How to Use PhantomJS in Python
This Python article will look into PhantomJS and how we can use it with Selenium Web Automation Module for Python programming. We will also look into why it is more useful than other available web drivers for automation.
Selenium and PhantomJS are useful and provide unique benefits from the scraping perspective. Also, some practical coding examples shall follow to understand the whole concept better.
Install PhantomJS
PhantomJS is a headless browser that works with the Selenium web automation module. In contrast to Firefox Driver and Chrome Driver, the browser remains completely hidden throughout the procedure.
It acts exactly like other browsers. You can switch the web driver to Chrome Driver or Firefox Driver to design the procedure, and once it’s operational, you can switch it to PhantomJS.
Since PhantomJS eliminates the use of GUI, it runs much faster when performing some test runs for test cases.
Before using PhantomJS, we first need to install it. For installation in macOS, we run the following command.
Example Code:
brew install phantomjs
We need to download it from the website to install it on Windows or Linux. It can be found here.
Problem Scenario Solved Using PhantomJS
Let’s discuss a sample problem here and then try solving it with PhantomJS and Selenium.
We know that in the modern computing era, nowadays, most websites make use of JavaScript for the dynamic loading of content on their sites.
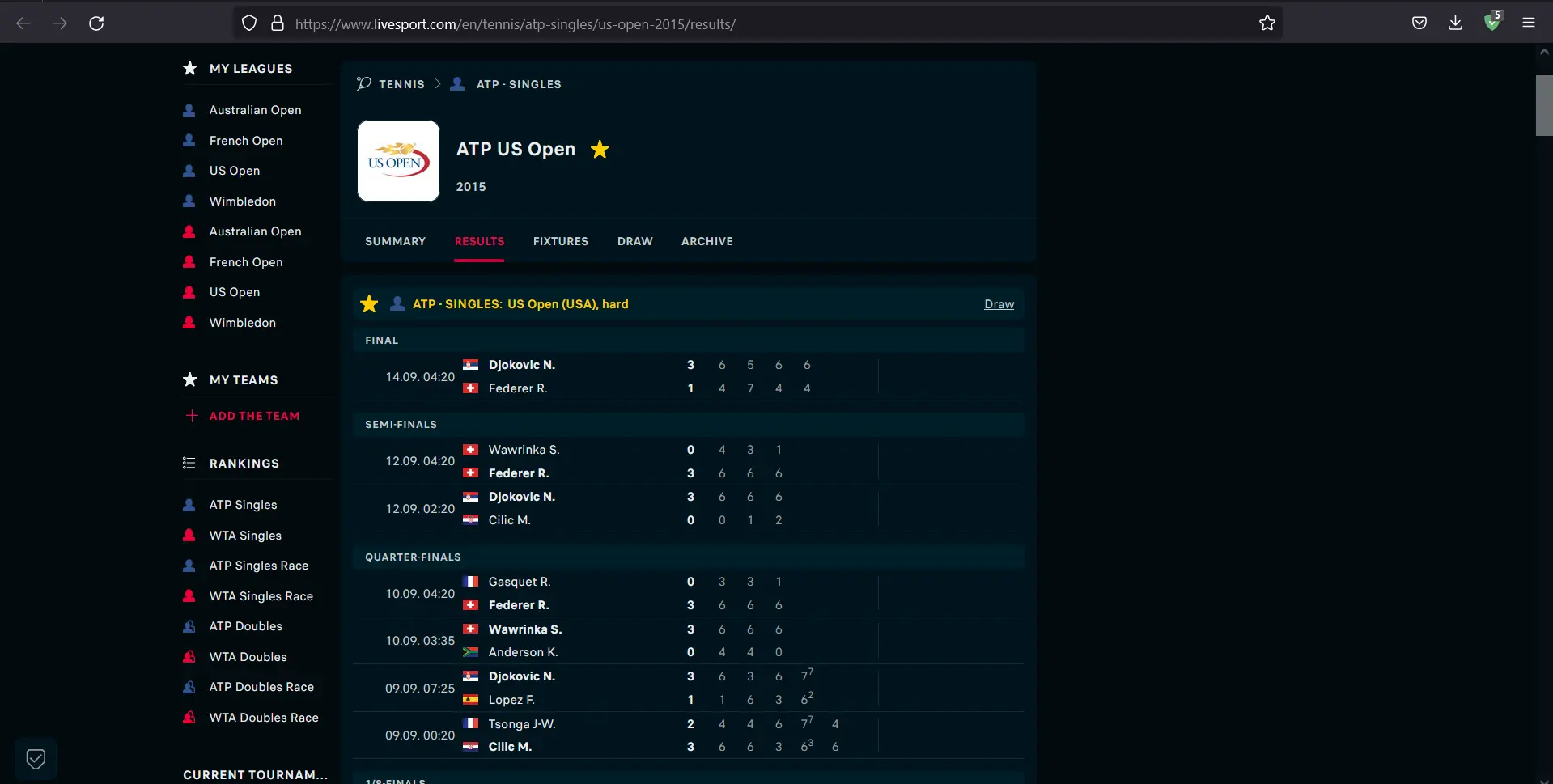
Let’s consider a site that loads ATP Singles USA Tennis Results 2015. Once the site is loaded, we can see that the points and match details are shown.
We can see the content loaded in a proper dynamic manner, all thanks to JavaScript. Now, let’s disable JavaScript and see what happens.
We can see that the content is not loaded after disabling JavaScript from our browser.
What if we want to use Python to download all the games from that website? With JavaScript not rendered, the page body is unfinished; therefore, the traditional method of sending the request to the site and parsing the HTML won’t work.
Use PhantomJS and Selenium in Parallel
Before starting to work on our code, we must set the environment first. For this, we shall type the following code:
mkdir scraping_phantomjs && cd scraping_phantomjs
virtualenv venv
source venv/bin/activate
pip install selenium beautifulsoup4
As the required installations and imports are done now, we move on to the next step and make a Python file that is supposed to save the data we will get by the end of the execution of our code.
Example Code:
touch scraper.py
Once the file is created, let’s start writing our script to get the HTML for the first match on the website mentioned above.
Example Code:
import platform
from bs4 import BeautifulSoup
from selenium import webdriver
# Extensions may vary from OS to OS that is why we're considering multiple types
if platform.system() == "Windows":
PHANTOMJS_PATH = "./phantomjs.exe"
else:
PHANTOMJS_PATH = "./phantomjs"
# We are using pseudo browser PhantomJS here but can change it to Firefox as
# per our needs
browser = webdriver.PhantomJS(PHANTOMJS_PATH)
browser.get("http://www.scoreboard.com/en/tennis/atp-singles/us-open-2015/results/")
# Now we need to parse our HTML
soup = BeautifulSoup(browser.page_source, "html.parser")
# Find all the games listed
games = soup.find_all("tr", {"class": "stage-finished"})
# and print out the html for the first game
# You can print the next game by changing 0 to 1 in games[]
print(games[0].prettify())
We must give the location of PhantomJS for this script to function. Ensure you get the appropriate version of PhantomJS from the link above for your operating system.
After that, unzip it to reveal the phantomjs file in the bin folder. The file should be in the same folder as the scraper.py script.
Let’s try running our script to see if we get the required output. To run the script, type the following command.
Example Code:
python scraper.py
The output shall give us the HTML for the first match. It looks something like this:
<tr class="The odd no-border-bottom stage-finished" id="g_2_2DtOK9O8">
<td class="cell_ib icons left ">
</td>
<td class="cell_ad time ">
14.09. 02:20
</td>
<td class="cell_ab team-home bold ">
<span class="padl">
Djokovic N. (Srb)
</span>
</td>
<td class="cell_ac team-away ">
<span class="padl">
Federer R. (Sui)
</span>
</td>
<td class="cell_sa score bold ">
3 : 1
</td>
<td class="cell_ia icons ">
<span class="icons">
</span>
</td>
</tr>
As we saw, getting dynamically loaded content is relatively easy and more efficient than just firing a request to the server.
This article briefly summarized how PhantomJS and Selenium could be used to get content from dynamic websites. It also explained why the said process is faster and more efficient than the traditional methods.

My name is Abid Ullah, and I am a software engineer. I love writing articles on programming, and my favorite topics are Python, PHP, JavaScript, and Linux. I tend to provide solutions to people in programming problems through my articles. I believe that I can bring a lot to you with my skills, experience, and qualification in technical writing.
LinkedIn