Pandas의 GroupBy 개체에 대한 유용한 롤링 함수 소개
- Pandas 롤링 대 롤링 윈도우
- 롤링 윈도우 기능
-
dataframe.rolling()함수의 구문 및 작업 프로세스 - Pandas의 GroupBy 개체에 대한 유용한 롤링 기능
-
Pandas의 GroupBy 객체에
rolling().sum()함수 사용 -
Pandas의 GroupBy 객체에
rolling().mean()함수 사용 -
Pandas의 GroupBy 개체에 대한 여러 열에서
rolling().agg()함수 사용
오늘은 Pandas 롤링과 롤링 창 기능의 차이점을 살펴보겠습니다. 롤링 창 기능, 구문 및 작업 프로세스에 대해 알아보고 Pandas의 개체별로 그룹에 대한 다양한 롤링 기능을 보여주는 다양한 코드 예제를 안내합니다.
Pandas 롤링 대 롤링 윈도우
Python에는 다양한 데이터 중심 라이브러리/패키지가 있으며 Pandas도 그 중 하나입니다. 우리는 이 라이브러리의 다양한 유용한 기능을 사용하며 그 중 하나는 rolling() 기능으로 알려져 있습니다.
dataframe.rolling() 함수는 제공된 데이터에 대해 복잡한 계산을 수행합니다. 또한 롤링 창이라는 기능이 있으며 이 섹션에서 잠시 예를 들어 볼 수 있습니다.
롤링 윈도우 기능은 주로 시계열 및 신호 처리 데이터와 함께 작동합니다. 주어진 개체 시리즈에서 제공된 입력 데이터에 대한 계산을 수행하는 데 사용합니다.
예를 들어 w가 창 크기이고 t가 시간이라고 가정하면 t 시간에 창 크기 w를 사용하여 데이터에 원하는 수학 연산을 적용할 수 있습니다. 창 크기 w는 t 시간에 w 연속 값을 의미합니다. 모든 w 값은 시간 t에서 동일하게 가중됩니다.
롤링 윈도우 기능
롤링 윈도우는 지정된 날짜부터 롤링 윈도우 시프트까지 제공된 데이터에 대해 계산을 수행하는 것을 의미합니다. 예를 들어, 모든 직원은 1개월 롤링 윈도우에 있으며, 이는 매년 매월 1일에 급여를 받게 됨을 의미합니다.
첫 번째 급여는 1월 1일, 두 번째 급여는 2월 1일, 세 번째 급여는 3월 1일입니다. 이 과정은 모든 직원이 12월 1일에 12번째 급여를 받을 때까지 계속됩니다. 이 과정은 매년 반복됩니다.
따라서 롤링 윈도우 기능은 지정된 첫 번째 날짜를 기준으로 하며 주어진 롤링 윈도우 시간에 따라 자동으로 앞으로 이동한다고 말할 수 있습니다. 이 시나리오에서는 1개월 롤링 창입니다.
롤링 창은 크기가 고정되어 있지만 확장 창은 시작점만 고정되어 있습니다. 가능한 경우 데이터를 통합하도록 확장할 수 있습니다. 여기에서 차이점을 읽을 수 있습니다.
dataframe.rolling() 함수의 구문 및 작업 프로세스
dataframe.rolling() 함수는 롤링 창 수의 요소를 제공합니다. dataframe.rolling()의 개념은 사용자가 가중치 창 크기(w)를 한 번만 지정하고 일부 작업을 수행하는 일반 롤링 창과 동일합니다.
dataframe.rolling() 구문은 다음과 같습니다.
DataFrame.rolling(window, min_periods=None, freq=None, center=False, win_type=None, on=None, axis=0, closed=None)
다음 매개변수를 사용할 수 있습니다.
| 모수 | 설명 |
|---|---|
window |
움직이는 창의 크기입니다. 계산에 사용되는 여러 값/관찰이 있습니다. |
min_periods |
값이 있어야 하는 창에서 최소 개수의 값/관찰을 보여줍니다. 그렇지 않으면 출력은 NA입니다. |
freq |
통계를 계산하기 전에 데이터를 확인하는 데 사용하는 DateOffset 개체 또는 문자열 빈도로 지정됩니다. |
center |
center 매개변수는 창의 중앙에 있는 모든 레이블을 설정합니다. |
win_type |
창 유형을 지정합니다. |
on |
인덱스 대신 롤링 창을 결정해야 하는 데이터 프레임 열에 사용됩니다. |
closed |
오른쪽, 왼쪽, 둘 다 또는 양쪽 끝점에서 간격을 닫습니다. |
axis |
기본적으로 0이지만 int 또는 문자열일 수 있습니다. |
Pandas의 GroupBy 개체에 대한 유용한 롤링 기능
rolling() 함수의 사용법을 배우려면 일부 샘플 데이터가 포함된 데이터 프레임이 있어야 합니다. 다음과 같은 데이터 프레임이 있습니다. 같은 것을 사용할 수도 있습니다.
예제 코드:
import pandas as pd
n = range(0, 6)
id = ["a", "a", "a", "b", "b", "b"]
df = pd.DataFrame(zip(id, n), columns=["id", "n"])
df.set_index("id", inplace=True)
df
출력:
| id | n |
| ---- | ---- |
| a | 0 |
| a | 1 |
| a | 2 |
| b | 3 |
| b | 4 |
| b | 5 |
위의 코드 스니펫에서 데이터 프레임과 함께 작동하도록 pandas 라이브러리를 가져왔습니다. 그런 다음 range() 함수를 사용하여 일련의 숫자를 얻었습니다. 기본적으로 0부터 시작하여 지정된 숫자 이전에 끝나고 1씩 증가합니다.
range() 함수에 대한 start, stop 및 step 매개 변수의 기본값을 변경할 수 있습니다(원하는 경우). 다음으로 pd.DataFame()을 사용하여 데이터 프레임으로 변환한 id라는 목록이 있습니다. 이 목록은 데이터와 열 이름 목록을 가져옵니다.
여기서 zip() 함수는 0 이상이 될 수 있는 반복 가능 항목을 취하고 모든 반복 가능 항목의 값을 매핑하고 단일 반복자 객체를 반환합니다. set_index()는 id를 인덱스로 만드는 데 사용되며 inplace 속성은 True로 설정된 경우 데이터 프레임 내에서 변경 사항이 적용됨을 의미합니다.
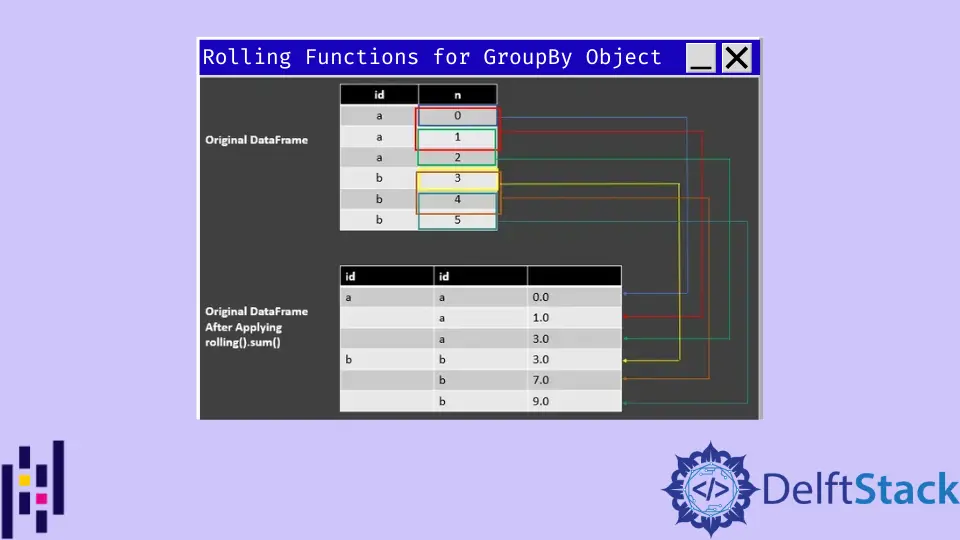
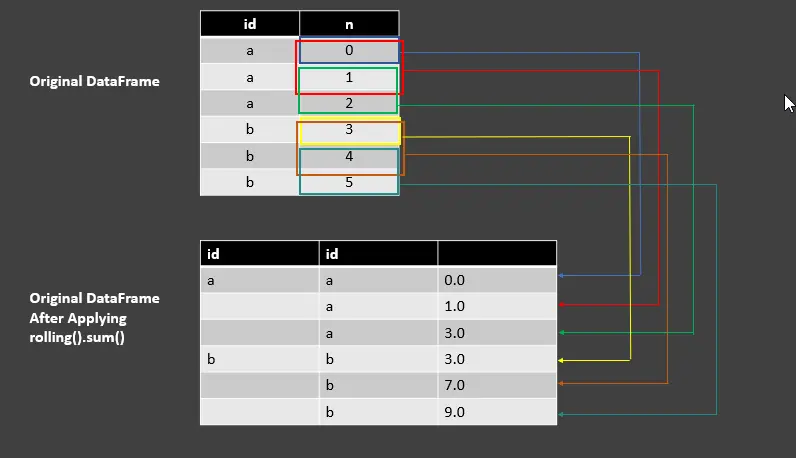
Pandas의 GroupBy 객체에 rolling().sum() 함수 사용
예제 코드:
df_rolling_sum = df.groupby("id")["n"].rolling(2, min_periods=1).sum()
df_rolling_sum
출력:
| id | id | |
| ---- | ---- | ---- |
| a | a | 0.0 |
| | a | 1.0 |
| | a | 3.0 |
| b | b | 3.0 |
| | b | 7.0 |
| | b | 9.0 |
여기에서 groupby() 함수를 사용하여 특정 값의 그룹을 만들고 작업을 수행했습니다. 이 기능은 개체를 분할하고 원하는 작업을 적용하고 그룹을 만들기 위해 결합합니다.
위의 코드 행은 n 열에 대한 합계를 수행하기 위해 min_periods=1로 2의 창 길이를 수행합니다. rolling().sum()을 사용한 출력을 이해하려면 다음 스크린샷을 참조하십시오.
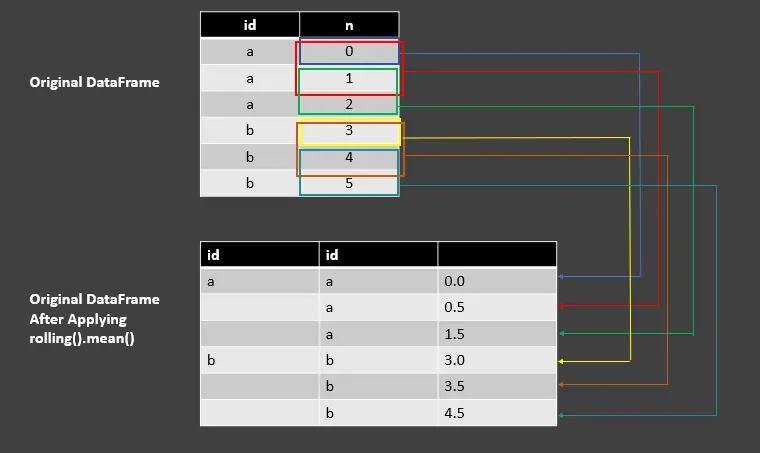
Pandas의 GroupBy 객체에 rolling().mean() 함수 사용
예제 코드:
df_rolling_mean = df.groupby("id")["n"].rolling(2, min_periods=1).mean()
df_rolling_mean
출력:
| id | id | |
| ---- | ---- | ---- |
| a | a | 0.0 |
| | a | 0.5 |
| | a | 1.5 |
| b | b | 3.0 |
| | b | 3.5 |
| | b | 4.5 |
이 예제는 mean()의 차이를 제외하고 rolling().sum()을 사용했던 이전 코드 펜스와 유사합니다. 여기서는 합계를 값 수로 나눈 값으로 계산된 창에서 두 값의 평균을 계산합니다.
이해하려면 다음 이미지를 참조하십시오.
각 그룹의 첫 번째 값은 그 이전에 값이 없기 때문에 출력 열에 있는 그대로이지만 min_periods 매개변수를 생략하면 NaN이 됩니다. 다음 예를 참조하십시오.
예제 코드:
df_rolling_mean = df.groupby("id")["n"].rolling(2).mean()
df_rolling_mean
출력:
| id | id | |
| ---- | ---- | ---- |
| a | a | NaN |
| | a | 0.5 |
| | a | 1.5 |
| b | b | NaN |
| | b | 3.5 |
| | b | 4.5 |
Pandas의 GroupBy 개체에 대한 여러 열에서 rolling().agg() 함수 사용
예제 코드:
import pandas as pd
n1 = range(0, 6)
n2 = range(0, 6)
id = ["a", "a", "a", "b", "b", "b"]
df = pd.DataFrame(zip(id, n1, n1), columns=["id", "n1", "n2"])
df.set_index("id", inplace=True)
df_rolling_mean_sum = (
df.groupby("id").rolling(2, min_periods=1).agg({"n1": "sum", "n2": "mean"})
)
print(df_rolling_mean_sum)
출력:
| id | id | n1 | n2 |
| ---- | ---- | ---- | ---- |
| a | a | 0.0 | 0.0 |
| | a | 1.0 | 0.5 |
| | a | 3.0 | 1.5 |
| b | b | 3.0 | 3.0 |
| | b | 7.0 | 3.5 |
| | b | 9.0 | 4.5 |
여기에는 n1과 n2라는 두 개의 열이 있습니다. 여기서 agg() 메서드를 사용하여 n1에 sum을 적용하고 n2에 mean을 적용합니다(위 출력에서 제공됨). ).
DataFrame.cumsum() 함수를 사용하여 Pandas의 GroupBy 개체에 대한 롤링 합계 가져오기
이제 다음과 같은 롤링 합계를 원한다고 가정합니다.
id n sum
a 0 0
a 1 1
a 2 3
b 3 3
b 4 7
b 5 12
다음 대신:
id n sum
a 0 0.0
a 1 1.0
a 2 3.0
b 3 3.0
b 4 7.0
b 5 9.0
어떻게 할 수 있습니까? 이를 위해 다음과 같이 DataFrame.cumsum()을 사용할 수 있습니다.
예제 코드:
import pandas as pd
n = range(0, 6)
id = ["a", "a", "a", "b", "b", "b"]
df = pd.DataFrame(zip(id, n), columns=["id", "n"])
df.set_index("id", inplace=True)
df_cumsum = df.groupby("id").n.cumsum()
df_cumsum
출력:
| id | |
| ---- | ---- |
| a | 0 |
| a | 1 |
| a | 3 |
| b | 3 |
| b | 7 |
| b | 12 |
DataFrame 또는 Series 축에 대한 누적 합계를 반환하는 DataFrame.cumsum() 메서드를 사용하여 위의 출력을 얻을 수 있습니다.
