Wählen Sie Zufällige Zeilen in PostgreSQL aus
-
eine grundlegende Implementierung mit
Random()für die Zeilenauswahl in PostgreSQL - Zufällige Zeilenauswahl für größere Tabellen in PostgreSQL
-
Verwenden Sie
OFFSET FLOOR, um eineTABLEin PostgreSQL per Zufallsstichprobe zu erstellen -
Verwenden Sie
RANDOMaufOID, um Zeilen aus einer Tabelle in PostgreSQL abzurufen

Heute werden wir in PostgreSQL lernen, zufällige Zeilen aus einer Tabelle auszuwählen. Sie müssen anhand des Namens erraten haben, dass dies dazu neigt, zufällige, ungeplante Zeilen oder unaufgefordert zurückzugeben.
Schauen wir uns also einige Möglichkeiten an, wie wir eine zufällige Zeilenauswahl in PostgreSQL implementieren können.
eine grundlegende Implementierung mit Random() für die Zeilenauswahl in PostgreSQL
RANDOM() neigt dazu, eine Funktion zu sein, die einen zufälligen Wert im definierten Bereich zurückgibt; 0.0 <= x < 1.0. Dies verwendet einen DOUBLE PRECISION-Typ, und die Syntax ist wie folgt mit einem Beispiel.
random ( ) → double precision
random() → 0.897124072839091 - (example)
Jetzt können wir diese RANDOM()-Funktion verwenden, um eindeutige und willkürliche Werte zu erhalten. Wenn wir also beispielsweise eine SELECT-Operation für Datensätze aus einer Tabelle nur dann abfragen wollen, wenn der RANDOM()-Wert eher irgendwo um 0.05 liegt, dann können wir sicher sein, dass es zu unterschiedlichen Ergebnissen kommt jedes Mal erhalten.
Wir können dies beweisen, indem wir etwas wie folgt abfragen.
select * from DOGGY where random() <= 0.02
Wir haben die Tabelle DOGGY verwendet, die eine Reihe von TAGS und OWNER_IDs enthält. Was passiert also, wenn wir das obige ausführen?
Das Aufrufen der SELECT *-Operationen neigt dazu, jede Zeile zu prüfen, wenn die WHERE-Klausel hinzugefügt wird, um zu sehen, ob die geforderte Bedingung erfüllt ist oder nicht. Mit anderen Worten, es wird die TABELLE auf Daten prüfen, bei denen der RANDOM()-Wert kleiner oder gleich 0.02 ist.
Jedes Mal, wenn es eine Zeile aus der TABLE unter SELECT erhält, ruft es die Funktion RANDOM() auf, erhält eine eindeutige Zahl, und wenn diese Zahl kleiner als der vordefinierte Wert (0.02) ist. , es wird diese REIHE in unserem Endergebnis zurückgeben.
Andernfalls wird diese Zeile übersprungen und die nachfolgenden Zeilen werden überprüft. Dies ist in der Regel die einfachste Methode zum Abfragen zufälliger Zeilen aus der PostgreSQL-Tabelle.
Ähnliche Manipulationen wie bei der SELECT-Abfrage für Zufallsreihen
Eine andere sehr einfache Methode, die verwendet werden kann, um völlig zufällige Zeilen zu erhalten, ist die Verwendung der Klausel ORDER BY anstelle der Klausel WHERE. ORDER BY sortiert die Tabelle mit einer Bedingung, die in der Klausel in diesem Szenario definiert ist.
Wenn das der Fall ist, können wir jedes Mal nach einem RANDOM-Wert sortieren, um eine bestimmte Menge gewünschter Ergebnisse zu erhalten.
select * from DOGGY order by random();
Die obige Verarbeitung würde jedes Mal unterschiedliche Ergebnisse zurückgeben. Unten sind zwei Ausgabeergebnisse der Abfrage in der Tabelle DOGGY.
Ausgang 1:
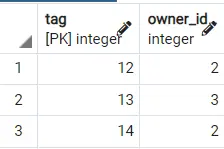
Ausgang 2:
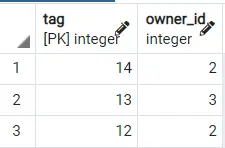
Daher können wir sehen, wie unterschiedliche Ergebnisse erzielt werden. Um es noch besser zu machen, können Sie die Klausel LIMIT [NUMBER] verwenden, um die ersten 2,3 usw. Zeilen aus dieser zufällig sortierten Tabelle zu erhalten, die wir wünschen.
Etwas wie folgt abzufragen wird gut funktionieren.
select * from DOGGY order by random() limit 2;
Kurzer Hinweis zur besten Methode unter den oben genannten für die zufällige Zeilenauswahl:
Die zweite Methode mit der Klausel ORDER BY ist tendenziell viel besser als die erstere. Denn in vielen Fällen kann RANDOM() dazu neigen, einen Wert zu liefern, der nicht kleiner oder größer als eine vordefinierte Zahl sein darf oder eine bestimmte Bedingung für jede Zeile erfüllt.
Dies kann am Ende zu falschen Ergebnissen oder sogar zu einer leeren Tabelle führen. Und daher gewinnt letzteres in diesem Fall.
Geordnete Zeilen können unter verschiedenen Bedingungen gleich sein, aber es wird niemals ein leeres Ergebnis geben.
Zufällige Zeilenauswahl für größere Tabellen in PostgreSQL
Effiziente und sofortige Ergebnisse sind in der Regel viel besser, wenn Abfragen berücksichtigt werden. Viele Tabellen haben möglicherweise mehr als eine Million Zeilen, und je größer die Datenmenge ist, desto länger dauert es, etwas aus der Tabelle abzufragen.
Wir suchen nach Lösungen, um den Overhead zu reduzieren und in einem solchen Szenario höhere Geschwindigkeiten bereitzustellen. Zu Beginn verwenden wir dieselbe Tabelle, DOGGY, und stellen verschiedene Möglichkeiten zur Reduzierung der Gemeinkosten vor, danach gehen wir zur Hauptauswahlmethode RANDOM über.
Eine Möglichkeit, den Overhead zu reduzieren, besteht darin, die wichtigen Daten in einer Tabelle viel früher zu schätzen, anstatt auf die Ausführung der Hauptabfrage zu warten und diese dann zu verwenden.
PostgreSQL neigt dazu, sehr langsame COUNT-Operationen für grössere Daten zu haben. Warum?
Angenommen, Sie würden in einer Tabelle mit 5 Millionen Zeilen jede Zeile hinzufügen und dann zählen, mit 5 Sekunden für 1 Million Zeilen, würden Sie am Ende 25 Sekunden nur für die COUNT verbrauchen. fertigstellen. Eine der Möglichkeiten, die Anzahl zu erhalten, anstatt COUNT(*) aufzurufen, ist die Verwendung von etwas, das als RELTUPLE bekannt ist.
RELTUPLE neigt dazu, die in einer Tabelle vorhandenen Daten zu schätzen, nachdem sie ANALYZIERT wurden. Wir können weitermachen und etwas wie folgt ausführen.
analyze doggy;
select reltuples as estimate from pg_class where relname = 'doggy';
Sie können dann die Ergebnisse überprüfen und feststellen, dass der von dieser Abfrage erhaltene Wert derselbe ist wie der von COUNT. Lassen Sie uns einige RANDOM-Zahlen für unsere Daten generieren.
Wir folgen einem einfachen Prozess für eine große Tabelle, um effizienter zu sein und große Gemeinkosten zu reduzieren.
- Es wird nicht zugelassen, dass doppelte Zufallswerte generiert werden
- Entfernen überzähliger Ergebnisse in der Abschlusstabelle
- Verwenden Sie
JOIN, um unser zufälliges Tabellenergebnis zu befestigen
Eine Abfrage wie die folgende wird gut funktionieren.
SELECT (r.tag::int / random())::int as x
FROM (
SELECT Distinct * from generate_series(6, 7) as tag limit 1
) r
JOIN DOGGY USING (tag)
Dadurch erhalten wir eine Tabelle von DOGGY mit Werten, die mit dem aus der Berechnung erhaltenen Zufallswert R.TAG übereinstimmen. Die Verwendung von LIMIT 1 in der SUB-QUERY tendiert dazu, eine einzelne Zufallszahl zu erhalten, um unserer DOGGY-Tabelle beizutreten.
Dies dient natürlich zu Testzwecken. Sie können fortfahren und dies auf eine andere Nummer manipulieren.
LIMIT 2 oder 3 wäre nett, wenn man bedenkt, dass DOGGY 3 Zeilen enthält. Dies ist eine viel bessere Lösung und schneller als seine Vorgänger.
Eine Möglichkeit, doppelte Werte in einer Tabelle zu entfernen, ist die Verwendung von UNION. Wir können alle einzigartigen und unterschiedlichen Elemente erhalten, indem wir dieselbe Abfrage wiederholen und mit der vorherigen eine UNION erstellen.
Also, wenn wir so etwas tun sollen:
SELECT (r.tag::int / random())::int as x
FROM (
SELECT Distinct * from generate_series(6, 7) as tag limit 1
) r
JOIN DOGGY USING (tag)
union
SELECT (r.tag::int / random())::int as x
FROM (
SELECT Distinct * from generate_series(5, 6) as tag limit 1
) r
JOIN DOGGY USING (tag)
Wir erhalten ein Endergebnis mit allen unterschiedlichen Werten und kleineren Lücken. Wir meinen Werte, die nicht in Ordnung sind, aber fehlen und nicht durch Lücken eingeschlossen sind.
Lücken können tendenziell zu ineffizienten Ergebnissen führen. Und muss daher um jeden Preis vermieden werden.
In ähnlicher Weise können wir aus dieser Abfrage eine Funktion erstellen, die dazu neigt, eine TABLE und Werte für die RANDOM SELECTION als Parameter zu nehmen. Einmal in unserer Datenbanksitzung verankert, können viele Benutzer diese Funktion später problemlos wiederverwenden.
Lassen Sie uns jetzt fortfahren und eine Funktion schreiben, die damit umgehen kann.
CREATE OR REPLACE FUNCTION random_func(limite int, limite_sup int)
RETURNS table (val int, val2 int)
LANGUAGE plpgsql VOLATILE ROWS 3 AS
$$
BEGIN
RETURN QUERY SELECT *
FROM (
SELECT Distinct * from generate_series(limite, limite_sup) as tag limit 1
) r
JOIN DOGGY USING (tag)
UNION
SELECT *
FROM (
SELECT Distinct * from generate_series(limite, limite_sup) as tag limit 1
) r
JOIN DOGGY USING (tag);
END
$$
Diese Funktion funktioniert so, wie Sie es erwarten. Es führt die UNION-Abfrage aus und gibt eine TABLE mit dem in unserem Parameter angegebenen LIMIT zurück.
Um unsere zufällige Auswahl zu erhalten, können wir diese Funktion wie folgt aufrufen.
SELECT * FROM random_func(6, 7);
Wieder einmal werden Sie feststellen, dass die Abfrage manchmal keine Werte zurückgibt, sondern hängen bleibt, da RANDOM oft keine Zahl aus dem Bereich ist, der in der FUNCTION definiert ist.
Eher unerwünschte Werte können zurückgegeben werden, und es würden keine ähnlichen Werte in der Tabelle vorhanden sein, was zu leeren Ergebnissen führen würde.
MATERIALISIERTE ANSICHTEN können anstelle von TABELLEN verwendet werden, um bessere Ergebnisse zu erzielen. Es merkt sich die Abfrage, mit der es initialisiert wurde, und aktualisiert es später.
Dieses REFRESH wird tendenziell auch neue Werte für RANDOM mit einer besseren Geschwindigkeit zurückgeben und kann effektiv verwendet werden.
Nicht empfohlene Methode für zufälliges Sampling einer Tabelle in PostgreSQL
Eine weitere brillante Methode, um zufällige Zeilen aus einer Tabelle zu erhalten, hätte die Methode TABLESAMPLE sein können, die im Abschnitt SELECT (FROM) der PostgreSQL-Dokumentation definiert ist.
Syntax:
TABLESAMPLE sampling_method ( argument [, ...] ) [ REPEATABLE ( seed ) ]
Wenn das Argument der Prozentsatz der Tabelle ist, die Sie zurückgeben möchten, ist diese Teilmenge der zurückgegebenen Tabelle völlig zufällig und variiert. In den meisten Fällen sind die Ergebnisse jedoch nur geordnete oder Originalversionen der Tabelle und geben konsistent dieselben Tabellen zurück.
Das Ausführen einer Abfrage wie der folgenden auf DOGGY würde unterschiedliche, aber konsistente Ergebnisse für vielleicht die ersten paar Ausführungen zurückgeben.
Kurz gesagt, TABLESAMPLE kann zwei verschiedene sampling_methods haben; BERNOULLI und SYSTEM. Wir werden zuerst SYSTEM verwenden.
select * from DOGGY tablesample system (30);
Hier sind die Ergebnisse für die ersten 3 Iterationen mit SYSTEM.

Sie können feststellen, dass die Ergebnisse nicht unseren Erwartungen entsprechen, aber die falschen Teilmengen liefern. Unsere kurze Datentabelle DOGGY verwendet BERNOULLI statt SYSTEM; jedoch neigt es dazu, genau das zu tun, was wir wollen.
select * from DOGGY tablesample bernoulli (30);
Hier sind die Ergebnisse der ersten 3 Iterationen mit BERNOULLI.
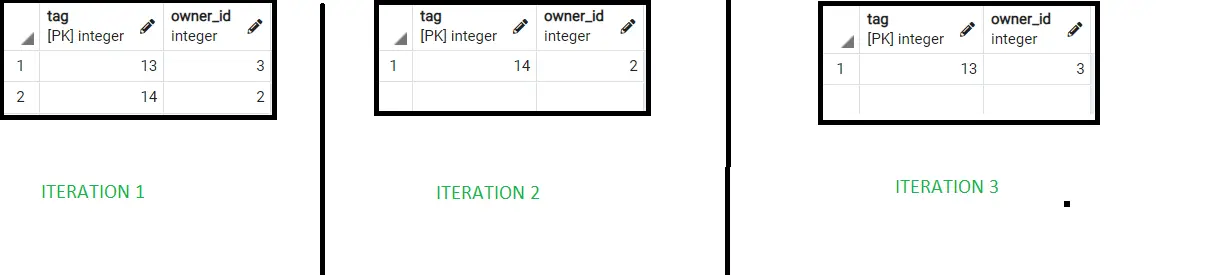
Daher können wir sehen, dass verschiedene Zufallsergebnisse korrekt erhalten werden, wenn der im Argument übergebene Prozentsatz verwendet wird.
Was SYSTEM und BERNOULLI so unterschiedlich macht, ist, dass BERNOULLI Ergebnisse ignoriert, die außerhalb des angegebenen Arguments gebunden sind, während SYSTEM nur zufällig einen BLOCK einer Tabelle zurückgibt, die alle Zeilen enthält, daher die weniger zufälligen Stichproben darin SYSTEM.
Sie können sogar einen Startwert für Ihre SAMPLING-Abfrage definieren, wie z. B. im Folgenden, für eine ganz andere Zufallsstichprobe, als wenn keine bereitgestellt wird.
select * from DOGGY tablesample bernoulli (30) repeatable (1);
Eine Erweiterung von TSM_SYSTEM_ROWS kann möglicherweise auch Zufallsstichproben erzielen, wenn es irgendwie zu Clusterbildung kommt. Sie müssten die Erweiterung zuerst hinzufügen und dann verwenden.
CREATE EXTENSION tsm_system_rows;
select * from DOGGY tablesample system_rows(1);
Allerdings kommt es auf das System an. In 90 % der Fälle wird es keine Zufallsstichprobe geben, aber es besteht immer noch eine kleine Chance, zufällige Werte zu erhalten, wenn irgendwie Clustering-Effekte stattfinden, dh eine zufällige Auswahl partitionierter Blöcke aus einer Population, die in unserem Fall die sein wird Tisch.
Aufgrund seiner Unwirksamkeit wird auch davon abgeraten.
Verwenden Sie OFFSET FLOOR, um eine TABLE in PostgreSQL per Zufallsstichprobe zu erstellen
Eine Abfrage, die Sie verwenden können, um zufällige Zeilen aus einer Tabelle abzurufen, wird wie folgt dargestellt.
select * from DOGGY OFFSET floor(random() * 3) LIMIT 1;
OFFSET bedeutet, dass Zeilen übersprungen werden, bevor eine Teilmenge aus der Tabelle zurückgegeben wird. Wenn wir also einen RANDOM()-Wert von 0.834 haben, würde dies multipliziert mit 3 2.502 zurückgeben.
Der FLOOR von 2.502 ist 2, und der OFFSET von 2 würde die letzte Zeile der Tabelle DOGGY beginnend mit der Zeilennummer 3 zurückgeben. LIMIT neigt dazu, eine Zeile aus der Teilmenge zurückzugeben, die durch Definieren der OFFSET-Zahl erhalten wird.
Verwenden Sie RANDOM auf OID, um Zeilen aus einer Tabelle in PostgreSQL abzurufen
select * from DOGGY
where tag > floor((
select (
select reltuples::bigint AS estimate
from pg_class
where oid = 'public.DOGGY'::regclass) * random()
))
order by tag asc limit(1);
Was macht diese Abfrage? In unserem Fall schätzt die obige Abfrage die Zeilenanzahl mit einer Zufallszahl multipliziert mit ROW ESTIMATE, und die Zeilen mit einem TAG-Wert, der größer als der berechnete Wert ist, werden zurückgegeben.
Es ist einfach, aber effektiv. Die Verwendung von FLOOR gibt den Dezimalwert des Dezimalwerts zurück und verwendet ihn dann, um die Zeilen aus der DOGGY-Tabelle zu erhalten.
Wir hoffen, Sie haben jetzt die verschiedenen Ansätze verstanden, die wir verwenden können, um die zufälligen Zeilen aus einer Tabelle in PostgreSQL zu finden.

Hello, I am Bilal, a research enthusiast who tends to break and make code from scratch. I dwell deep into the latest issues faced by the developer community and provide answers and different solutions. Apart from that, I am just another normal developer with a laptop, a mug of coffee, some biscuits and a thick spectacle!
GitHub