Einführung in nützliche rollierende Funktionen für GroupBy-Objekte in Pandas
- Pandas Rolling vs. Rolling Window
- Rolling-Window-Funktion
-
Syntax und Arbeitsprozess der Funktion
dataframe.rolling() - Nützliche Rolling-Funktionen für GroupBy-Objekte in Pandas
-
Verwenden Sie die Funktion
rolling().sum()für das GroupBy-Objekt in Pandas -
Verwenden Sie die Funktion
rolling().mean()für das GroupBy-Objekt in Pandas -
Verwenden Sie die Funktion
rolling().agg()für mehrere Spalten für das GroupBy-Objekt in Pandas
Heute werden wir den Unterschied zwischen den Rolling- und Rolling-Window-Funktionen von Pandas untersuchen. Wir werden etwas über die Rolling-Window-Funktion, ihre Syntax und ihren Arbeitsprozess lernen, was uns zu verschiedenen Codebeispielen führt, die verschiedene rolling-Funktionen für die Gruppe durch ein Objekt in Pandas demonstrieren.
Pandas Rolling vs. Rolling Window
Python hat verschiedene datenzentrierte Bibliotheken/Pakete, und Pandas ist eines davon. Wir verwenden verschiedene nützliche Funktionen dieser Bibliothek, und eine davon ist als rolling()-Funktion bekannt.
Die Funktion dataframe.rolling() führt komplexe Berechnungen mit den bereitgestellten Daten durch. Es hat auch eine Funktion namens Rolling Window, die wir gleich in diesem Abschnitt anhand eines Beispiels sehen werden.
Die rollende Fensterfunktion funktioniert hauptsächlich mit Zeitreihen und Signalverarbeitungsdaten. Wir verwenden es, um Berechnungen mit den bereitgestellten Eingabedaten in einer bestimmten Objektserie durchzuführen.
Nehmen wir zum Beispiel an, dass w die Fenstergröße und t die Zeit ist, sodass wir eine Fenstergröße w zur Zeit t nehmen können, um gewünschte mathematische Operationen auf die Daten anzuwenden. Die Fenstergröße w bedeutet w aufeinanderfolgende Werte zu einem Zeitpunkt t; Denken Sie daran, dass alle w-Werte zu einem Zeitpunkt t gleich gewichtet werden.
Rolling-Window-Funktion
Das rollierende Fenster bedeutet, dass Berechnungen für die bereitgestellten Daten vom angegebenen Datum bis zu einer Verschiebung des rollierenden Fensters durchgeführt werden. Zum Beispiel befindet sich jeder Mitarbeiter im rollierenden 1-Monats-Fenster, was bedeutet, dass er / er sein Gehalt am 1. jedes Monats eines jeden Jahres erhält.
Das erste Gehalt ist am 1. Januar, das zweite am 1. Februar und das dritte am 1. März. Dieser Prozess wird fortgesetzt, bis jeder Mitarbeiter am 1. Dezember sein 12. Gehalt erhält; dieser Vorgang wird jährlich wiederholt.
Wir können also sagen, dass die Rolling-Window-Funktion relativ zum ersten angegebenen Datum ist und sich automatisch mit einer bestimmten Rolling-Window-Zeit vorwärts bewegt. In unserem Szenario handelt es sich um ein rollierendes Fenster von 1 Monat.
Beachten Sie, dass das rollende Fenster eine feste Größe hat, während das expandierende Fenster nur einen festen Startpunkt hat; es kann erweitert werden, um Daten aufzunehmen, wenn diese verfügbar sind. Den Unterschied können Sie hier nachlesen.
Syntax und Arbeitsprozess der Funktion dataframe.rolling()
Die Funktion dataframe.rolling() liefert Elemente einer rollierenden Fensterzählung. Das Konzept von dataframe.rolling() ist dasselbe wie bei einem allgemeinen rollenden Fenster, bei dem ein Benutzer nur einmal die gewichtete Fenstergröße (w) angibt und einige Operationen ausführt.
Die Syntax von dataframe.rolling() ist wie folgt:
DataFrame.rolling(window, min_periods=None, freq=None, center=False, win_type=None, on=None, axis=0, closed=None)
Es kann die folgenden Parameter annehmen.
| Parameter | Beschreibung |
|---|---|
window |
Es ist die Größe des sich bewegenden Fensters. Es hat mehrere Werte/Beobachtungen, die für Berechnungen verwendet werden sollen. |
min_periods |
Es zeigt die geringste Anzahl von Werten/Beobachtungen in einem Fenster, die einen Wert haben müssen; andernfalls wäre die Ausgabe NA. |
freq |
Es wird als DateOffset-Objekt oder Zeichenfolgenhäufigkeit angegeben, die wir verwenden, um Daten vor der Berechnung der Statistik zu bestätigen. |
center |
Der Parameter center setzt alle Labels in die Mitte des Fensters. |
win_type |
Es gibt den Typ Fenster an. |
on |
Es wird für eine Datenrahmenspalte verwendet, in der wir anstelle eines Indexes ein rollierendes Fenster bestimmen sollen. |
closed |
Es macht ein Intervall, das am rechten, linken, keinem oder beiden Endpunkten geschlossen ist. |
axis |
Standardmäßig ist es 0, aber es kann ein Int oder String sein. |
Nützliche Rolling-Funktionen für GroupBy-Objekte in Pandas
Wir müssen einen Datenrahmen haben, der einige Beispieldaten enthält, um die Verwendung der Funktion rolling() zu lernen. Wir haben einen Datenrahmen wie folgt; Sie können auch die gleichen verwenden.
Beispielcode:
import pandas as pd
n = range(0, 6)
id = ["a", "a", "a", "b", "b", "b"]
df = pd.DataFrame(zip(id, n), columns=["id", "n"])
df.set_index("id", inplace=True)
df
AUSGANG:
| id | n |
| ---- | ---- |
| a | 0 |
| a | 1 |
| a | 2 |
| b | 3 |
| b | 4 |
| b | 5 |
Wir haben die pandas-Bibliothek importiert, um mit dem Datenrahmen im obigen Code-Snippet zu arbeiten. Dann haben wir die Funktion range() verwendet, um eine Zahlenfolge zu erhalten; standardmäßig beginnt es bei 0, endet vor der angegebenen Zahl und erhöht sich um 1.
Wir können die Standardwerte der Parameter start, stop und step für die Funktion range() ändern (wenn wir wollen). Als nächstes haben wir eine Liste namens id, die wir mit pd.DataFame() in einen Datenrahmen konvertiert haben, der die Daten und eine Liste von Spaltennamen enthält.
Hier nimmt die Funktion zip() Iterables, die null oder mehr sein können, bildet Werte von allen Iterables ab und gibt ein einzelnes Iterator-Objekt zurück. Das set_index() wird verwendet, um id als Index zu machen, während das inplace-Attribut bedeutet, dass Änderungen innerhalb des Datenrahmens wirksam werden, wenn es auf True gesetzt ist.
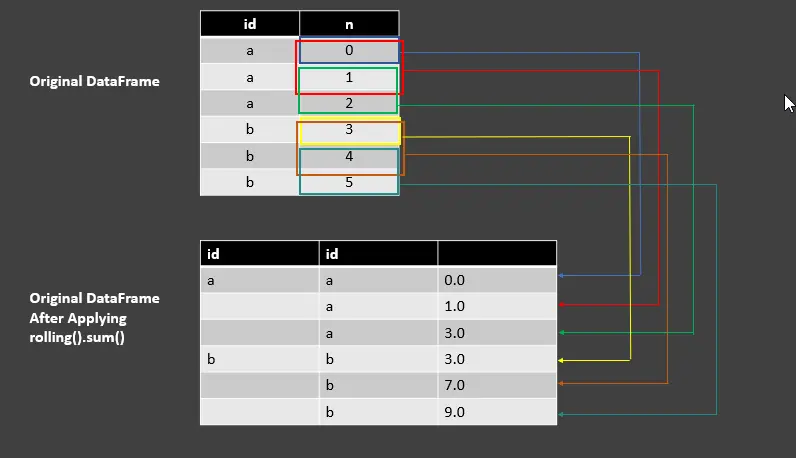
Verwenden Sie die Funktion rolling().sum() für das GroupBy-Objekt in Pandas
Beispielcode:
df_rolling_sum = df.groupby("id")["n"].rolling(2, min_periods=1).sum()
df_rolling_sum
AUSGANG:
| id | id | |
| ---- | ---- | ---- |
| a | a | 0.0 |
| | a | 1.0 |
| | a | 3.0 |
| b | b | 3.0 |
| | b | 7.0 |
| | b | 9.0 |
Hier haben wir die Funktion groupby() verwendet, um Gruppen bestimmter Werte zu erstellen und Operationen mit ihnen auszuführen. Diese Funktion teilt ein Objekt, wendet die gewünschten Operationen an und kombiniert sie zu einer Gruppe.
Die obige Codezeile hat eine Fensterlänge von 2 mit min_periods=1, um die Summe in Spalte n auszuführen. Sehen Sie sich den folgenden Screenshot an, um die Ausgabe mit rolling().sum() zu verstehen.
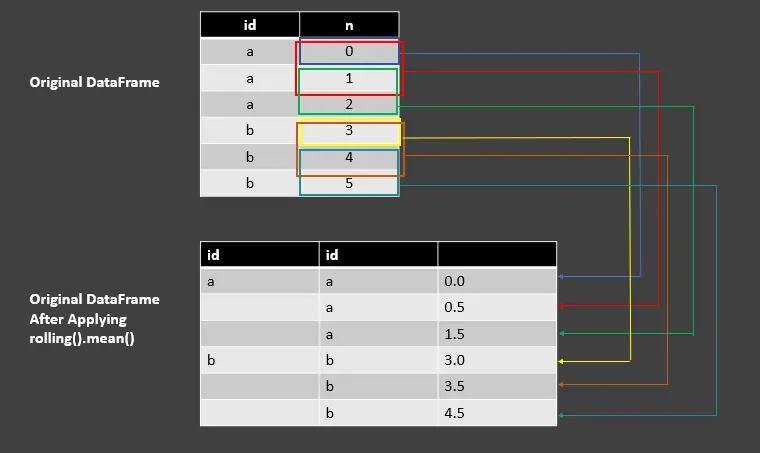
Verwenden Sie die Funktion rolling().mean() für das GroupBy-Objekt in Pandas
Beispielcode:
df_rolling_mean = df.groupby("id")["n"].rolling(2, min_periods=1).mean()
df_rolling_mean
AUSGANG:
| id | id | |
| ---- | ---- | ---- |
| a | a | 0.0 |
| | a | 0.5 |
| | a | 1.5 |
| b | b | 3.0 |
| | b | 3.5 |
| | b | 4.5 |
Dieses Beispiel ähnelt dem vorherigen Code Fence, bei dem wir rolling().sum() verwendet haben, mit Ausnahme des Unterschieds von mean(). Hier berechnen wir den Mittelwert von zwei Werten in einem Fenster, das aus der Summe dividiert durch die Anzahl der Werte berechnet wird.
Sehen Sie sich das folgende Bild an, um es zu verstehen.
Denken Sie daran, dass der erste Wert jeder Gruppe so wäre, wie er in der Ausgabespalte steht, weil wir davor keinen Wert haben, aber wenn wir den Parameter min_periods weglassen, haben wir NaN. Siehe folgendes Beispiel.
Beispielcode:
df_rolling_mean = df.groupby("id")["n"].rolling(2).mean()
df_rolling_mean
AUSGANG:
| id | id | |
| ---- | ---- | ---- |
| a | a | NaN |
| | a | 0.5 |
| | a | 1.5 |
| b | b | NaN |
| | b | 3.5 |
| | b | 4.5 |
Verwenden Sie die Funktion rolling().agg() für mehrere Spalten für das GroupBy-Objekt in Pandas
Beispielcode:
import pandas as pd
n1 = range(0, 6)
n2 = range(0, 6)
id = ["a", "a", "a", "b", "b", "b"]
df = pd.DataFrame(zip(id, n1, n1), columns=["id", "n1", "n2"])
df.set_index("id", inplace=True)
df_rolling_mean_sum = (
df.groupby("id").rolling(2, min_periods=1).agg({"n1": "sum", "n2": "mean"})
)
print(df_rolling_mean_sum)
AUSGANG:
| id | id | n1 | n2 |
| ---- | ---- | ---- | ---- |
| a | a | 0.0 | 0.0 |
| | a | 1.0 | 0.5 |
| | a | 3.0 | 1.5 |
| b | b | 3.0 | 3.0 |
| | b | 7.0 | 3.5 |
| | b | 9.0 | 4.5 |
Hier haben wir zwei Spalten, n1 und n2, für die wir die Methode agg() verwenden, um sum auf n1 und mean auf n2 anzuwenden (wie in der obigen Ausgabe angegeben ).
Verwenden Sie die Funktion DataFrame.cumsum(), um die laufende Summe für das GroupBy-Objekt in Pandas zu erhalten
Nehmen wir nun an, dass wir eine fortlaufende Summe wie folgt haben möchten:
id n sum
a 0 0
a 1 1
a 2 3
b 3 3
b 4 7
b 5 12
Statt wie folgt:
id n sum
a 0 0.0
a 1 1.0
a 2 3.0
b 3 3.0
b 4 7.0
b 5 9.0
Wie können wir das machen? Dafür können wir DataFrame.cumsum() wie folgt verwenden:
Beispielcode:
import pandas as pd
n = range(0, 6)
id = ["a", "a", "a", "b", "b", "b"]
df = pd.DataFrame(zip(id, n), columns=["id", "n"])
df.set_index("id", inplace=True)
df_cumsum = df.groupby("id").n.cumsum()
df_cumsum
AUSGANG:
| id | |
| ---- | ---- |
| a | 0 |
| a | 1 |
| a | 3 |
| b | 3 |
| b | 7 |
| b | 12 |
Wir können die obige Ausgabe erreichen, indem wir die Methode DataFrame.cumsum() verwenden, die eine kumulative Summierung über die Achse DataFrame oder Series zurückgibt.
