Convertir Unicode a ASCII en Python

Con este artículo, aprenderemos cómo codificar Unicode en bytes, veremos las diferentes formas de codificar el sistema y convertir Unicode a ASCII en Python.
Convertir Unicode a ASCII en Python
El problema básico en Python 3 las cadenas se componen de caracteres; no tenemos un tipo de carácter en Python, pero contienen caracteres Unicode.
Si decimos a = 'abcd' y verificamos su longitud usando la función len(), entonces obtuvimos 4 y declaramos s='שלום' que significa hola, y esta es la palabra en el idioma hebreo. Estas longitudes serían las mismas, lo cual es genial porque ambas variables tienen cuatro caracteres.
>>a='abcd'
>>len(a)
4
>>s='שלום'
>>len(s)
4
El hecho de que detrás de escena hay una cantidad diferente de bytes es irrelevante para esta pregunta aquí, el len() está midiendo la cantidad de caracteres, no la cantidad de bytes, pero por supuesto, detrás de escena, UTF-8 Unicode los caracteres y la codificación UTF-8 utilizan más bytes.
¿Cómo podemos convertir nuestra cadena en los bytes que necesitamos? Bueno, podemos usar s.encode(), y si hacemos esto, devuelve una cadena de bytes que serían ocho bytes que necesitamos para crear la palabra שלום en hebreo.
>>s.encode()
b'\xd7\xa9\xd7\x9c\xd7\x95\xd7\x9d'
>>'abcd'.encode()
b'abcd'
Ahora tomaremos una cadena Unicode y la convertiremos en una cadena de bytes, pero es incluso más complejo que eso porque sabemos qué es esta cadena שלום y queremos recuperar los bytes que no representan bytes subyacentes para Unicode. Queremos recuperar los bytes subyacentes para un sistema de codificación diferente.
Por ejemplo, usamos iso-8859-8, que es un tipo de codificación que quizás haya escuchado que se usó mucho en Europa occidental y que nos permitió tener un byte con todos los caracteres diferentes que necesitábamos para un idioma en particular, por lo que si necesitamos tomar una cadena y convertirla en una codificación que no sea Unicode.
>>s.encode('iso-8859-8')
b'\xf9\xec\xe5\xed'
Veamos qué sucede si tenemos algo de un idioma diferente, como decimos s='北京' que es Beijing, y si vamos a codificarlo, obtenemos una cadena de bytes.
Vemos aquí que tenemos seis bytes de regreso porque cada uno de estos caracteres chinos está representado por tres bytes; esta es nuestra codificación de longitud variable que ocurre con UTF-8.
>>s='北京'
>>s.encode()
b'\xe5\x8c\x97\xe4\xba\xac'
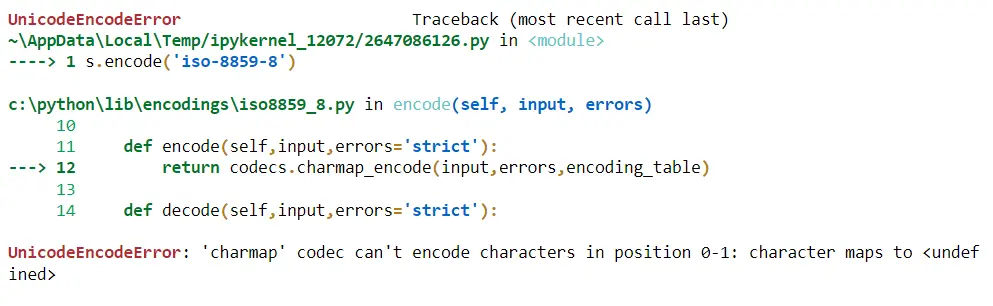
Ahora queremos codificar 北京 usando iso-8859-8, y cuando ejecutamos esto, obtenemos un UnicodeEncodeError, lo que significa que la codificación nos dice que desea tomar estos caracteres Unicode y convertirlos en el bytes para la codificación iso-8859-8 que no está permitida.
s.encode("iso-8859-8")
Si unimos las palabras en inglés con esto, también fallará porque en cualquier lugar que podamos tener un error, fallará, pero podemos agregar un parámetro que ayude a ignorar los errores.
>>s='I often go to 北京'
>>s.encode('iso-8859-8',errors='ignore')
b'I often go to '
Puede usar esto si tiene un montón de texto y está bien perder los caracteres Unicode.
Echemos un vistazo a la ayuda (s.encode) que es por defecto igual a estricto, pero puede ser algunas cosas diferentes, por lo que si usamos el valor reemplazar para errores, no realmente sé cómo reemplazar, por lo que solo usará signos de interrogación.
help(s.encode)

>>s='I often go to 北京'
>>s.encode('iso-8859-8',errors='replace')
b'I often go to ??'
Cuando usamos xmlcharrefreplace, recuperamos las entidades XML que tienen que ver con esos caracteres Unicode, por lo que si va a pegar esto en un documento XML o tal vez en HTML, funcionará.
>>s.encode('iso-8859-8',errors='xmlcharrefreplace')
b'I often go to 北京'
Depende de tus necesidades; si traduce caracteres Unicode a bytes, eso es típico porque los va a enviar a través de la red, o está tratando con algún otro tipo de sistema de codificación.
Si eres principiante y no quieres entrar en detalles, instala un paquete de Python llamado unidecode usando el siguiente comando.
Convertirá Unicode a ASCII directamente; será útil cuando trabaje con una aplicación en la que necesite convertir Unicode a ASCII.
from unidecode import unidecode
unidecode(u"北京")
# Output: 'Bei Jing'

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn