Verwenden Sie PhantomJS in Python
Dieser Python-Artikel befasst sich mit PhantomJS und wie wir es mit dem Selenium Web Automation Module für die Python-Programmierung verwenden können. Wir werden auch untersuchen, warum es nützlicher ist als andere verfügbare Webtreiber für die Automatisierung.
Selenium und PhantomJS sind nützlich und bieten einzigartige Vorteile aus der Scraping-Perspektive. Außerdem sollen einige praktische Codierungsbeispiele folgen, um das gesamte Konzept besser zu verstehen.
Installieren Sie PhantomJS
PhantomJS ist ein Headless-Browser, der mit dem Selenium-Webautomatisierungsmodul zusammenarbeitet. Im Gegensatz zu Firefox Driver und Chrome Driver bleibt der Browser während des gesamten Vorgangs vollständig verborgen.
Es verhält sich genau wie andere Browser. Sie können den Webtreiber auf Chrome Driver oder Firefox Driver umstellen, um das Verfahren zu entwerfen, und sobald er betriebsbereit ist, können Sie ihn auf PhantomJS umstellen.
Da PhantomJS die Verwendung der GUI eliminiert, läuft es viel schneller, wenn einige Testläufe für Testfälle durchgeführt werden.
Bevor wir PhantomJS verwenden, müssen wir es zuerst installieren. Für die Installation in macOS führen wir den folgenden Befehl aus.
Beispielcode:
brew install phantomjs
Wir müssen es von der Website herunterladen, um es unter Windows oder Linux zu installieren. Es ist hier zu finden.
Problemszenario mit PhantomJS gelöst
Lassen Sie uns hier ein Beispielproblem diskutieren und dann versuchen, es mit PhantomJS und Selenium zu lösen.
Wir wissen, dass im modernen Computerzeitalter heutzutage die meisten Websites JavaScript für das dynamische Laden von Inhalten auf ihren Websites verwenden.
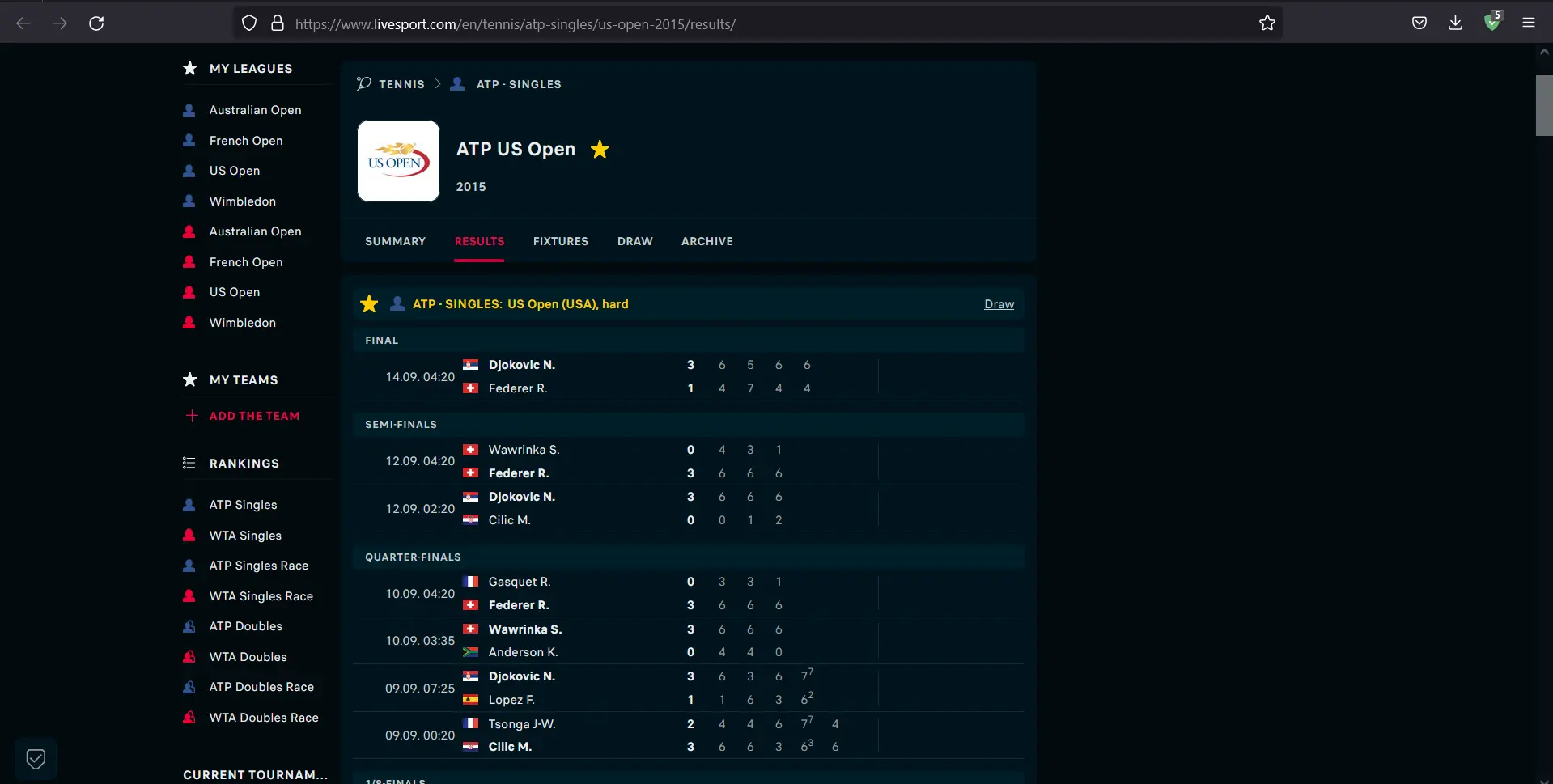
Betrachten wir eine Website, die ATP Singles USA Tennis Results 2015 lädt. Sobald die Seite geladen ist, können wir sehen, dass die Punkte und Spieldetails angezeigt werden.
Wir können sehen, dass der Inhalt dank JavaScript richtig dynamisch geladen wird. Lassen Sie uns jetzt JavaScript deaktivieren und sehen, was passiert.
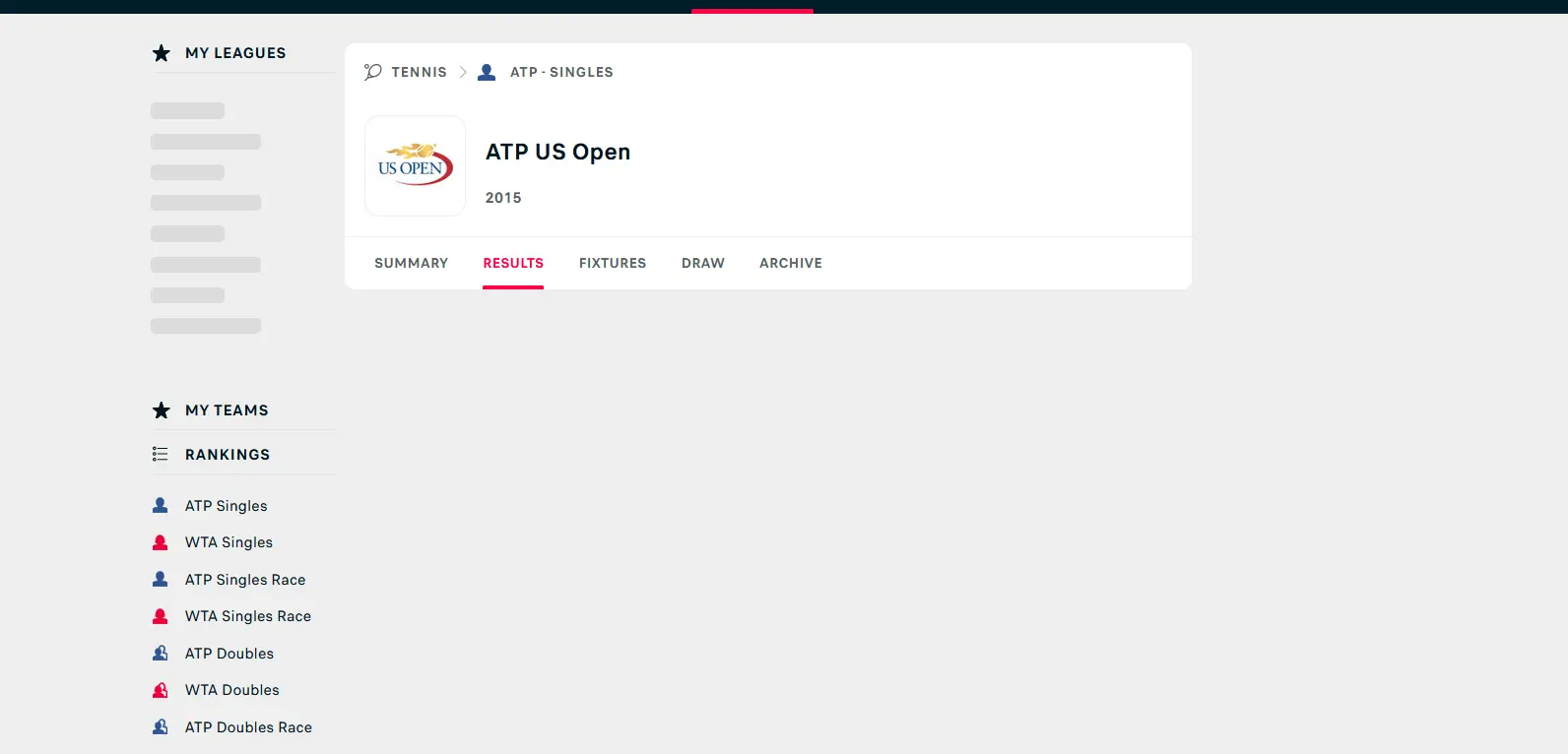
Wir können sehen, dass der Inhalt nicht geladen wird, nachdem JavaScript in unserem Browser deaktiviert wurde.
Was ist, wenn wir Python verwenden möchten, um alle Spiele von dieser Website herunterzuladen? Wenn JavaScript nicht gerendert wird, ist der Seitentext unfertig; Daher funktioniert die traditionelle Methode, die Anfrage an die Site zu senden und den HTML-Code zu parsen, nicht.
Verwenden Sie PhantomJS und Selenium parallel
Bevor wir mit der Arbeit an unserem Code beginnen, müssen wir zuerst die Umgebung festlegen. Dazu geben wir folgenden Code ein:
mkdir scraping_phantomjs && cd scraping_phantomjs
virtualenv venv
source venv/bin/activate
pip install selenium beautifulsoup4
Da die erforderlichen Installationen und Importe jetzt abgeschlossen sind, fahren wir mit dem nächsten Schritt fort und erstellen eine Python-Datei, die die Daten speichern soll, die wir am Ende der Ausführung unseres Codes erhalten.
Beispielcode:
touch scraper.py
Sobald die Datei erstellt ist, beginnen wir mit dem Schreiben unseres Skripts, um den HTML-Code für die erste Übereinstimmung auf der oben genannten Website abzurufen.
Beispielcode:
import platform
from bs4 import BeautifulSoup
from selenium import webdriver
# Extensions may vary from OS to OS that is why we're considering multiple types
if platform.system() == "Windows":
PHANTOMJS_PATH = "./phantomjs.exe"
else:
PHANTOMJS_PATH = "./phantomjs"
# We are using pseudo browser PhantomJS here but can change it to Firefox as
# per our needs
browser = webdriver.PhantomJS(PHANTOMJS_PATH)
browser.get("http://www.scoreboard.com/en/tennis/atp-singles/us-open-2015/results/")
# Now we need to parse our HTML
soup = BeautifulSoup(browser.page_source, "html.parser")
# Find all the games listed
games = soup.find_all("tr", {"class": "stage-finished"})
# and print out the html for the first game
# You can print the next game by changing 0 to 1 in games[]
print(games[0].prettify())
Wir müssen den Speicherort von PhantomJS angeben, damit dieses Skript funktioniert. Stellen Sie sicher, dass Sie über den obigen Link die richtige Version von PhantomJS für Ihr Betriebssystem erhalten.
Danach entpacken Sie es, um die Datei phantomjs im Ordner bin anzuzeigen. Die Datei sollte sich im selben Ordner wie das Skript scraper.py befinden.
Lassen Sie uns versuchen, unser Skript auszuführen, um zu sehen, ob wir die erforderliche Ausgabe erhalten. Geben Sie zum Ausführen des Skripts den folgenden Befehl ein.
Beispielcode:
python scraper.py
Die Ausgabe soll uns den HTML-Code für die erste Übereinstimmung liefern. Es sieht in etwa so aus:
<tr class="The odd no-border-bottom stage-finished" id="g_2_2DtOK9O8">
<td class="cell_ib icons left ">
</td>
<td class="cell_ad time ">
14.09. 02:20
</td>
<td class="cell_ab team-home bold ">
<span class="padl">
Djokovic N. (Srb)
</span>
</td>
<td class="cell_ac team-away ">
<span class="padl">
Federer R. (Sui)
</span>
</td>
<td class="cell_sa score bold ">
3 : 1
</td>
<td class="cell_ia icons ">
<span class="icons">
</span>
</td>
</tr>
Wie wir gesehen haben, ist das Abrufen dynamisch geladener Inhalte relativ einfach und effizienter, als nur eine Anfrage an den Server zu senden.
Dieser Artikel fasste kurz zusammen, wie PhantomJS und Selenium verwendet werden könnten, um Inhalte von dynamischen Websites zu erhalten. Es erklärte auch, warum der besagte Prozess schneller und effizienter ist als die traditionellen Methoden.

My name is Abid Ullah, and I am a software engineer. I love writing articles on programming, and my favorite topics are Python, PHP, JavaScript, and Linux. I tend to provide solutions to people in programming problems through my articles. I believe that I can bring a lot to you with my skills, experience, and qualification in technical writing.
LinkedIn