How to Convert PDF to Text in Python
- Convert PDF Into Text in Python With PyPDF2
- Convert PDF Into Text in Python With Aspose
- Convert PDF Into Text in Python With PDFminer
- Conclusion

The Python framework isn’t just for building applications. We can use Python to convert PDF documents into .txt files.
When we convert a PDF file to text, the page’s contents become editable, something that’s impossible with PDF files. There are different libraries we can employ to convert PDF to text. Let us try a few.
Convert PDF Into Text in Python With PyPDF2
The first method we will work on is the PyPDF2 library. We will install it using pip install PyPDF2 inside the terminal.
Once that is done, we will create a new file and name it new.py. Next, we will navigate to the file and type in these codes.
Code Snippet- new.py:
import PyPDF2
pdfFileObj = open(r"C:\Users\HP\Desktop\BOOKS\Ching.pdf", "rb")
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
print(pdfReader.numPages)
pageObj = pdfReader.getPage(0)
print(pageObj.extractText())
pdfFileObj.close()
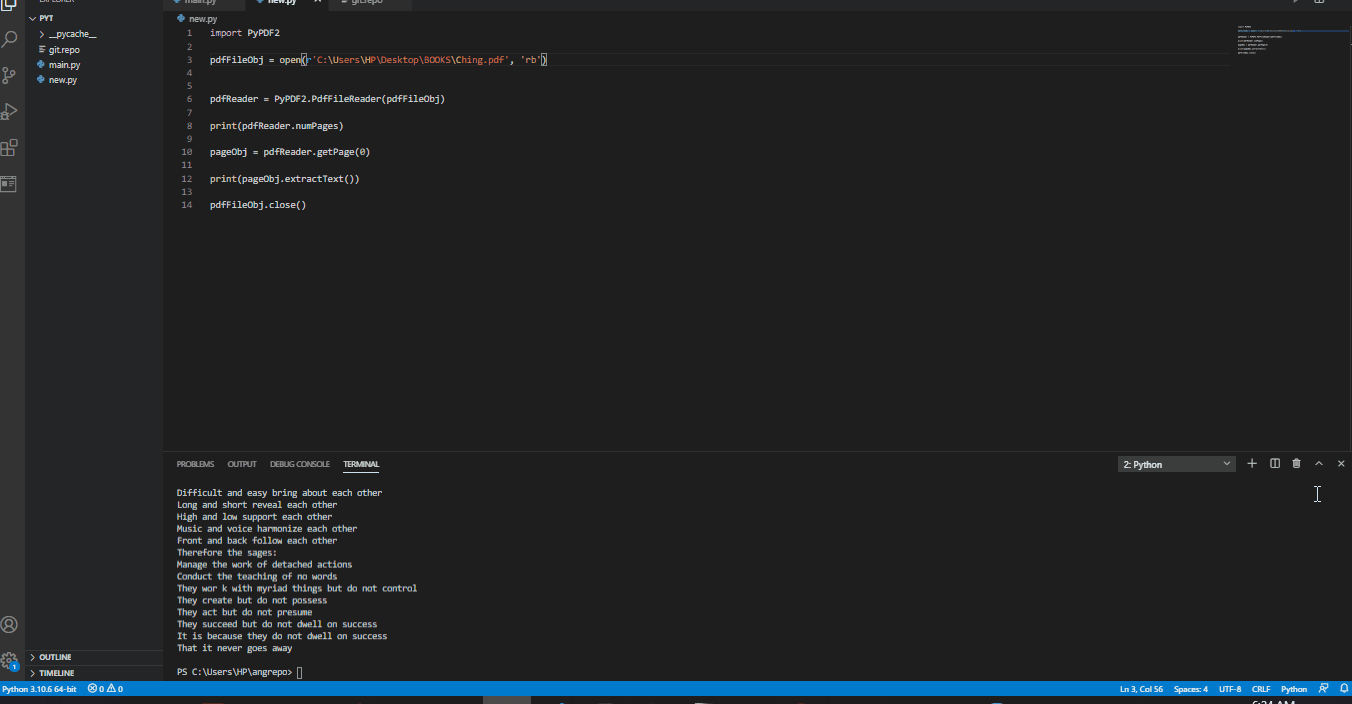
After you run this code, please wait a few moments. You should see the plain text inside the terminal, and then you can copy and paste it inside a Word document or Notepad.
Output:
Convert PDF Into Text in Python With Aspose
The Aspose PDF to text converter for Python offers a shorter code snippet than PyPDF2, but it is just as efficient. Also, Aspose creates the text into a .txt file, unlike the first example that produces the text contents inside the terminal.
We will install Aspose from our terminal with: pip install aspose-words. After installation, create a new file that will house the codes, then put in these snippets.
Code Snippet- new.py:
import aspose.words as aw
doc = aw.Document(r"C:\Users\HP\Desktop\BOOKS\Ching.pdf")
doc.save(r"C:\Users\HP\Desktop\BOOKS\text\doc.txt")
After we import Aspose, we declare the path of the file we want to convert to text. Then, we declare the destination path of the .txt file inside doc.save.
Output:
Convert PDF Into Text in Python With PDFminer
Finally, we will extract text from a PDF with PDFminer. We will observe that PDFminer extracts more texts than PyPDF and requires less code.
Install PDFminer by typing pip install pdfminer.six inside the terminal. After installation, create a new Python file, name it new.py or any name of your choice, and type in these codes.
from pdfminer.high_level import extract_text
text = extract_text(r"C:\Users\HP\Desktop\BOOKS\Ching.pdf")
print(repr(text))
After a few moments, you will see the texts inside your terminal. Then you can copy it from there to a document.
Output:
Conclusion
Most of us usually fancy going online to convert PDF files into texts, but discovering that we could do this with Python, can save us the stress of going online and also helps us deal with the risk of leaking sensitive data on the web.

Fisayo is a tech expert and enthusiast who loves to solve problems, seek new challenges and aim to spread the knowledge of what she has learned across the globe.
LinkedIn