Matplotlib에서 로그 축을 그리는 방법
Matplotlib에서 세미 로그 그래프를 그리려면set_xscale()또는set_yscale()및semilogx()또는semilogy()함수를 사용합니다. 로그 축에 두 축을 모두 설정해야하는 경우에는 loglog() 함수를 사용합니다.
set_xscale()또는set_yscale()함수
set_xscale()또는set_yscale()함수를 사용하여 X 축과 Y 축의 스케일링을 각각 설정합니다. 함수에 log또는 symlog스케일을 사용하면 각 축이 로그 스케일로 표시됩니다. set_xscale()또는set_yscale()함수와 함께 log스케일을 사용하면 symlog스케일을 사용하면 양수 값과 음수 값을 모두 허용하면서 음수 값을 관리하는 방법을 통해 양수 값만 허용합니다.
import pandas as pd
import matplotlib.pyplot as plt
date = ["28 April", "27 April", "26 April", "25 April", "24 April", "23 April"]
revenue = [2954222, 2878196, 2804796, 2719896, 2626321, 2544792]
company_data_df = pd.DataFrame({"date": date, "total_revenue": revenue})
company_data = company_data_df.sort_values(by=["total_revenue"])
fig = plt.figure(figsize=(8, 6))
plt.scatter(company_data["total_revenue"], company_data["date"])
plt.plot(company_data["total_revenue"], company_data["date"])
plt.xscale("log")
plt.xlabel("Total Revenue")
plt.ylabel("Date")
plt.title("Company Growth", fontsize=25)
plt.show()
출력:
-function.webp)
Y 축을 따라 로그 축을 설정하기 위해, yscale() 함수를 사용하여 Y 축 스케일을log로 설정할 수 있습니다.
import pandas as pd
import matplotlib.pyplot as plt
date = ["28 April", "27 April", "26 April", "25 April", "24 April", "23 April"]
revenue = [2954222, 2878196, 2804796, 2719896, 2626321, 2544792]
company_data_df = pd.DataFrame({"date": date, "total_revenue": revenue})
company_data = company_data_df.sort_values(by=["total_revenue"])
fig = plt.figure(figsize=(8, 6))
plt.scatter(company_data["date"], company_data["total_revenue"])
plt.plot(company_data["date"], company_data["total_revenue"])
plt.yscale("log")
plt.xlabel("Date")
plt.ylabel("Total Revenue")
plt.title("Company Growth", fontsize=25)
plt.show()
출력:
-function.webp)
두 축을 따라 로그 값을 설정하려면xscale()및yscale()함수를 모두 사용합니다.
import pandas as pd
import matplotlib.pyplot as plt
x = [10, 100, 1000, 10000, 100000]
y = [2, 4, 8, 16, 32]
fig = plt.figure(figsize=(8, 6))
plt.scatter(x, y)
plt.plot(x, y)
plt.grid()
plt.xscale("log")
plt.yscale("log", basey=2)
plt.xlabel("x", fontsize=20)
plt.ylabel("y", fontsize=20)
plt.title("Plot with both log axes", fontsize=25)
plt.show()
출력:
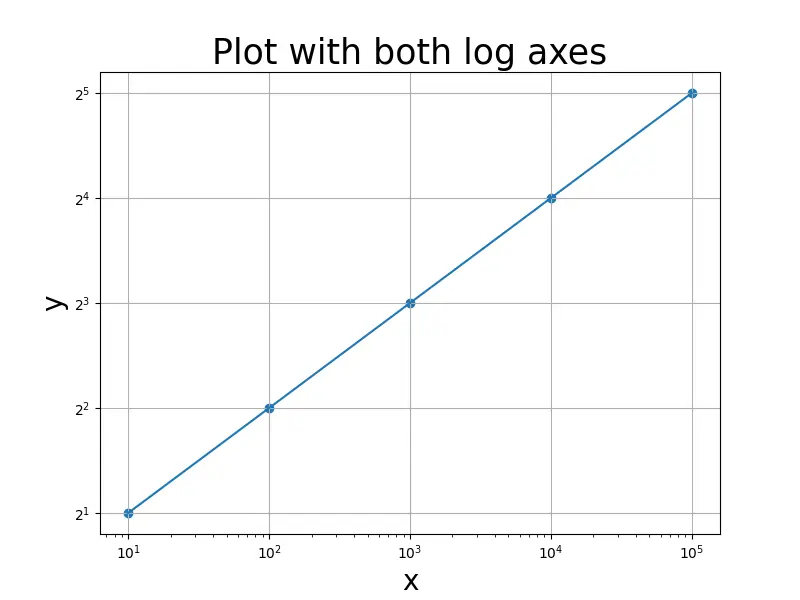
여기서basey=2는 Y 축에 따른2의 로그를 나타냅니다.
semilogx()또는semilogy()함수
semilogx() 함수는 semilogy() 함수는 Y 축을 따라 로그 배율이 지정된 플롯을 만듭니다. 기본 로그의 기본은 10이고 base는 각각semilogx()및semilogy()에 대해basex 및basey 매개 변수로 설정할 수 있습니다.
import pandas as pd
import matplotlib.pyplot as plt
date = ["28 April", "27 April", "26 April", "25 April", "24 April", "23 April"]
revenue = [2954222, 2878196, 2804796, 2719896, 2626321, 2544792]
company_data_df = pd.DataFrame({"date": date, "total_revenue": revenue})
company_data = company_data_df.sort_values(by=["total_revenue"])
fig = plt.figure(figsize=(8, 6))
plt.scatter(company_data["total_revenue"], company_data["date"])
plt.plot(company_data["total_revenue"], company_data["date"])
plt.semilogx()
plt.xlabel("Total Revenue")
plt.ylabel("Date")
plt.title("Company Growth", fontsize=25)
plt.show()
출력:
-function.webp)
두 축을 따라 로그 값을 설정하기 위해semilogx()와semilogy()함수를 모두 사용할 수 있습니다:
import pandas as pd
import matplotlib.pyplot as plt
x = [10, 100, 1000, 10000, 100000]
y = [2, 4, 8, 16, 32]
fig = plt.figure(figsize=(8, 6))
plt.scatter(x, y)
plt.plot(x, y)
plt.grid()
plt.semilogx()
plt.semilogy(basey=2)
plt.xlabel("x", fontsize=20)
plt.ylabel("y", fontsize=20)
plt.title("Plot with both log axes", fontsize=25)
plt.show()
출력:
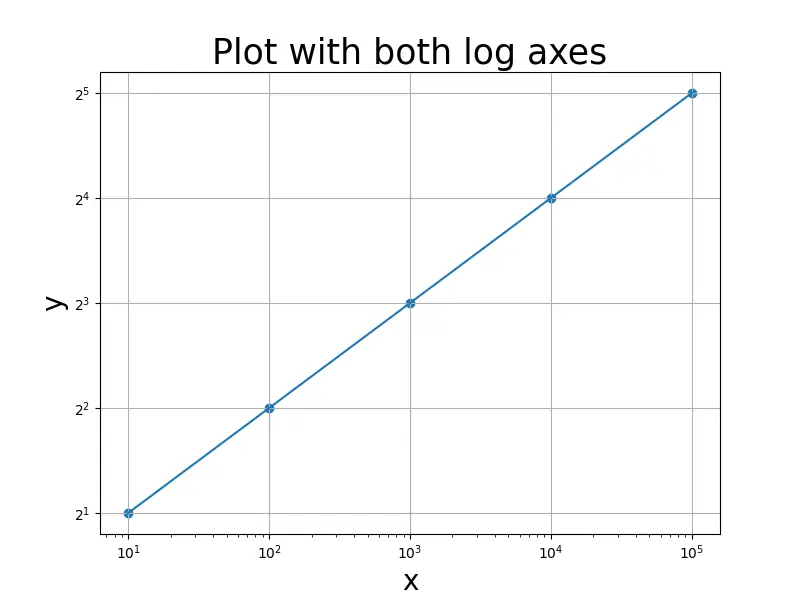
loglog()함수
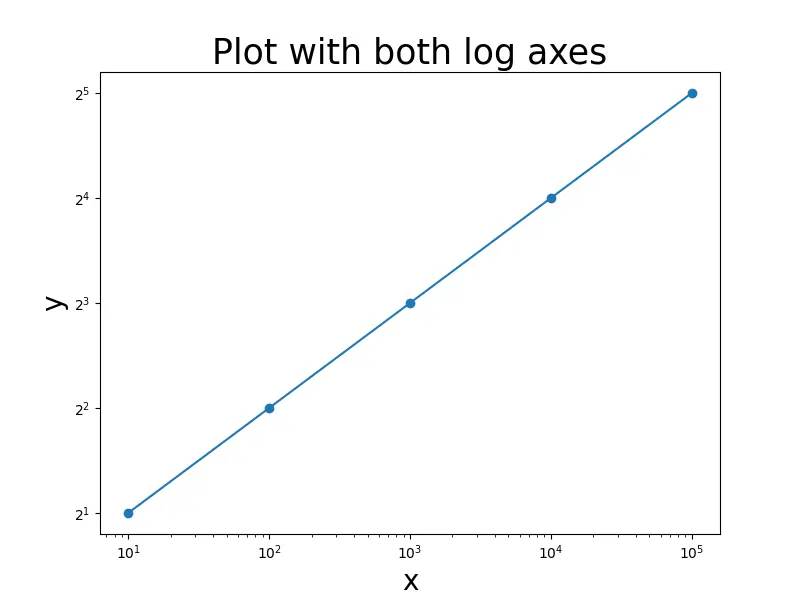
X 축과 Y 축을 따라 로그 스케일링을하려면loglog()함수를 사용할 수도 있습니다. X 축과 Y 축에 대한 로그의 기본은basex와basey 매개 변수에 의해 설정됩니다.
import pandas as pd
import matplotlib.pyplot as plt
x = [10, 100, 1000, 10000, 100000]
y = [2, 4, 8, 16, 32]
fig = plt.figure(figsize=(8, 6))
plt.scatter(x, y)
plt.plot(x, y)
plt.loglog(basex=10, basey=2)
plt.xlabel("x", fontsize=20)
plt.ylabel("y", fontsize=20)
plt.title("Plot with both log axes", fontsize=25)
plt.show()
출력:

Suraj Joshi is a backend software engineer at Matrice.ai.
LinkedIn