Pandas Python에서 groupby() 이후 행 필터링

Pandas는 데이터를 분석하고 조작하는 데 사용되는 Python의 오픈 소스 라이브러리입니다. Pandas의 도움으로 데이터 프레임을 만들고 다양한 작업을 수행하여 데이터를 추출하거나 검색할 수 있습니다.
Pandas 모듈을 사용하여 데이터를 추출, 필터링 및 정렬할 수도 있습니다. 이 기사에서는 groupby() 작업을 수행한 후 데이터 세트에서 행을 필터링하는 방법을 살펴봅니다.
판다 groupby() 메서드
Pandas 모듈의 groupby() 메서드는 데이터를 범주로 정렬하고 추가 작업을 적용하는 데 도움이 됩니다. 이 방법은 데이터를 집계하는 효율적인 방법이기도 합니다.
몇 가지 기준이 정의된 dataframe.groupby()를 사용하여 데이터 프레임의 데이터를 조작할 수 있습니다. 이제 groupby() 메서드를 다음 데이터 프레임에 적용해 보겠습니다.
다음 코드를 사용하여 이 데이터 프레임을 생성합니다.
예제 코드:
import pandas as pd
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Country": ["India", "India", "Pakistan", "America", "America"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data=data)
print(data_frame)
출력:
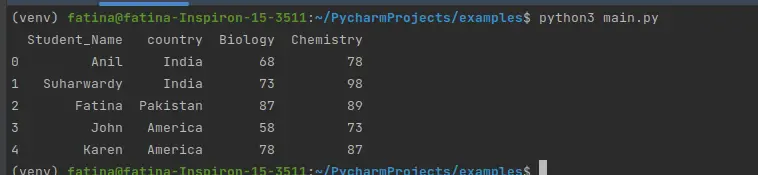
이제 groupby()를 사용하여 이 데이터를 국가별로 그룹화하겠습니다.
다음 스니펫에서는 각 항목을 범주로 정렬하는 데 사용되는 groupby() 메서드에 대한 기준을 추가했습니다. 그런 다음 루프를 사용하여 그룹화된 데이터를 인쇄합니다.
예제 코드:
import pandas as pd
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Country": ["India", "India", "Pakistan", "America", "America"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data=data)
grouped = data_frame.groupby("Country")
for one in grouped:
print(one, "\n")
출력:
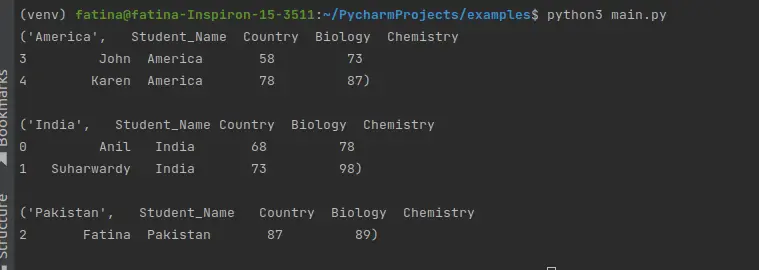
Pandas Python에서 groupby() 뒤의 행 필터링
이제 groupby()의 작동 방식을 이해했으므로 그룹화된 데이터에 필터를 추가로 적용하는 방법을 계속 알 수 있습니다. 위의 예제 데이터 프레임을 계속 사용하여 생물학에서 73을 획득한 학생에 대한 국가 및 기타 정보를 필터링한다고 가정합니다.
groupby() 바로 다음에 apply() 메서드를 사용하여 이를 필터링합니다.
예제 코드:
import pandas as pd
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Country": ["India", "India", "Pakistan", "America", "America"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data=data)
grouped = data_frame.groupby("Country").apply(lambda x: x[x["Biology"] == 73])
print(grouped)
출력:
-method---output-1.webp)
apply() 메서드에서 국가를 지정하여 특정 국가에 속한 모든 학생 세부 정보를 인쇄할 수도 있습니다. 이 코드는 데이터 프레임에서 두 행을 반환합니다.
예제 코드:
import pandas as pd
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Country": ["India", "India", "Pakistan", "America", "America"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data=data)
grouped = data_frame.groupby("Country").apply(lambda x: x[x["Country"] == "America"])
print(grouped)
출력:
-method---output-2.webp)
결론적으로 Pandas 모듈은 포괄적인 도구와 스마트한 방법으로 데이터 조작을 충분히 쉽고 효율적으로 만들었습니다. 위에서 자세히 설명한 Pandas groupby() 및 apply() 메서드를 사용하여 데이터 프레임을 쉽게 그룹화하고 필터링할 수 있습니다.
그러나 Pandas는 매우 광범위한 모듈이므로 데이터를 필터링하고 정렬하는 방법은 여러 가지가 있다는 점에 유의해야 합니다. 우리는 항상 고유한 개발 요구 사항에 가장 적합한 것을 선택할 수 있습니다.

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn