Konvertieren Sie Unicode in ASCII in Python

In diesem Artikel lernen wir, wie Unicode in Bytes codiert wird, sehen die verschiedenen Möglichkeiten zum Codieren des Systems und konvertieren Unicode in ASCII in Python.
Konvertieren Sie Unicode in ASCII in Python
Das grundlegende Problem in Python 3 Strings bestehen aus Zeichen; Wir haben keinen Zeichentyp in Python, aber sie enthalten Unicode-Zeichen.
Wenn wir a = 'abcd' sagen und seine Länge mit der Funktion len() überprüfen, erhalten wir 4 und deklarieren s='שלום', was Hallo bedeutet, und das ist das Wort in die hebräische Sprache. Diese Längen wären gleich, was großartig ist, da beide Variablen vier Zeichen haben.
>>a='abcd'
>>len(a)
4
>>s='שלום'
>>len(s)
4
Die Tatsache, dass hinter den Kulissen eine andere Anzahl von Bytes ist, ist für diese Frage hier irrelevant, das len() misst die Anzahl der Zeichen, nicht die Anzahl der Bytes, aber natürlich hinter den Kulissen UTF-8 Unicode Zeichen und eine UTF-8-Codierung verwenden mehr Bytes.
Wie können wir dann unseren String in die Bytes umwandeln, die wir brauchen? Nun, wir können s.encode() verwenden, und wenn wir dies tun, gibt es einen Byte-String zurück, der aus acht Bytes besteht, die wir brauchen, um das Wort שלום auf Hebräisch zu erstellen.
>>s.encode()
b'\xd7\xa9\xd7\x9c\xd7\x95\xd7\x9d'
>>'abcd'.encode()
b'abcd'
Jetzt nehmen wir einen Unicode-String und wandeln ihn in einen Byte-String um, aber es ist sogar noch komplexer, weil wir wissen, was dieser String שלום ist, und wir wollen die Bytes zurückbekommen, die keine zugrunde liegenden Bytes für Unicode darstellen. Wir möchten die zugrunde liegenden Bytes für ein anderes Codierungssystem zurückerhalten.
Zum Beispiel verwenden wir iso-8859-8, eine Art Codierung, von der Sie vielleicht gehört haben, dass sie in Westeuropa häufig verwendet wird und die es uns ermöglichte, ein Byte mit all den verschiedenen Zeichen zu haben, die wir für a brauchten bestimmte Sprache, wenn wir also eine Zeichenfolge nehmen und sie in eine Codierung umwandeln müssen, die nicht Unicode ist.
>>s.encode('iso-8859-8')
b'\xf9\xec\xe5\xed'
Mal sehen, was passiert, wenn wir etwas aus einer anderen Sprache haben, wie wir sagen s='北京', das ist Peking, und wenn wir es codieren, erhalten wir einen Byte-String zurück.
Wir sehen hier, dass wir sechs Bytes zurück haben, weil jedes dieser chinesischen Zeichen durch drei Bytes dargestellt wird; Dies ist unsere Codierung mit variabler Länge, die mit UTF-8 erfolgt.
>>s='北京'
>>s.encode()
b'\xe5\x8c\x97\xe4\xba\xac'
Jetzt wollen wir 北京 mit iso-8859-8 kodieren, und wenn wir dies ausführen, erhalten wir einen UnicodeEncodeError, was bedeutet, dass die Codierung uns sagt, dass Sie diese Unicode-Zeichen nehmen und in die umwandeln möchten Bytes für die Codierung iso-8859-8, die nicht erlaubt ist.
s.encode("iso-8859-8")
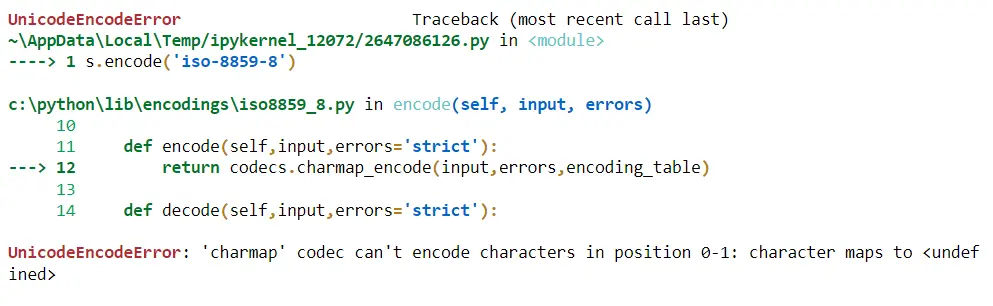
Wenn wir die englischen Wörter damit verbinden, wird es auch fehlschlagen, weil es überall dort fehlschlägt, wo wir einen Fehler haben könnten, aber wir können einen Parameter hinzufügen, der hilft, Fehler zu ignorieren.
>>s='I often go to 北京'
>>s.encode('iso-8859-8',errors='ignore')
b'I often go to '
Sie können dies verwenden, wenn Sie eine ganze Reihe von Texten haben und die Unicode-Zeichen in Ordnung sind.
Werfen wir einen Blick auf help(s.encode), das standardmäßig gleich strict ist, aber es kann ein paar verschiedene Dinge sein, also wenn wir den replace-Wert für errors verwenden, tut es das nicht wirklich wissen, wie man ersetzt, also wird es nur Fragezeichen verwenden.
help(s.encode)

>>s='I often go to 北京'
>>s.encode('iso-8859-8',errors='replace')
b'I often go to ??'
Wenn wir xmlcharrefreplace verwenden, erhalten wir die XML-Entitäten zurück, die mit diesen Unicode-Zeichen zu tun haben. Wenn Sie dies also entweder in ein XML-Dokument oder vielleicht in HTML einfügen, funktioniert dies.
>>s.encode('iso-8859-8',errors='xmlcharrefreplace')
b'I often go to 北京'
Es hängt von Ihren Bedürfnissen ab; Wenn Sie Unicode-Zeichen in Bytes übersetzen, ist dies typisch, weil Sie sie über das Netzwerk senden oder mit einem anderen Codierungssystem arbeiten.
Wenn Sie Anfänger sind und nicht ins Detail gehen möchten, installieren Sie mit dem folgenden Befehl ein Python-Paket namens unidecode.
Es konvertiert Unicode direkt in ASCII; Dies ist hilfreich, wenn Sie mit einer Anwendung arbeiten, in der Sie Unicode in ASCII konvertieren müssen.
from unidecode import unidecode
unidecode(u"北京")
# Output: 'Bei Jing'

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn