How to Calculate the Variance in a Pandas DataFrame
- Definition of Variance
- Calculate the Variance of a Single Column in a Pandas DataFrame
- Calculate the Variance of an Entire Pandas DataFrame
- Calculate the Variance Along the Column-Axis of a Pandas DataFrame
- Calculate the Variance Along the Row-Axis of a Pandas DataFrame

This tutorial will demonstrate how to calculate the variance in a Python Pandas dataframe.
Definition of Variance
Variance in statistics is the measure of dispersion in the data. Through variance, we can tell the spread in the data.
The greater the data points are far away from their average value, the greater the variance. Variance is the squared standard deviation.
Variance is calculated in three steps:
-
Determine how much each data point differs from the mean.
-
Calculate the square of each difference.
-
Divide the sum of the squared differences by the number (minus 1) of observations in your sample.
We call the var() method with the dataframe object to calculate variance. This method accepts four optional arguments.
Syntax:
# Python 3.x
variance = df.var(axis, skipna, level, ddof)
axis: specifies along which axis to calculate variance. Value 0 represents a column, and 1 represents a row. Default value is 0 (column axis).skipna: specifies whether to skip null values or not. The default value is True.level: Count along with a certain level of a Multi-Index (hierarchical) axis, collapsing into a Series. A string specifies the name of the level.ddof: stands for Degrees of Freedom.N – ddofis the divisor used in computations, where N is the number of elements.numeric_only: Only use float, int, and boolean columns. If None, everything will be tried first, then only numeric data will be used, and for Series, there is no implementation.
Calculate the Variance of a Single Column in a Pandas DataFrame
We can calculate the variance of a single column by specifying the column name of the dataframe in square brackets when calling the var() method to calculate the variance.
Example code:
# Python 3.x
import pandas as pd
df = pd.DataFrame(
{"C1": [2, 7, 5, 4], "C2": [4, 1, 8, 2], "C3": [6, 6, 6, 5], "C4": [3, 2, 8, 7]}
)
display(df)
C1_variance = df["C1"].var()
print("Variance of C1:", C1_variance)
Output:

Calculate the Variance of an Entire Pandas DataFrame
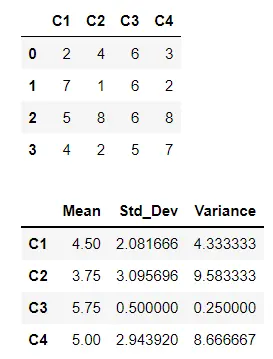
We can use built-in methods with the dataframe object to calculate the entire dataframe mean, standard deviation, and variance.
In the following code, we have a dataframe, and we calculated all these three variables and stored them in another dataframe named stats.
The mean() method calculates the mean. The std() method calculates the standard deviation, and the var() method calculates the variance of the entire dataframe.
Finally, we displayed the stats dataframe.
Example code:
# Python 3.x
import pandas as pd
df = pd.DataFrame(
{"C1": [2, 7, 5, 4], "C2": [4, 1, 8, 2], "C3": [6, 6, 6, 5], "C4": [3, 2, 8, 7]}
)
display(df)
stats = pd.DataFrame()
stats["Mean"] = df.mean()
stats["Std_Dev"] = df.std()
stats["Variance"] = df.var()
display(stats)
Output:
Calculate the Variance Along the Column-Axis of a Pandas DataFrame
To calculate variance column-wise, we will specify the axis=0 as a parameter for the var() method. By default, variance is calculated column-wise.
Example code:
# Python 3.x
import pandas as pd
df = pd.DataFrame(
{"C1": [2, 7, 5, 4], "C2": [4, 1, 8, 2], "C3": [6, 6, 6, 5], "C4": [3, 2, 8, 7]}
)
display(df)
df.var(axis=0)

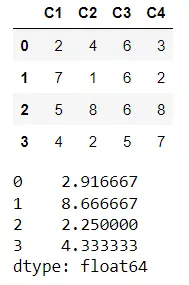
Calculate the Variance Along the Row-Axis of a Pandas DataFrame
We will specify axis=1 as a parameter for the var() method to calculate the variance of row values.
Example code:
# Python 3.x
import pandas as pd
df = pd.DataFrame(
{"C1": [2, 7, 5, 4], "C2": [4, 1, 8, 2], "C3": [6, 6, 6, 5], "C4": [3, 2, 8, 7]}
)
display(df)
df.var(axis=1)
Output:

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn