Pandas Python で groupby() の後に行をフィルター処理する

Pandas は、データの分析と操作に使用される Python のオープンソース ライブラリです。 Pandas の助けを借りて、データ フレームを作成し、それらに対してさまざまな操作を実行して、データを抽出または取得できます。
Pandas モジュールを使用することで、データの抽出、フィルタリング、および並べ替えも行うことができます。 この記事では、groupby() 操作を実行した後に、データ セット内の行をフィルター処理する方法について説明します。
パンダ groupby() メソッド
Pandas モジュールの groupby() メソッドは、データをカテゴリに分類し、さらにそれらに操作を適用するのに役立ちます。 この方法は、データを集計する効率的な方法でもあります。
dataframe.groupby() を使用して、いくつかの基準を定義して、データ フレーム内のデータを操作できます。 次のデータフレームに groupby() メソッドを適用しましょう。
次のコードを使用して、このデータフレームを生成します。
コード例:
import pandas as pd
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Country": ["India", "India", "Pakistan", "America", "America"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data=data)
print(data_frame)
出力:
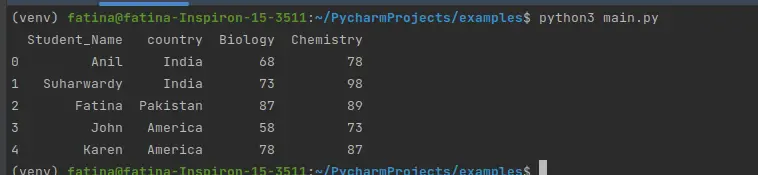
それでは、groupby() を使用して、このデータを国別にグループ化してみましょう。
次のスニペットでは、groupby() メソッドの基準を追加しました。これは、各エントリをカテゴリに分類するために使用されます。 次に、ループを使用してグループ化されたデータを出力します。
コード例:
import pandas as pd
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Country": ["India", "India", "Pakistan", "America", "America"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data=data)
grouped = data_frame.groupby("Country")
for one in grouped:
print(one, "\n")
出力:
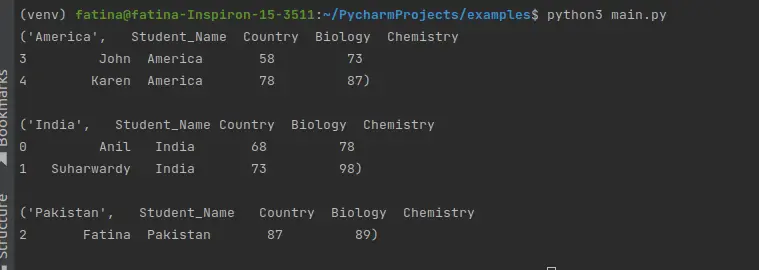
Pandas Python で groupby() の後に行をフィルター処理する
groupby() がどのように機能するかを理解したので、グループ化されたデータにさらにフィルターを適用する方法を引き続き知ることができます。 上記のデータフレームの例を続けて、生物学で 73 を獲得した学生に関する国やその他の情報を除外したいとします。
groupby() の直後に apply() メソッドを使用してこれを除外します。
コード例:
import pandas as pd
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Country": ["India", "India", "Pakistan", "America", "America"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data=data)
grouped = data_frame.groupby("Country").apply(lambda x: x[x["Biology"] == 73])
print(grouped)
出力:
-method---output-1.webp)
apply() メソッドで国を指定することにより、特定の国に属するすべての学生の詳細を出力することもできます。 このコードは、データフレームから 2つの行を返します。
コード例:
import pandas as pd
data = {
"Student_Name": ["Anil", "Suharwardy", "Fatina", "John", "Karen"],
"Country": ["India", "India", "Pakistan", "America", "America"],
"Biology": [68, 73, 87, 58, 78],
"Chemistry": [78, 98, 89, 73, 87],
}
data_frame = pd.DataFrame(data=data)
grouped = data_frame.groupby("Country").apply(lambda x: x[x["Country"] == "America"])
print(grouped)
出力:
-method---output-2.webp)
結論として、Pandas モジュールは、その包括的なツールとスマートな方法により、データの操作を十分に簡単かつ効率的にしました。 データ フレームは、上記で詳しく説明した Pandas の groupby() および apply() メソッドを使用して、簡単にグループ化およびフィルタリングできます。
ただし、Pandas は非常に広範なモジュールであるため、データをフィルター処理して並べ替えるには複数の方法があることに注意することが重要です。 当社独自の開発要件に最も適したものをいつでも選択できます。

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn