How to Convert Unicode to ASCII in Python

With this article, we will learn how to encode Unicode into bytes, see the different ways to encode the system and convert Unicode to ASCII in Python.
Convert Unicode to ASCII in Python
The basic problem in Python 3 strings are composed of characters; we do not have a character type in Python, but they contain Unicode characters.
If we say a = 'abcd' and we check its length using the len() function, then we got 4 as well as we declare s='שלום' that means hello, and this is the word in the Hebrew language. These lengths would be the same, which is great because both variables have four characters.
>>a='abcd'
>>len(a)
4
>>s='שלום'
>>len(s)
4
The fact that behind the scenes is a different number of bytes is irrelevant to this question here, the len() is measuring the number of characters, not the number of bytes, but of course, behind the scenes, UTF-8 Unicode characters and a UTF-8 encoding are using more bytes.
How can we then turn our string into the bytes that we need? Well, we can use s.encode(), and if we do this, it returns a byte string that would be eight bytes that we need to create the word שלום in Hebrew.
>>s.encode()
b'\xd7\xa9\xd7\x9c\xd7\x95\xd7\x9d'
>>'abcd'.encode()
b'abcd'
Now we will take a Unicode string and turn it into a byte string, but it is even more complex than that because we know what this string שלום and we want to get back the bytes not representing underlying bytes for Unicode. We want to get back the underlying bytes for a different encoding system.
For example, we use iso-8859-8, which is one type of encoding that you might have heard that was used a lot in Western Europe, and that allowed us to have one byte with all the different characters we needed for a particular language, so if we need to take a string and turn it into an encoding that is not Unicode.
>>s.encode('iso-8859-8')
b'\xf9\xec\xe5\xed'
Let’s see what happens if we have something from a different language, as we say s='北京' that is Beijing, and if we go to encode it, then we get back a byte string.
We see here we have six bytes back because each of these Chinese characters is represented by three bytes; this is our variable length encoding that happens with UTF-8.
>>s='北京'
>>s.encode()
b'\xe5\x8c\x97\xe4\xba\xac'
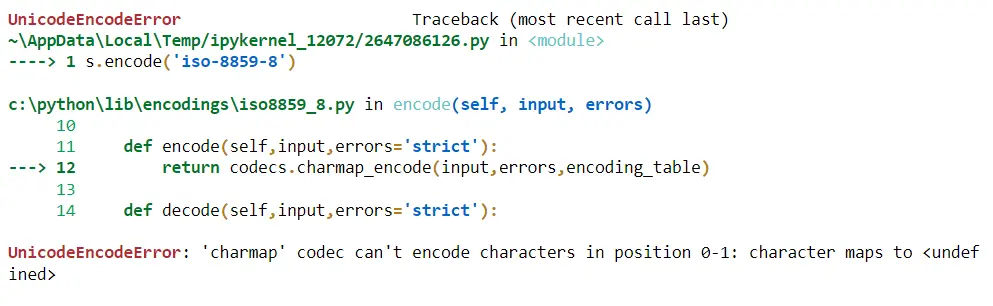
Now we want to encode 北京 using iso-8859-8, and when we execute this, we get a UnicodeEncodeError, meaning the encode is saying to us that you want to take these Unicode characters and turn them into the bytes for the iso-8859-8 encoding that’s not allowed.
s.encode("iso-8859-8")
If we join the English words with this, it will also fail because anywhere we might have an error, it will fail, but we can add a parameter that helps ignore errors.
>>s='I often go to 北京'
>>s.encode('iso-8859-8',errors='ignore')
b'I often go to '
You can use this if you have a whole bunch of text and are okay losing the Unicode characters.
Let’s take a look at the help(s.encode) that is by default equal to strict, but it can be a few different things, so if we use the replace value to errors, it does not really know how to replace, so it is just going to use question marks.
help(s.encode)

>>s='I often go to 北京'
>>s.encode('iso-8859-8',errors='replace')
b'I often go to ??'
When we use xmlcharrefreplace, we get back the XML entities that have to do with those Unicode characters, so if you are going to paste this into either an XML document or maybe into HTML, then this will work.
>>s.encode('iso-8859-8',errors='xmlcharrefreplace')
b'I often go to 北京'
It depends on your needs; if you translate Unicode characters into bytes, that is typical because you are going to send them over the network, or you are dealing with some other sort of encoding system.
If you are a beginner and do not want to go into detail, install a Python package called unidecode using the following command.
It will convert Unicode to ASCII directly; it will be helpful when working with an application where you need to convert Unicode to ASCII.
from unidecode import unidecode
unidecode(u"北京")
# Output: 'Bei Jing'

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn