R의 다항식 회귀
다항식 회귀는 독립 x와 종속 y 간의 관계가 n차 다항식으로 모델링되는 선형 회귀로 정의할 수 있습니다. 이 튜토리얼은 R에서 다항식 회귀를 수행하는 방법을 보여줍니다.
R의 다항식 회귀
다항식 회귀는 x와 y의 평균 사이의 비선형 관계에 적합합니다. 다항식 또는 2차 항을 회귀에 추가합니다.
이 회귀는 하나의 결과 변수와 예측 변수에 사용됩니다. 다항식 회귀는 주로 다음에서 사용됩니다.
- 전염병의 진행
- 조직의 성장률 계산
- 퇴적물 내 탄소 동위원소 분포
ggplot2를 사용하여 R의 다항식 회귀를 그릴 수 있습니다. 이 패키지가 아직 설치되지 않은 경우; 먼저 설치해야 합니다.
install.packages('ggplot2')
다음은 다항식 회귀의 단계별 프로세스입니다.
데이터 생성
우리는 delftstack 학생들의 데이터로 데이터 프레임을 생성합니다: 공부한 시간, 기말 고사 점수, 학급의 총 학생 수(60명).
예:
#create data frame
delftstack <- data.frame(hours = runif(60, 6, 20), marks=60)
delftstack$marks = delftstack$marks + delftstack$hours^3/160 + delftstack$hours*runif(60, 1, 2)
#view the head of the data
head(delftstack)
이 코드는 나중에 다항식 회귀에 사용되는 데이터를 생성합니다.
출력:
hours marks
1 7.106636 71.33509
2 8.501039 74.93339
3 18.051042 124.92229
4 19.153316 141.40656
5 18.306620 118.47464
6 6.240467 70.53522
데이터 시각화
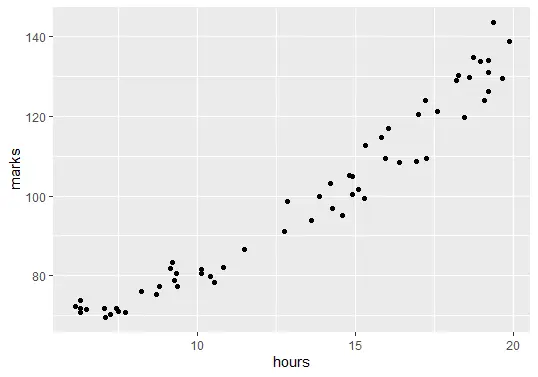
다음 단계는 데이터를 시각화하는 것입니다. 회귀 모델을 만들기 전에 공부한 시간과 최종 시험 점수 사이의 관계를 보여줘야 합니다.
예:
# Visualization
library(ggplot2)
ggplot(delftstack, aes(x=hours, y=marks)) + geom_point()
위의 코드는 데이터 그래프를 그립니다.
다항식 회귀 모델 피팅
다음 단계는 1에서 6까지의 다항식 회귀 모델과 k=10인 k-겹 교차 검증을 맞추는 것입니다.
예:
#shuffle data
delftstack.shuffled <- delftstack[sample(nrow(df)),]
# number of k-fold cross-validation
K <- 10
#define the degree of polynomials to fit
degree <- 6
# now create k equal-sized folds
fold <- cut(seq(1,nrow(delftstack.shuffled)),breaks=K,labels=FALSE)
#The object to hold MSE's of models
mse_object = matrix(data=NA,nrow=K,ncol=degree)
#K-fold cross validation
for(i in 1:K){
#testing and training data
test_indexes <- which(fold==i,arr.ind=TRUE)
test_data <- delftstack.shuffled[test_indexes, ]
train_data <- delftstack.shuffled[-test_indexes, ]
# using k-fold cv for models evaluation
for (j in 1:degree){
fit.train = lm(marks ~ poly(hours,j), data=train_data)
fit.test = predict(fit.train, newdata=test_data)
mse_object[i,j] = mean((fit.test-test_data$marks)^2)
}
}
# MSE for each degree
colMeans(mse_object)
출력:
[1] 26.13112 15.45428 15.87187 16.88782 18.13103 19.10502
6개의 모델이 있으며 각 모델에 대한 MSE는 위 코드의 출력에 제공됩니다. 이 출력은 각각 각도 h=1에서 h=6에 대한 것입니다.
MSE가 가장 낮은 모델은 h=2의 MSE 값이 다른 모델보다 작기 때문에 h=2인 다항 회귀 모델이 됩니다.
최종 모델 분석
마지막으로 최종 모델을 분석하고 가장 적합한 모델의 요약을 보여드리겠습니다.
예:
#fitting the best model
best_model = lm(marks ~ poly(hours,2, raw=T), data=delftstack)
#summary of the best model
summary(best_model)
위의 코드는 가장 적합한 모델의 요약을 보여줍니다.
출력:
Call:
lm(formula = marks ~ poly(hours, 2, raw = T), data = delftstack)
Residuals:
Min 1Q Median 3Q Max
-8.797 -2.598 0.337 2.443 9.872
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 68.42847 5.54533 12.340 < 2e-16 ***
poly(hours, 2, raw = T)1 -1.07557 0.93476 -1.151 0.255
poly(hours, 2, raw = T)2 0.22958 0.03577 6.418 2.95e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 4.204 on 57 degrees of freedom
Multiple R-squared: 0.9669, Adjusted R-squared: 0.9657
F-statistic: 831.9 on 2 and 57 DF, p-value: < 2.2e-16
출력에서 마크 = 68.42847 - 1.07557*(시간) + .22958*(시간)2를 볼 수 있습니다. 이 방정식을 사용하여 학생이 공부한 시간에 따라 얼마나 많은 점수를 받을지 예측할 수 있습니다.
예를 들어 학생이 5시간 동안 공부했다면 다음과 같이 계산됩니다.
marks = 68.42847 - 1.07557*(5) + .22958*(5)2
marks = 68.42847 - 1.07557*5 + .22958*25
marks = 68.42847 - 5.37785 + 5.7395
marks = 68.79012
학생이 5시간 공부하면 기말고사에서 68.79012점을 받습니다.
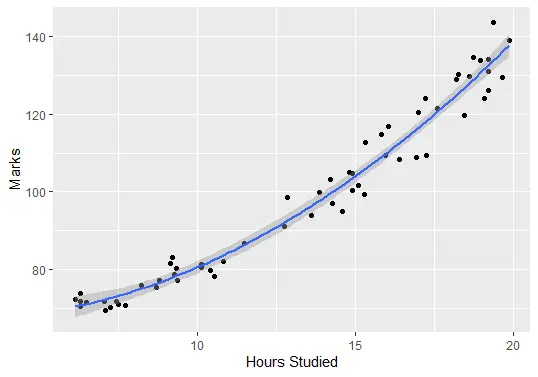
마지막으로 피팅된 모델을 플롯하여 원시 데이터와 얼마나 잘 일치하는지 확인할 수 있습니다.
ggplot(delftstack, aes(x=hours, y=marks)) +
geom_point() +
stat_smooth(method='lm', formula = y ~ poly(x,2), size = 1) +
xlab('Hours Studied') +
ylab('Marks')
출력(플롯):

Sheeraz is a Doctorate fellow in Computer Science at Northwestern Polytechnical University, Xian, China. He has 7 years of Software Development experience in AI, Web, Database, and Desktop technologies. He writes tutorials in Java, PHP, Python, GoLang, R, etc., to help beginners learn the field of Computer Science.
LinkedIn Facebook