Introducción a las funciones de balanceo útiles para GroupBy Object en Pandas
- Pandas rodando vs ventana rodante
- Función de ventana rodante
-
Sintaxis y Proceso de Trabajo de la Función
dataframe.rolling() - Funciones de balanceo útiles para GroupBy Object en Pandas
-
Utilice la función
rolling().sum()para GroupBy Object en Pandas -
Utilice la función
rolling().mean()para GroupBy Object en Pandas -
Utilice la función
rolling().agg()en varias columnas para GroupBy Object en Pandas
Hoy, exploraremos la diferencia entre las funciones de ventana móvil y móvil de Pandas. Aprenderemos sobre la función de ventana rodante, su sintaxis y su proceso de trabajo, lo que nos llevará a varios ejemplos de código que demuestran diferentes funciones de rotación para el grupo por un objeto en Pandas.
Pandas rodando vs ventana rodante
Python tiene diferentes bibliotecas/paquetes centrados en datos, y Pandas es uno de ellos. Usamos varias funciones útiles de esta biblioteca, y una de ellas se conoce como la función rolling().
La función dataframe.rolling() realiza cálculos complejos sobre los datos proporcionados. También tiene una función llamada ventana móvil que veremos con un ejemplo en un momento en esta sección.
La función de ventana móvil funciona principalmente con series de tiempo y datos de procesamiento de señales. Lo usamos para realizar cálculos sobre los datos de entrada proporcionados en una serie de objetos determinada.
Por ejemplo, suponga que w es el tamaño de la ventana y t es el tiempo, por lo que podemos tomar un tamaño de ventana w en el tiempo t para aplicar las operaciones matemáticas deseadas en los datos. El tamaño de ventana w significa w valores consecutivos en un tiempo t; recuerda, todos los valores de w se ponderan por igual en un tiempo t.
Función de ventana rodante
La ventana móvil significa realizar cálculos sobre los datos proporcionados desde la fecha especificada hasta un cambio de ventana móvil. Por ejemplo, cada miembro del personal está en la ventana móvil de 1 mes, lo que significa que recibirá su salario el 1 de cada mes de cada año.
El primer salario es el 1 de enero, el segundo es el 1 de febrero y el tercero es el 1 de marzo. Este proceso continuará hasta que cada miembro del personal reciba su salario número 12 el 1 de diciembre; este proceso se repetirá anualmente.
Por lo tanto, podemos decir que la función de ventana móvil es relativa a la primera fecha especificada y avanza automáticamente con un tiempo de ventana móvil dado. En nuestro escenario, es una ventana móvil de 1 mes.
Tenga en cuenta que la ventana móvil tiene un tamaño fijo, mientras que la ventana desplegable solo tiene un punto de inicio fijo; puede expandirse para incorporar datos cuando estén disponibles. Puede leer la diferencia aquí.
Sintaxis y Proceso de Trabajo de la Función dataframe.rolling()
La función dataframe.rolling() proporciona elementos de un conteo de ventana móvil. El concepto de dataframe.rolling() es el mismo que una ventana móvil general donde un usuario solo especifica el tamaño de ventana ponderado (w) una vez y realiza algunas operaciones.
La sintaxis de dataframe.rolling() es la siguiente:
DataFrame.rolling(window, min_periods=None, freq=None, center=False, win_type=None, on=None, axis=0, closed=None)
Puede tomar los siguientes parámetros.
| Parámetro | Descripción |
|---|---|
window |
Es el tamaño de la ventana móvil. Tiene varios valores/observaciones que se supone que se utilizan para los cálculos. |
min_periods |
Muestra el menor número de valores/observaciones en una ventana, la cual debe tener un valor; de lo contrario, la salida sería NA. |
freq |
Se especifica como un objeto DateOffset o frecuencia de cadena que usamos para confirmar los datos antes de calcular la estadística. |
center |
El parámetro centro establecerá todas las etiquetas en el centro de la ventana. |
win_type |
Especifica el tipo de ventana. |
on |
Se usa para una columna de marco de datos donde se supone que debemos determinar una ventana móvil en lugar de un índice. |
closed |
Hace un intervalo cerrado a la derecha, a la izquierda, a ninguno o a ambos extremos. |
axis |
De forma predeterminada, es 0, pero puede ser un int o una cadena. |
Funciones de balanceo útiles para GroupBy Object en Pandas
Debemos tener un marco de datos que contenga algunos datos de muestra para aprender el uso de la función rolling(). Tenemos un marco de datos de la siguiente manera; también puede usar el mismo.
Código de ejemplo:
import pandas as pd
n = range(0, 6)
id = ["a", "a", "a", "b", "b", "b"]
df = pd.DataFrame(zip(id, n), columns=["id", "n"])
df.set_index("id", inplace=True)
df
Producción :
| id | n |
| ---- | ---- |
| a | 0 |
| a | 1 |
| a | 2 |
| b | 3 |
| b | 4 |
| b | 5 |
Importamos la biblioteca pandas para trabajar con el marco de datos en el fragmento de código anterior. Luego, usamos la función rango() para obtener una secuencia de números; de forma predeterminada, comienza desde 0, termina antes del número especificado y se incrementa en 1.
Podemos cambiar los valores por defecto de los parámetros start, stop y step para la función range() (si queremos). A continuación, tenemos una lista llamada id que convertimos en un marco de datos usando pd.DataFame(), que toma los datos y una lista de nombres de columnas.
Aquí, la función zip() toma iterables que pueden ser cero o más, asigna valores de todos los iterables y devuelve un único objeto iterador. El set_index() se usa para hacer id como un índice, mientras que el atributo inplace significa que los cambios tendrán efecto dentro del marco de datos si se establece en True.
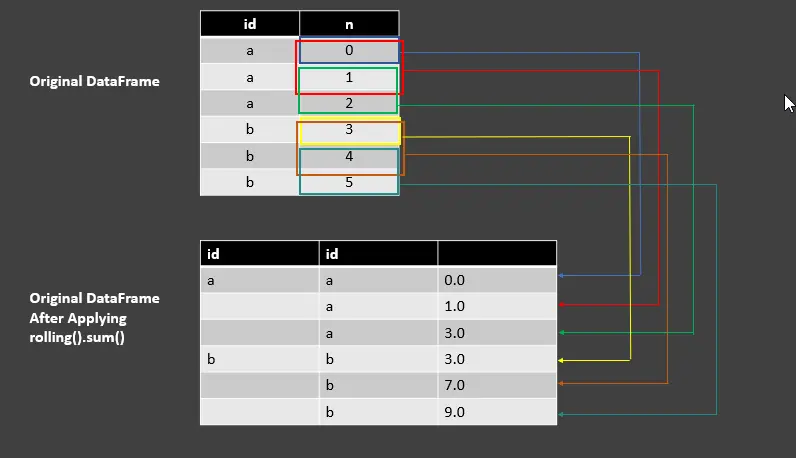
Utilice la función rolling().sum() para GroupBy Object en Pandas
Código de ejemplo:
df_rolling_sum = df.groupby("id")["n"].rolling(2, min_periods=1).sum()
df_rolling_sum
Producción :
| id | id | |
| ---- | ---- | ---- |
| a | a | 0.0 |
| | a | 1.0 |
| | a | 3.0 |
| b | b | 3.0 |
| | b | 7.0 |
| | b | 9.0 |
Aquí, usamos la función groupby() para crear grupos de valores particulares y realizar operaciones en ellos. Esta función divide un objeto, aplica las operaciones deseadas y las combina para formar un grupo.
La línea de códigos anterior tiene una longitud de ventana de 2 con min_periods=1 para realizar la suma en la columna n. Vea la siguiente captura de pantalla para entender la salida usando rolling().sum().
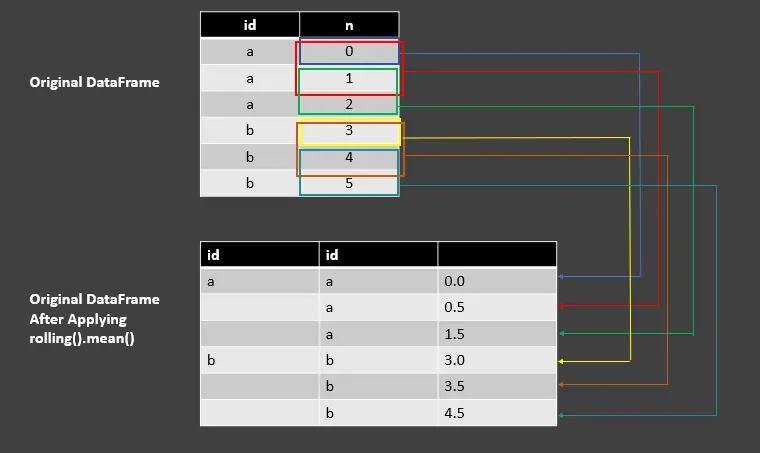
Utilice la función rolling().mean() para GroupBy Object en Pandas
Código de ejemplo:
df_rolling_mean = df.groupby("id")["n"].rolling(2, min_periods=1).mean()
df_rolling_mean
Producción :
| id | id | |
| ---- | ---- | ---- |
| a | a | 0.0 |
| | a | 0.5 |
| | a | 1.5 |
| b | b | 3.0 |
| | b | 3.5 |
| | b | 4.5 |
Este ejemplo es similar al cercado de código anterior en el que usábamos rolling().sum() excepto por la diferencia de mean(). Aquí, estamos calculando la media de dos valores en una ventana calculada por la suma dividida por el número de valores.
Vea la siguiente imagen para entender.
Recuerde, el primer valor de cada grupo sería como está en la columna de salida porque no tenemos ningún valor antes de eso, pero si omitimos el parámetro min_periods, entonces tendremos NaN. Vea el siguiente ejemplo.
Código de ejemplo:
df_rolling_mean = df.groupby("id")["n"].rolling(2).mean()
df_rolling_mean
Producción :
| id | id | |
| ---- | ---- | ---- |
| a | a | NaN |
| | a | 0.5 |
| | a | 1.5 |
| b | b | NaN |
| | b | 3.5 |
| | b | 4.5 |
Utilice la función rolling().agg() en varias columnas para GroupBy Object en Pandas
Código de ejemplo:
import pandas as pd
n1 = range(0, 6)
n2 = range(0, 6)
id = ["a", "a", "a", "b", "b", "b"]
df = pd.DataFrame(zip(id, n1, n1), columns=["id", "n1", "n2"])
df.set_index("id", inplace=True)
df_rolling_mean_sum = (
df.groupby("id").rolling(2, min_periods=1).agg({"n1": "sum", "n2": "mean"})
)
print(df_rolling_mean_sum)
Producción :
| id | id | n1 | n2 |
| ---- | ---- | ---- | ---- |
| a | a | 0.0 | 0.0 |
| | a | 1.0 | 0.5 |
| | a | 3.0 | 1.5 |
| b | b | 3.0 | 3.0 |
| | b | 7.0 | 3.5 |
| | b | 9.0 | 4.5 |
Aquí, tenemos dos columnas, n1 y n2, para las cuales usamos el método agg() para aplicar sum en n1 y mean en n2 (como se indica en la salida anterior ).
Use la función DataFrame.cumsum() para obtener la suma móvil para el objeto GroupBy en Pandas
Ahora, supongamos que queremos tener una suma móvil de la siguiente manera:
id n sum
a 0 0
a 1 1
a 2 3
b 3 3
b 4 7
b 5 12
En lugar de lo siguiente:
id n sum
a 0 0.0
a 1 1.0
a 2 3.0
b 3 3.0
b 4 7.0
b 5 9.0
¿Cómo podemos hacer eso? Para eso, podemos usar DataFrame.cumsum() de la siguiente manera:
Código de ejemplo:
import pandas as pd
n = range(0, 6)
id = ["a", "a", "a", "b", "b", "b"]
df = pd.DataFrame(zip(id, n), columns=["id", "n"])
df.set_index("id", inplace=True)
df_cumsum = df.groupby("id").n.cumsum()
df_cumsum
Producción :
| id | |
| ---- | ---- |
| a | 0 |
| a | 1 |
| a | 3 |
| b | 3 |
| b | 7 |
| b | 12 |
Podemos lograr el resultado anterior usando el método DataFrame.cumsum() que devuelve una suma acumulativa sobre el eje DataFrame o Series.
