can result in all the unique and different elements by repeating the same query and making a UNION with the previous one.
So if we’re to do something like this:
SELECT (r.tag::int / random())::int as x
FROM (
SELECT Distinct * from generate_series(6, 7) as tag limit 1
) r
JOIN DOGGY USING (tag)
union
SELECT (r.tag::int / random())::int as x
FROM (
SELECT Distinct * from generate_series(5, 6) as tag limit 1
) r
JOIN DOGGY USING (tag)
We will get a final result with all different values and lesser gaps. We mean values not in order but are missing and not included by gaps.
Gaps can tend to create inefficient results. And hence must be avoided at all costs.
Similarly, we can create a function from this query that tends to take a TABLE and values for the RANDOM SELECTION as parameters. Once ingrained into our database session, many users can easily re-use this function later.
Let us now go ahead and write a function that can handle this.
CREATE OR REPLACE FUNCTION random_func(limite int, limite_sup int)
RETURNS table (val int, val2 int)
LANGUAGE plpgsql VOLATILE ROWS 3 AS
$$
BEGIN
RETURN QUERY SELECT *
FROM (
SELECT Distinct * from generate_series(limite, limite_sup) as tag limit 1
) r
JOIN DOGGY USING (tag)
UNION
SELECT *
FROM (
SELECT Distinct * from generate_series(limite, limite_sup) as tag limit 1
) r
JOIN DOGGY USING (tag);
END
$$
This function works in the same way as you expect it to. It executes the UNION query and returns a TABLE with the LIMIT provided in our parameter.
To get our random selection, we can call this function as follows.
SELECT * FROM random_func(6, 7);
Once again, you will notice how sometimes the query won’t return any values but rather remain stuck because RANDOM often won’t be a number from the range defined in the FUNCTION.
Rather unwanted values may be returned, and there would be no similar values present in the table, leading to empty results.
MATERIALIZED VIEWS can be used rather than TABLES to generate better results. It remembers the query used to initialize it and then refreshes it later.
This REFRESH will also tend to return new values for RANDOM at a better speed and can be used effectively.
Discouraged Method for Random Sampling of a Table in PostgreSQL
Another brilliant method to get random rows from a table could have been the TABLESAMPLE method defined under the PostgreSQL documentation’s SELECT (FROM) section.
Syntax:
TABLESAMPLE sampling_method ( argument [, ...] ) [ REPEATABLE ( seed ) ]
Where the argument is the percentage of the table you want to return, this subset of the table returned is entirely random and varies. However, in most cases, the results are just ordered or original versions of the table and return consistently the same tables.
Running a query such as follows on DOGGY would return varying but consistent results for maybe the first few executions.
On a short note, TABLESAMPLE can have two different sampling_methods; BERNOULLI and SYSTEM. We will use SYSTEM first.
select * from DOGGY tablesample system (30);
Here are the results for the first 3 iterations using SYSTEM.

You can notice that the results are not what we expect but give the wrong subsets. Our short data table DOGGY uses BERNOULLI rather than SYSTEM; however, it tends to exactly do what we desire.
select * from DOGGY tablesample bernoulli (30);
Here are the results for the first 3 iterations using BERNOULLI.
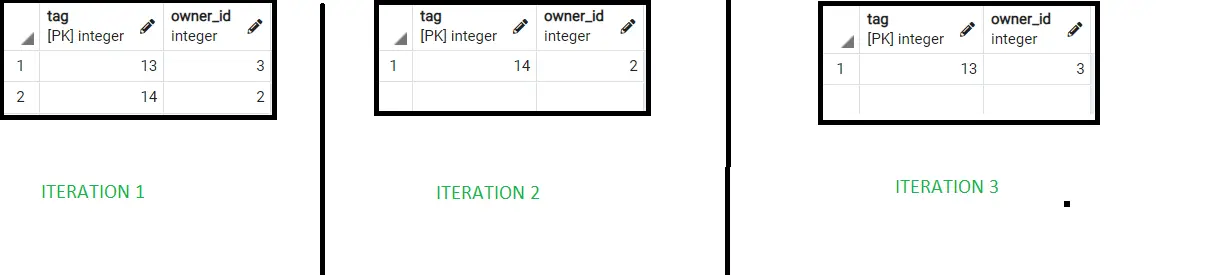
Hence, we can see that different random results are obtained correctly using the percentage passed in the argument.
What makes SYSTEM and BERNOULLI so different is that BERNOULLI ignores results that are bound outside the specified argument while SYSTEM just randomly returns a BLOCK of table which will contain all rows, hence the less random samples in SYSTEM.
You can even define a seed for your SAMPLING query, such as follows, for a much different random sampling than when none is provided.
select * from DOGGY tablesample bernoulli (30) repeatable (1);
An extension of TSM_SYSTEM_ROWS may also be able to achieve random samples if somehow it ends up clustering. You would need to add the extension first and then use it.
CREATE EXTENSION tsm_system_rows;
select * from DOGGY tablesample system_rows(1);
However, it depends on the system. In 90% of cases, there will be no random sampling, but there is still a little chance of getting random values if somehow clustering effects take place, that is, a random selection of partitioned blocks from a population which in our case will be the table.
Due to its ineffectiveness, it is discouraged as well.
Use OFFSET FLOOR to Random Sample a TABLE in PostgreSQL
A query that you can use to get random rows from a table is presented as follows.
select * from DOGGY OFFSET floor(random() * 3) LIMIT 1;
OFFSET means skipping rows before returning a subset from the table. So if we have a RANDOM() value of 0.834, this multiplied by 3 would return 2.502.
The FLOOR of 2.502 is 2, and the OFFSET of 2 would return the last row of the table DOGGY starting from row number 3. LIMIT tends to return one row from the subset obtained by defining the OFFSET number.
Use RANDOM on OID to Get Rows From a Table in PostgreSQL
select * from DOGGY
where tag > floor((
select (
select reltuples::bigint AS estimate
from pg_class
where oid = 'public.DOGGY'::regclass) * random()
))
order by tag asc limit(1);
So what does this query do? In our case, the above query estimates the row count with a random number multiplied by the ROW ESTIMATE, and the rows with a TAG value greater than the calculated value are returned.
It is simple yet effective. Using FLOOR will return the floor value of decimal and then use it to obtain the rows from the DOGGY table.
We hope you have now understood the different approaches we can take to find the random rows from a table in PostgreSQL.

Hello, I am Bilal, a research enthusiast who tends to break and make code from scratch. I dwell deep into the latest issues faced by the developer community and provide answers and different solutions. Apart from that, I am just another normal developer with a laptop, a mug of coffee, some biscuits and a thick spectacle!
GitHub