Regresión polinomial en R
La regresión polinomial se puede definir como una regresión lineal en la que la relación entre la x independiente y la y dependiente se modelará como el polinomio de grado n. Este tutorial demuestra cómo realizar una regresión polinomial en R.
Regresión polinomial en R
La regresión polinomial ajustará una relación no lineal entre x y la media de y. Agregará los términos polinómicos o cuadráticos a la regresión.
Esta regresión se usa para una variable resultante y un predictor. La regresión polinomial se utiliza principalmente en:
- Progresión de enfermedades epidémicas
- Cálculo de la tasa de crecimiento de los tejidos.
- Distribución de isótopos de carbono en sedimentos
Podemos usar ggplot2 para trazar la regresión polinomial en R. Si este paquete aún no está instalado; primero, necesitamos instalarlo:
install.packages('ggplot2')
Aquí está el proceso paso a paso de la regresión polinomial.
Creación de datos
Creamos un marco de datos con los datos de los estudiantes de delftstack: la cantidad de horas estudiadas, las calificaciones de los exámenes finales y el número total de estudiantes en la clase, que es 60.
Ejemplo:
#create data frame
delftstack <- data.frame(hours = runif(60, 6, 20), marks=60)
delftstack$marks = delftstack$marks + delftstack$hours^3/160 + delftstack$hours*runif(60, 1, 2)
#view the head of the data
head(delftstack)
Este código creará los datos que se utilizarán más tarde para la regresión polinomial.
Producción :
hours marks
1 7.106636 71.33509
2 8.501039 74.93339
3 18.051042 124.92229
4 19.153316 141.40656
5 18.306620 118.47464
6 6.240467 70.53522
Visualización de datos
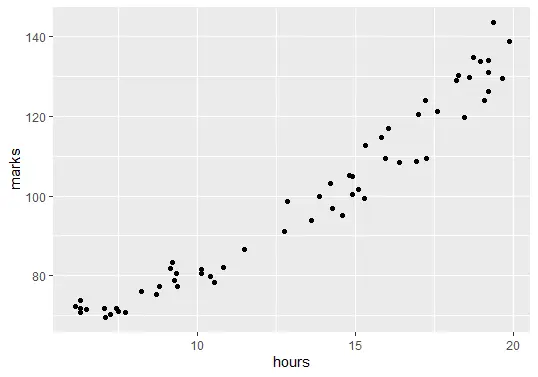
El siguiente paso es visualizar los datos. Antes de crear el modelo de regresión, necesitamos mostrar la relación entre el número de horas estudiadas y las notas del examen final.
Ejemplo:
# Visualization
library(ggplot2)
ggplot(delftstack, aes(x=hours, y=marks)) + geom_point()
El código anterior trazará el gráfico de nuestros datos:
Ajuste los modelos de regresión polinomial
El siguiente paso es ajustar los modelos de regresión polinomial con grados 1 a 6 y validación cruzada k-fold con k=10.
Ejemplo:
#shuffle data
delftstack.shuffled <- delftstack[sample(nrow(df)),]
# number of k-fold cross-validation
K <- 10
#define the degree of polynomials to fit
degree <- 6
# now create k equal-sized folds
fold <- cut(seq(1,nrow(delftstack.shuffled)),breaks=K,labels=FALSE)
#The object to hold MSE's of models
mse_object = matrix(data=NA,nrow=K,ncol=degree)
#K-fold cross validation
for(i in 1:K){
#testing and training data
test_indexes <- which(fold==i,arr.ind=TRUE)
test_data <- delftstack.shuffled[test_indexes, ]
train_data <- delftstack.shuffled[-test_indexes, ]
# using k-fold cv for models evaluation
for (j in 1:degree){
fit.train = lm(marks ~ poly(hours,j), data=train_data)
fit.test = predict(fit.train, newdata=test_data)
mse_object[i,j] = mean((fit.test-test_data$marks)^2)
}
}
# MSE for each degree
colMeans(mse_object)
Producción :
[1] 26.13112 15.45428 15.87187 16.88782 18.13103 19.10502
Hay seis modelos, y los MSEs para cada modelo se dan en el resultado del código anterior. Esta salida es para grados h=1 a h=6, respectivamente.
El modelo con el MSE más bajo será nuestro modelo de regresión polinomial, que es h=2 porque el valor de MSE de h=2 es menor que todos los demás.
Analizar el modelo final
Finalmente, analicemos el modelo final y mostremos el resumen del modelo mejor ajustado:
Ejemplo:
#fitting the best model
best_model = lm(marks ~ poly(hours,2, raw=T), data=delftstack)
#summary of the best model
summary(best_model)
El código anterior mostrará el resumen del modelo mejor ajustado.
Producción :
Call:
lm(formula = marks ~ poly(hours, 2, raw = T), data = delftstack)
Residuals:
Min 1Q Median 3Q Max
-8.797 -2.598 0.337 2.443 9.872
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 68.42847 5.54533 12.340 < 2e-16 ***
poly(hours, 2, raw = T)1 -1.07557 0.93476 -1.151 0.255
poly(hours, 2, raw = T)2 0.22958 0.03577 6.418 2.95e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 4.204 on 57 degrees of freedom
Multiple R-squared: 0.9669, Adjusted R-squared: 0.9657
F-statistic: 831.9 on 2 and 57 DF, p-value: < 2.2e-16
De la salida, podemos ver que marcas = 68.42847 - 1.07557*(horas) + .22958*(horas)2. Usando esta ecuación, podemos predecir cuántas marcas obtendrá un estudiante en función de la cantidad de horas estudiadas.
Por ejemplo, si un estudiante estudió durante 5 horas, el cálculo será:
marks = 68.42847 - 1.07557*(5) + .22958*(5)2
marks = 68.42847 - 1.07557*5 + .22958*25
marks = 68.42847 - 5.37785 + 5.7395
marks = 68.79012
Si un alumno estudia 5 horas, obtendrá 68,79012 puntos en el examen final.
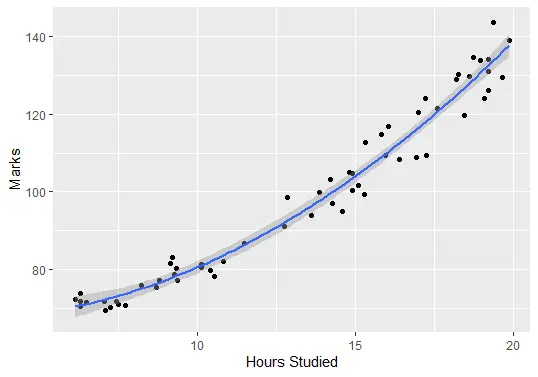
Por último, podemos trazar el modelo ajustado para verificar qué tan bien se corresponde con los datos sin procesar:
ggplot(delftstack, aes(x=hours, y=marks)) +
geom_point() +
stat_smooth(method='lm', formula = y ~ poly(x,2), size = 1) +
xlab('Hours Studied') +
ylab('Marks')
Salida (trama):

Sheeraz is a Doctorate fellow in Computer Science at Northwestern Polytechnical University, Xian, China. He has 7 years of Software Development experience in AI, Web, Database, and Desktop technologies. He writes tutorials in Java, PHP, Python, GoLang, R, etc., to help beginners learn the field of Computer Science.
LinkedIn Facebook