PostgreSQL でランダムな行を選択する
-
PostgreSQL での行選択に
Random()を使用した基本的な実装 - PostgreSQL でのより大きなテーブルのランダム行選択
-
OFFSET FLOORを使用して、PostgreSQL でTABLEをランダムにサンプリングする -
OIDでRANDOMを使用して PostgreSQL のテーブルから行を取得する

今日の PostgreSQL では、テーブルからランダムな行を選択する方法を学びます。 名前から、これがランダムな、計画外の行、または呼び出されていない行を返すのに役立つ傾向があることを推測したに違いありません。
それでは、PostgreSQL でランダムな行選択を実装する方法をいくつか見てみましょう。
PostgreSQL での行選択に Random() を使用した基本的な実装
RANDOM() は、定義された範囲内のランダムな値を返す関数になりがちです。 0.0 <= x < 1.0. これは DOUBLE PRECISION 型を使用しており、構文は次のようになります。
random ( ) → double precision
random() → 0.897124072839091 - (example)
これで、この RANDOM() 関数を使用して、一意の任意の値を取得できます。 したがって、クエリを実行したい場合、たとえばテーブルのデータセットに対して SELECT 操作を行う場合、RANDOM() 値が 0.05 付近にある傾向がある場合にのみ、異なる結果が得られることを確認できます。 毎回入手。
これは、次のようにクエリを実行することで証明できます。
select * from DOGGY where random() <= 0.02
TAGS と OWNER_IDs のセットを含む DOGGY テーブルを使用しました。 では、上記を実行するとどうなるでしょうか。
SELECT * 操作を呼び出すと、要求された条件が満たされているかどうかを確認するために WHERE 句が追加されたときに各行がチェックされる傾向があります。 つまり、TABLE をチェックして、RANDOM() 値が 0.02 以下のデータを探します。
したがって、SELECT の下にある TABLE から行を受け取るたびに、RANDOM() 関数を呼び出して一意の番号を受け取り、その番号が事前定義された値 (0.02) より小さい場合は、 、最終結果でその ROW を返します。
それ以外の場合、その行はスキップされ、後続の行がチェックされます。 これは、PostgreSQL テーブルからランダムな行をクエリする最も簡単な方法になる傾向があります。
ランダム行に対する SELECT クエリと同様の操作
完全にランダムな行を取得するために使用できるもう 1つの非常に簡単な方法は、WHERE 句ではなく ORDER BY 句を使用することです。 ORDER BY は、そのシナリオの句で定義された条件でテーブルを並べ替えます。
その場合、毎回 RANDOM 値でソートして、特定の一連の望ましい結果を得ることができます。
select * from DOGGY order by random();
上記を処理すると、毎回異なる結果が返されます。 以下は、DOGGY テーブルでこれをクエリした 2つの出力結果です。
出力 1:
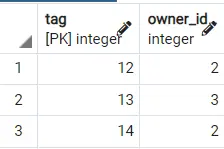
出力 2:
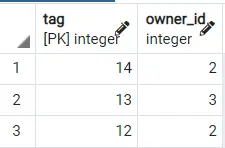
したがって、どのように異なる結果が得られるかがわかります。 さらに良くするために、LIMIT [NUMBER] 句を使用して、このランダムにソートされたテーブルから最初の 2,3 などの行を取得できます。
次のようにクエリを実行すると、問題なく動作します。
select * from DOGGY order by random() limit 2;
ランダムな行選択のための上記の中で最良の方法に関する短いメモ:
ORDER BY 句を使用する 2 番目の方法は、前者よりもはるかに優れている傾向があります。 多くの場合、RANDOM() は、事前に定義された数値よりも小さくも大きくもならない値を提供したり、任意の行の特定の条件を満たしたりする傾向があるためです。
これにより、結果が不正確になったり、テーブルが空になったりする可能性があります。 したがって、この場合は後者が勝ちます。
順序付けされた行は、条件が異なっても同じ場合がありますが、結果が空になることはありません。
PostgreSQL でのより大きなテーブルのランダム行選択
クエリを検討する場合、効率的で即時の結果の方がはるかに優れている傾向があります。 多くのテーブルには 100 万行を超える行があり、データ量が多いほど、テーブルから何かをクエリするのに必要な時間が長くなります。
このようなシナリオでオーバーヘッドを削減し、より高速な速度を提供するソリューションを検討します。 まず、同じテーブル DOGGY を使用して、オーバーヘッドを削減するさまざまな方法を提示します。その後、メインの RANDOM 選択方法に移ります。
オーバーヘッドを削減する方法の 1つは、メイン クエリの実行を待ってからこれを使用するのではなく、テーブル内の重要なデータをはるかに早く推定することです。
PostgreSQL は、大きなデータに対して非常に遅い COUNT 操作を行う傾向があります。 なぜ?
たとえば、500 万のテーブルで、各行を追加してカウントすると、1 百万行に対して 5 秒かかるため、COUNT だけで 25 秒を消費することになります。 完了します。 COUNT(*) を呼び出す代わりにカウントを取得する方法の 1つは、RELTUPLE と呼ばれるものを使用することです。
RELTUPLEは、ANALYZEDされた後にテーブルに存在するデータを推定する傾向があります。 次のように何かを実行できます。
analyze doggy;
select reltuples as estimate from pg_class where relname = 'doggy';
結果を確認すると、このクエリから取得した値が COUNT から取得した値と同じであることがわかります。 データに対していくつかの RANDOM 数値を生成してみましょう。
大きなテーブルがより効率的になり、大きなオーバーヘッドを削減するための簡単なプロセスに従います。
- 重複するランダム値の生成を許可しない
- ファイナル テーブルで余分な結果を削除する
JOINを使用してランダム テーブルの結果を固定する
次のようなクエリはうまく機能します。
SELECT (r.tag::int / random())::int as x
FROM (
SELECT Distinct * from generate_series(6, 7) as tag limit 1
) r
JOIN DOGGY USING (tag)
これにより、計算から受け取ったランダム値 R.TAG に一致する値を持つ DOGGY からのテーブルが返されます。 SUB-QUERY で LIMIT 1 を使用すると、DOGGY テーブルに参加するための単一の乱数を取得する傾向があります。
もちろん、これはテスト用です。 先に進んで、これを他の数値に操作することができます。
DOGGYには3行が含まれていることを考えると、LIMIT 2または3が適しています。 これは、はるかに優れたソリューションとして機能し、以前のものよりも高速です。
テーブル内の重複値を削除する方法の 1つは、UNION を使用することです。 同じクエリを繰り返し、前のクエリで UNION を作成することにより、すべてのユニークで異なる要素を得ることができます。
したがって、次のようなことを行う場合:
SELECT (r.tag::int / random())::int as x
FROM (
SELECT Distinct * from generate_series(6, 7) as tag limit 1
) r
JOIN DOGGY USING (tag)
union
SELECT (r.tag::int / random())::int as x
FROM (
SELECT Distinct * from generate_series(5, 6) as tag limit 1
) r
JOIN DOGGY USING (tag)
すべての値が異なり、ギャップが少ない最終結果が得られます。 順序どおりではなく欠落しており、ギャップに含まれていない値を意味します。
ギャップは、非効率的な結果を生み出す傾向があります。 したがって、絶対に避けなければなりません。
同様に、このクエリから、TABLE と RANDOM SELECTION の値をパラメーターとして受け取る関数を作成できます。 一度データベース セッションに組み込まれると、多くのユーザーは後でこの機能を簡単に再利用できます。
それでは、これを処理できる関数を書きましょう。
CREATE OR REPLACE FUNCTION random_func(limite int, limite_sup int)
RETURNS table (val int, val2 int)
LANGUAGE plpgsql VOLATILE ROWS 3 AS
$$
BEGIN
RETURN QUERY SELECT *
FROM (
SELECT Distinct * from generate_series(limite, limite_sup) as tag limit 1
) r
JOIN DOGGY USING (tag)
UNION
SELECT *
FROM (
SELECT Distinct * from generate_series(limite, limite_sup) as tag limit 1
) r
JOIN DOGGY USING (tag);
END
$$
この関数は、期待どおりに機能します。 UNION クエリを実行し、パラメーターで指定された LIMIT を使用して TABLE を返します。
ランダムな選択を取得するには、次のようにこの関数を呼び出します。
SELECT * FROM random_func(6, 7);
RANDOM は FUNCTION で定義された範囲の数値ではないことが多いため、クエリが値を返さずにスタックしたままになることがあります。
不要な値が返される可能性があり、同様の値がテーブルに存在しないため、結果が空になります。
TABLESではなくMATERIALIZED VIEWSを使用して、より良い結果を生成できます。 初期化に使用されたクエリを記憶し、後で更新します。
この REFRESH は、RANDOM の新しい値をより高速に返す傾向があり、効果的に使用できます。
PostgreSQL でのテーブルのランダム サンプリングの推奨されない方法
テーブルからランダムな行を取得するもう 1つの優れた方法は、PostgreSQL ドキュメントのSELECT (FROM)セクションで定義されているTABLESAMPLEメソッドです。
構文:
TABLESAMPLE sampling_method ( argument [, ...] ) [ REPEATABLE ( seed ) ]
引数が返されるテーブルのパーセンテージである場合、返されるテーブルのこのサブセットは完全にランダムであり、さまざまです。 ただし、ほとんどの場合、結果はテーブルの順序付けられたバージョンまたは元のバージョンであり、一貫して同じテーブルが返されます。
DOGGY に対して次のようなクエリを実行すると、おそらく最初の数回の実行では、さまざまではあるが一貫した結果が返されます。
簡単に言えば、TABLESAMPLE は 2つの異なる sampling_methods を持つことができます。 BERNOULLIとSYSTEM。 SYSTEM を最初に使用します。
select * from DOGGY tablesample system (30);
以下は、SYSTEM を使用した最初の 3 反復の結果です。

結果は期待したものではなく、間違ったサブセットを提供していることに気付くでしょう。 私たちの短いデータテーブル DOGGY は、SYSTEM ではなく BERNOULLI を使用しています。 ただし、それは私たちが望むことを正確に行う傾向があります。
select * from DOGGY tablesample bernoulli (30);
以下は、BERNOULLI を使用した最初の 3 反復の結果です。
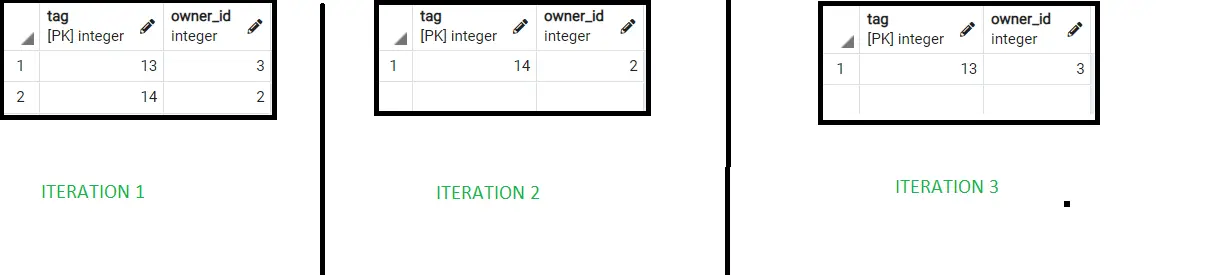
したがって、引数で渡されたパーセンテージを使用して、さまざまなランダムな結果が正しく得られることがわかります。
SYSTEM と BERNOULLI の違いは、BERNOULLI は指定された引数の外側にバインドされた結果を無視するのに対し、SYSTEM はすべての行を含むテーブルの BLOCK をランダムに返すため、ランダムなサンプルが少なくなることです。 “システム”。
次のように、SAMPLING クエリのシードを定義して、何も指定しない場合とはかなり異なるランダム サンプリングを行うこともできます。
select * from DOGGY tablesample bernoulli (30) repeatable (1);
TSM_SYSTEM_ROWS の拡張機能は、何らかの形でクラスタリングが終了した場合、ランダム サンプルを達成できる場合もあります。 最初に拡張機能を追加してから使用する必要があります。
CREATE EXTENSION tsm_system_rows;
select * from DOGGY tablesample system_rows(1);
ただし、システムによって異なります。 90% のケースでは、ランダム サンプリングは行われませんが、何らかのクラスタリング効果が発生した場合、つまり、この場合は テーブル。
その非効率性のために、同様に推奨されていません。
OFFSET FLOOR を使用して、PostgreSQL で TABLE をランダムにサンプリングする
テーブルからランダムな行を取得するために使用できるクエリを次に示します。
select * from DOGGY OFFSET floor(random() * 3) LIMIT 1;
OFFSETは、テーブルからサブセットを返す前に行をスキップすることを意味します。 したがって、RANDOM()の値が0.834の場合、これに3を掛けると2.502が返されます。
2.502 の FLOOR は 2 であり、2 の OFFSET は、行番号 3 から始まるテーブル DOGGY の最後の行を返します。 LIMIT は、OFFSET 番号を定義することによって得られたサブセットから 1 行を返す傾向があります。
OID で RANDOM を使用して PostgreSQL のテーブルから行を取得する
select * from DOGGY
where tag > floor((
select (
select reltuples::bigint AS estimate
from pg_class
where oid = 'public.DOGGY'::regclass) * random()
))
order by tag asc limit(1);
では、このクエリは何をするのでしょうか? この場合、上記のクエリは、乱数に ROW ESTIMATE を掛けて行数を推定し、計算された値より大きい TAG 値を持つ行が返されます。
シンプルですが効果的です。 FLOOR を使用すると、10 進数のフロア値が返され、それを使用して DOGGY テーブルから行が取得されます。
PostgreSQL のテーブルからランダムな行を見つけるために使用できるさまざまなアプローチを理解していただければ幸いです。

Hello, I am Bilal, a research enthusiast who tends to break and make code from scratch. I dwell deep into the latest issues faced by the developer community and provide answers and different solutions. Apart from that, I am just another normal developer with a laptop, a mug of coffee, some biscuits and a thick spectacle!
GitHub