Pandas에서 GroupBy 및 집계 여러 열

Pandas 라이브러리는 Python의 강력한 데이터 분석 라이브러리입니다. Python에서 Pandas를 사용하여 데이터 프레임에서 다양한 유형의 조작을 수행할 수 있습니다.
groupby()는 특정 기준에 따라 데이터를 여러 그룹으로 분할하는 방법입니다. 그런 다음 그룹화된 데이터에 대해 특정 작업을 수행할 수 있습니다.
Pandas Python의 여러 열에 groupby() 및 aggregate() 함수 적용
때로는 여러 열의 데이터를 그룹화하고 몇 가지 aggregate() 메서드를 적용해야 합니다. aggregate() 메서드는 여러 행의 값을 결합하고 단일 값을 반환하는 메서드입니다(예: count(), size(), mean(), sum(), mean() 등
다음 코드에는 일부 열에 대한 중복 값이 포함된 학생 데이터가 있습니다. 학생의 이름 및 섹션을 기준으로 데이터를 그룹화하여 총점을 얻으려면 이름과 섹션에 따라 데이터를 그룹화한 다음 aggregate() 방법을 사용하여 총점을 계산합니다.
반환된 결과를 저장하고 표시했습니다.
예제 코드:
# Python 3.x
import pandas as pd
student = {
"Name": ["Jhon", "Alia", "Jhon", "Alia", "Sam", "Smith", "Sam", "Smith"],
"Section": ["A", "A", "A", "A", "B", "B", "B", "B"],
"Course": ["Java", "Java", "Dart", "Dart", "Java", "Java", "Dart", "Dart"],
"Marks": [70, 80, 90, 60, 80, 90, 50, 80],
}
df = pd.DataFrame(student)
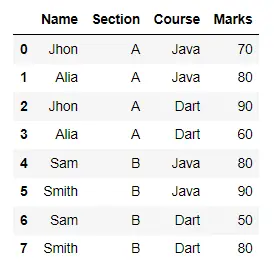
display(df)
result = df.groupby(["Name", "Section"]).aggregate("sum")
display(result)
출력:
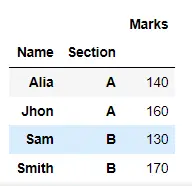
한 번에 여러 집계 작업을 수행할 수도 있습니다. 작업 이름 목록을 aggregate() 메서드에 전달합니다.
여기서는 작업 이름 목록을 전달하여 aggregate() 메서드를 사용하여 학생의 평균 및 총 점수를 한 번에 계산했습니다.
예제 코드:
# Python 3.x
import pandas as pd
student = {
"Name": ["Jhon", "Alia", "Jhon", "Alia", "Sam", "Smith", "Sam", "Smith"],
"Section": ["A", "A", "A", "A", "B", "B", "B", "B"],
"Course": ["Java", "Java", "Dart", "Dart", "Java", "Java", "Dart", "Dart"],
"Marks": [70, 80, 90, 60, 80, 90, 50, 80],
}
df = pd.DataFrame(student)
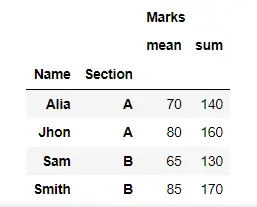
display(df)
result = df.groupby(["Name", "Section"]).aggregate(["mean", "sum"])
display(result)
출력:

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn