Usar PhantomJS en Python
Este artículo de Python analizará PhantomJS y cómo podemos usarlo con el módulo de automatización web de Selenium para la programación de Python. También veremos por qué es más útil que otros controladores web disponibles para la automatización.
Selenium y PhantomJS son útiles y brindan beneficios únicos desde la perspectiva del raspado. Además, a continuación se incluyen algunos ejemplos prácticos de codificación para comprender mejor todo el concepto.
Instalar PhantomJS
PhantomJS es un navegador sin cabeza que funciona con el módulo de automatización web Selenium. A diferencia de Firefox Driver y Chrome Driver, el navegador permanece completamente oculto durante todo el procedimiento.
Actúa exactamente como otros navegadores. Puede cambiar el controlador web a Chrome Driver o Firefox Driver para diseñar el procedimiento y, una vez que esté operativo, puede cambiarlo a PhantomJS.
Dado que PhantomJS elimina el uso de GUI, se ejecuta mucho más rápido cuando se realizan algunas pruebas para casos de prueba.
Antes de usar PhantomJS, primero debemos instalarlo. Para la instalación en macOS, ejecutamos el siguiente comando.
Código de ejemplo:
brew install phantomjs
Necesitamos descargarlo del sitio web para instalarlo en Windows o Linux. Se puede encontrar aquí].
Escenario de problema resuelto usando PhantomJS
Analicemos un problema de muestra aquí y luego intentemos resolverlo con PhantomJS y Selenium.
Sabemos que en la era informática moderna, hoy en día, la mayoría de los sitios web utilizan JavaScript para la carga dinámica de contenido en sus sitios.
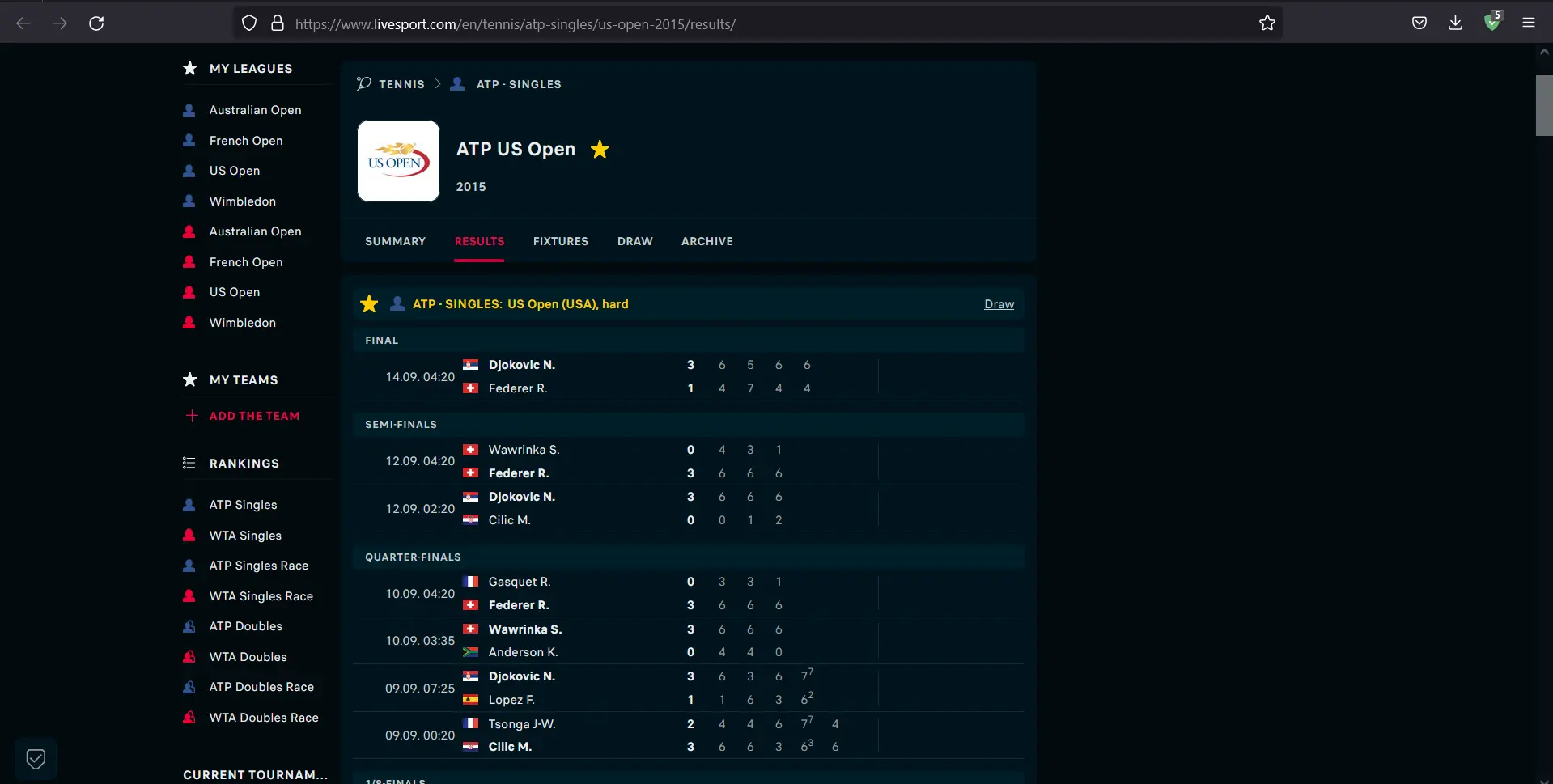
Consideremos un sitio que carga Resultados ATP Singles USA Tennis 2015. Una vez que se carga el sitio, podemos ver que se muestran los puntos y los detalles del partido.
Podemos ver el contenido cargado de una manera dinámica adecuada, todo gracias a JavaScript. Ahora, deshabilitemos JavaScript y veamos qué sucede.
Podemos ver que el contenido no se carga después de deshabilitar JavaScript de nuestro navegador.
¿Qué pasa si queremos usar Python para descargar todos los juegos de ese sitio web? Con JavaScript no renderizado, el cuerpo de la página no está terminado; por lo tanto, el método tradicional de enviar la solicitud al sitio y analizar el HTML no funcionará.
Utilice PhantomJS y Selenium en paralelo
Antes de comenzar a trabajar en nuestro código, primero debemos configurar el entorno. Para ello, teclearemos el siguiente código:
mkdir scraping_phantomjs && cd scraping_phantomjs
virtualenv venv
source venv/bin/activate
pip install selenium beautifulsoup4
Como las instalaciones e importaciones requeridas ya están hechas, pasamos al siguiente paso y creamos un archivo de Python que se supone que guardará los datos que obtendremos al final de la ejecución de nuestro código.
Código de ejemplo:
touch scraper.py
Una vez que se crea el archivo, comencemos a escribir nuestro script para obtener el HTML para la primera coincidencia en el sitio web mencionado anteriormente.
Código de ejemplo:
import platform
from bs4 import BeautifulSoup
from selenium import webdriver
# Extensions may vary from OS to OS that is why we're considering multiple types
if platform.system() == "Windows":
PHANTOMJS_PATH = "./phantomjs.exe"
else:
PHANTOMJS_PATH = "./phantomjs"
# We are using pseudo browser PhantomJS here but can change it to Firefox as
# per our needs
browser = webdriver.PhantomJS(PHANTOMJS_PATH)
browser.get("http://www.scoreboard.com/en/tennis/atp-singles/us-open-2015/results/")
# Now we need to parse our HTML
soup = BeautifulSoup(browser.page_source, "html.parser")
# Find all the games listed
games = soup.find_all("tr", {"class": "stage-finished"})
# and print out the html for the first game
# You can print the next game by changing 0 to 1 in games[]
print(games[0].prettify())
Debemos dar la ubicación de PhantomJS para que este script funcione. Asegúrese de obtener la versión adecuada de PhantomJS del enlace anterior para su sistema operativo.
Después de eso, descomprímalo para revelar el archivo phantomjs en la carpeta bin. El archivo debe estar en la misma carpeta que el script scraper.py.
Intentemos ejecutar nuestro script para ver si obtenemos el resultado requerido. Para ejecutar el script, escriba el siguiente comando.
Código de ejemplo:
python scraper.py
La salida nos dará el HTML para la primera coincidencia. Se ve algo como esto:
<tr class="The odd no-border-bottom stage-finished" id="g_2_2DtOK9O8">
<td class="cell_ib icons left ">
</td>
<td class="cell_ad time ">
14.09. 02:20
</td>
<td class="cell_ab team-home bold ">
<span class="padl">
Djokovic N. (Srb)
</span>
</td>
<td class="cell_ac team-away ">
<span class="padl">
Federer R. (Sui)
</span>
</td>
<td class="cell_sa score bold ">
3 : 1
</td>
<td class="cell_ia icons ">
<span class="icons">
</span>
</td>
</tr>
Como vimos, obtener contenido cargado dinámicamente es relativamente fácil y más eficiente que simplemente enviar una solicitud al servidor.
Este artículo resumió brevemente cómo PhantomJS y Selenium podrían usarse para obtener contenido de sitios web dinámicos. También explicó por qué dicho proceso es más rápido y eficiente que los métodos tradicionales.

My name is Abid Ullah, and I am a software engineer. I love writing articles on programming, and my favorite topics are Python, PHP, JavaScript, and Linux. I tend to provide solutions to people in programming problems through my articles. I believe that I can bring a lot to you with my skills, experience, and qualification in technical writing.
LinkedIn