Seleccionar filas aleatorias en PostgreSQL
-
una implementación básica utilizando
Random()para la selección de filas en PostgreSQL - Selección de filas aleatorias para tablas más grandes en PostgreSQL
-
Use
OFFSET FLOORpara una muestra aleatoria de unaTABLAen PostgreSQL -
Use
RANDOMenOIDpara obtener filas de una tabla en PostgreSQL

Hoy en PostgreSQL, aprenderemos a seleccionar filas aleatorias de una tabla. Debe haber adivinado por el nombre que esto tendería a funcionar al devolver filas aleatorias, no planificadas o no solicitadas.
Entonces, veamos algunas formas en que podemos implementar una selección de fila aleatoria en PostgreSQL.
una implementación básica utilizando Random() para la selección de filas en PostgreSQL
RANDOM() tiende a ser una función que devuelve un valor aleatorio en el rango definido; 0.0 <= x < 1.0. Esto usa un tipo DOUBLE PRECISION, y la sintaxis es la siguiente con un ejemplo.
random ( ) → double precision
random() → 0.897124072839091 - (example)
Ahora podemos usar esta función RANDOM() para obtener valores únicos y arbitrarios. Entonces, si queremos consultar, digamos, una operación SELECCIONAR para conjuntos de datos de una tabla solo si el valor ALEATORIO() tiende a estar alrededor de 0.05, entonces podemos estar seguros de que habrá diferentes resultados. obtenido cada vez.
Podemos probar esto consultando algo de la siguiente manera.
select * from DOGGY where random() <= 0.02
Hemos utilizado la tabla DOGGY, que contiene un conjunto de TAGS y OWNER_IDs. Entonces, ¿qué sucede si ejecutamos lo anterior?
Llamar a las operaciones SELECT * tiende a verificar cada fila cuando se agrega la cláusula WHERE para ver si se cumple o no la condición exigida. En otras palabras, comprobará la TABLA en busca de datos donde el valor RANDOM() sea menor o igual a 0.02.
Entonces, cada vez que recibe una fila de la TABLA en SELECCIONAR, llamará a la función ALEATORIO(), recibirá un número único, y si ese número es menor que el valor predefinido (0.02) , devolverá esa ROW en nuestro resultado final.
De lo contrario, se omitirá esa fila y se verificarán las filas siguientes. Este tiende a ser el método más simple para consultar filas aleatorias de la tabla de PostgreSQL.
Manipulaciones similares a la consulta SELECT para filas aleatorias
Otro método muy fácil que se puede usar para obtener filas completamente aleatorias es usar la cláusula ORDER BY en lugar de la cláusula WHERE. ORDER BY ordenará la tabla con una condición definida en la cláusula en ese escenario.
Si ese es el caso, podemos ordenar por un valor ALEATORIO cada vez para obtener un determinado conjunto de resultados deseados.
select * from DOGGY order by random();
Procesar lo anterior arrojaría resultados diferentes cada vez. A continuación se muestran dos resultados de salida de consultar esto en la tabla DOGGY.
Salida 1:
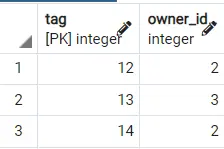
Salida 2:
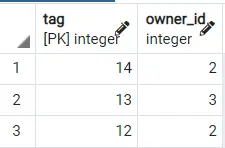
De ahí que podamos ver cómo se obtienen diferentes resultados. Para hacerlo aún mejor, puede usar la cláusula LIMIT [NÚMERO] para obtener las primeras filas 2,3, etc., de esta tabla ordenada aleatoriamente, lo que deseamos.
Consultar algo de la siguiente manera funcionará bien.
select * from DOGGY order by random() limit 2;
Breve nota sobre el mejor método entre los anteriores para la selección aleatoria de filas:
El segundo método que usa la cláusula ORDER BY tiende a ser mucho mejor que el anterior. Porque en muchos casos, RANDOM() puede tender a proporcionar un valor que no puede ser mayor o menor que un número predefinido o cumplir una determinada condición para cualquier fila.
Esto puede, al final, conducir a resultados incorrectos o incluso a una tabla vacía. Y por lo tanto, este último gana en este caso.
Las filas ordenadas pueden ser iguales en diferentes condiciones, pero nunca habrá un resultado vacío.
Selección de filas aleatorias para tablas más grandes en PostgreSQL
Los resultados eficientes e inmediatos tienden a ser mucho mejores cuando se consideran consultas. Muchas tablas pueden tener más de un millón de filas y cuanto mayor sea la cantidad de datos, mayor será el tiempo necesario para consultar algo de la tabla.
Buscamos soluciones para reducir los gastos generales y proporcionar velocidades más rápidas en tal escenario. Para empezar, usaremos la misma tabla, DOGGY y presentaremos diferentes formas de reducir los gastos generales, después de lo cual pasaremos a la metodología de selección principal RANDOM.
Una de las formas de reducir los gastos generales es estimar los datos importantes dentro de una tabla mucho antes en lugar de esperar la ejecución de la consulta principal y luego usarla.
PostgreSQL tiende a tener operaciones COUNT muy lentas para datos más grandes. ¿Por qué?
Si digamos que en una tabla de 5 millones, agregaras cada fila y luego la contaras, con 5 segundos para 1 millón de filas, terminarías consumiendo 25 segundos solo para el CONTADOR completar. Una de las formas de obtener el conteo en lugar de llamar a COUNT(*) es usar algo conocido como RELTUPLE.
RELTUPLE tiende a estimar los datos presentes en una tabla después de haber sido ANALIZADA. Podemos seguir adelante y ejecutar algo de la siguiente manera.
analyze doggy;
select reltuples as estimate from pg_class where relname = 'doggy';
Luego puede verificar los resultados y notar que el valor obtenido de esta consulta es el mismo que el obtenido de COUNT. Generemos algunos números ALEATORIOS para nuestros datos.
Seguiremos un proceso simple para que una mesa grande sea más eficiente y reduzca los grandes gastos generales.
- No permitir que se generen valores aleatorios duplicados
- Eliminar el exceso de resultados en la mesa final
- Usando
JOINpara ajustar el resultado de nuestra tabla aleatoria
Una consulta como la siguiente funcionará bien.
SELECT (r.tag::int / random())::int as x
FROM (
SELECT Distinct * from generate_series(6, 7) as tag limit 1
) r
JOIN DOGGY USING (tag)
Esto nos devolverá una tabla de DOGGY con valores que coinciden con el valor aleatorio R.TAG recibido del cálculo. El uso de LIMIT 1 en la SUB-QUERY tiende a obtener un solo número aleatorio para unirse a nuestra tabla DOGGY.
Por supuesto, esto es para fines de prueba. Puede seguir adelante y manipular esto a algún otro número.
LIMIT 2 o 3 estaría bien, considerando que DOGGY contiene 3 filas. Esto sirve como una solución mucho mejor y es más rápido que sus predecesores.
Una de las formas en que podemos eliminar valores duplicados dentro de una tabla es usar UNION. Podemos dar como resultado todos los elementos únicos y diferentes repitiendo la misma consulta y haciendo una UNION con la anterior.
Así que si vamos a hacer algo como esto:
SELECT (r.tag::int / random())::int as x
FROM (
SELECT Distinct * from generate_series(6, 7) as tag limit 1
) r
JOIN DOGGY USING (tag)
union
SELECT (r.tag::int / random())::int as x
FROM (
SELECT Distinct * from generate_series(5, 6) as tag limit 1
) r
JOIN DOGGY USING (tag)
Obtendremos un resultado final con todos los valores diferentes y menos espacios. Nos referimos a valores que no están en orden pero que faltan y no están incluidos en los espacios.
Las brechas pueden tender a crear resultados ineficientes. Y por lo tanto debe evitarse a toda costa.
Del mismo modo, podemos crear una función a partir de esta consulta que tiende a tomar una TABLA y valores para la SELECCIÓN ALEATORIA como parámetros. Una vez integrada en nuestra sesión de base de datos, muchos usuarios pueden reutilizar fácilmente esta función más adelante.
Avancemos ahora y escribamos una función que pueda manejar esto.
CREATE OR REPLACE FUNCTION random_func(limite int, limite_sup int)
RETURNS table (val int, val2 int)
LANGUAGE plpgsql VOLATILE ROWS 3 AS
$$
BEGIN
RETURN QUERY SELECT *
FROM (
SELECT Distinct * from generate_series(limite, limite_sup) as tag limit 1
) r
JOIN DOGGY USING (tag)
UNION
SELECT *
FROM (
SELECT Distinct * from generate_series(limite, limite_sup) as tag limit 1
) r
JOIN DOGGY USING (tag);
END
$$
Esta función funciona de la misma manera que esperas. Ejecuta la consulta UNION y devuelve una TABLA con el LÍMITE proporcionado en nuestro parámetro.
Para obtener nuestra selección aleatoria, podemos llamar a esta función de la siguiente manera.
SELECT * FROM random_func(6, 7);
Una vez más, notará cómo a veces la consulta no devuelve ningún valor, sino que permanece bloqueada porque ALEATORIO a menudo no será un número del rango definido en la FUNCIÓN.
Es posible que se devuelvan valores no deseados, y no habría valores similares presentes en la tabla, lo que daría lugar a resultados vacíos.
Se pueden usar VISTAS MATERIALIZADAS en lugar de TABLAS para generar mejores resultados. Recuerda la consulta utilizada para inicializarlo y luego lo actualiza más tarde.
Este REFRESH también tenderá a devolver nuevos valores para RANDOM a una mejor velocidad y se puede usar de manera efectiva.
Método desaconsejado para el muestreo aleatorio de una tabla en PostgreSQL
Otro método brillante para obtener filas aleatorias de una tabla podría haber sido el método TABLESAMPLE definido en la sección SELECT (FROM) de la documentación de PostgreSQL.
Sintaxis:
TABLESAMPLE sampling_method ( argument [, ...] ) [ REPEATABLE ( seed ) ]
Donde el argumento es el porcentaje de la tabla que desea devolver, este subconjunto de la tabla devuelta es completamente aleatorio y varía. Sin embargo, en la mayoría de los casos, los resultados son solo versiones ordenadas o originales de la tabla y devuelven consistentemente las mismas tablas.
Ejecutar una consulta como la siguiente en DOGGY arrojaría resultados variables pero consistentes para quizás las primeras ejecuciones.
En pocas palabras, TABLESAMPLE puede tener dos sampling_methods diferentes; BERNOULLI y SISTEMA. Usaremos SISTEMA primero.
select * from DOGGY tablesample system (30);
Aquí están los resultados de las primeras 3 iteraciones usando SISTEMA.

Puede notar que los resultados no son lo que esperábamos, sino que dan los subconjuntos incorrectos. Nuestra tabla corta de datos DOGGY utiliza BERNOULLI en lugar de SYSTEM; sin embargo, tiende a hacer exactamente lo que deseamos.
select * from DOGGY tablesample bernoulli (30);
Aquí están los resultados de las primeras 3 iteraciones usando BERNOULLI.
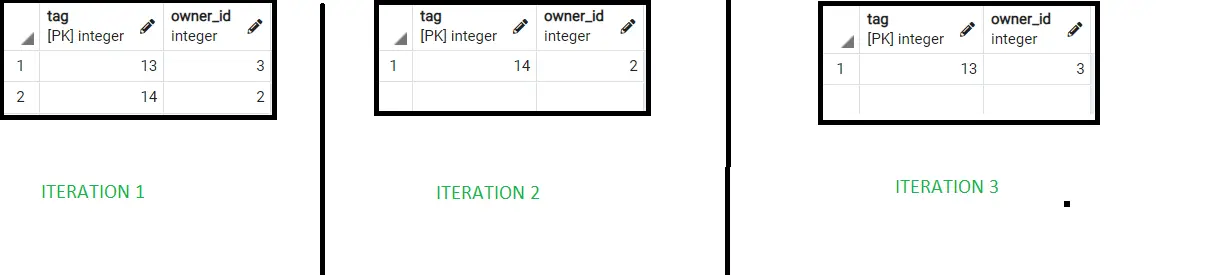
Por lo tanto, podemos ver que diferentes resultados aleatorios se obtienen correctamente usando el porcentaje pasado en el argumento.
Lo que hace que SYSTEM y BERNOULLI sean tan diferentes es que BERNOULLI ignora los resultados que están fuera del argumento especificado, mientras que SYSTEM solo devuelve aleatoriamente un BLOCK de la tabla que contendrá todas las filas, por lo tanto, las muestras menos aleatorias en “SISTEMA”.
Incluso puede definir una semilla para su consulta SAMPLING, como se muestra a continuación, para un muestreo aleatorio muy diferente que cuando no se proporciona ninguno.
select * from DOGGY tablesample bernoulli (30) repeatable (1);
Una extensión de TSM_SYSTEM_ROWS también puede lograr muestras aleatorias si de alguna manera termina agrupando. Primero debe agregar la extensión y luego usarla.
CREATE EXTENSION tsm_system_rows;
select * from DOGGY tablesample system_rows(1);
Sin embargo, depende del sistema. En el 90% de los casos, no habrá muestreo aleatorio, pero todavía hay una pequeña posibilidad de obtener valores aleatorios si de alguna manera se producen efectos de agrupamiento, es decir, una selección aleatoria de bloques particionados de una población que en nuestro caso será el mesa.
Debido a su ineficacia, también se desaconseja.
Use OFFSET FLOOR para una muestra aleatoria de una TABLA en PostgreSQL
A continuación se presenta una consulta que puede utilizar para obtener filas aleatorias de una tabla.
select * from DOGGY OFFSET floor(random() * 3) LIMIT 1;
OFFSET significa saltar filas antes de devolver un subconjunto de la tabla. Entonces, si tenemos un valor RANDOM() de 0.834, esto multiplicado por 3 devolvería 2.502.
El PISO de 2.502 es 2, y el OFFSET de 2 devolvería la última fila de la tabla DOGGY a partir de la fila número 3. LIMIT tiende a devolver una fila del subconjunto obtenido al definir el número OFFSET.
Use RANDOM en OID para obtener filas de una tabla en PostgreSQL
select * from DOGGY
where tag > floor((
select (
select reltuples::bigint AS estimate
from pg_class
where oid = 'public.DOGGY'::regclass) * random()
))
order by tag asc limit(1);
Entonces, ¿qué hace esta consulta? En nuestro caso, la consulta anterior estima el recuento de filas con un número aleatorio multiplicado por ROW ESTIMATE, y se devuelven las filas con un valor de TAG mayor que el valor calculado.
Es simple, pero efectivo. El uso de FLOOR devolverá el valor de piso de decimal y luego lo usará para obtener las filas de la tabla DOGGY.
Esperamos que ahora haya entendido los diferentes enfoques que podemos tomar para encontrar las filas aleatorias de una tabla en PostgreSQL.

Hello, I am Bilal, a research enthusiast who tends to break and make code from scratch. I dwell deep into the latest issues faced by the developer community and provide answers and different solutions. Apart from that, I am just another normal developer with a laptop, a mug of coffee, some biscuits and a thick spectacle!
GitHub