How to Read Parquet File Into Pandas DataFrame

In modern data science and data structures, a Parquet file is a modernized and improved manner of storing information more organized than a CSV file.
In this article, we will explore the nature of Parquet files and how we can read them into a Pandas DataFrame in Python.
Parquet Files
Parquet files store information in a columnized data file format. These files are modernized, more efficient, and organized for data storage and retrieval.
Parquet files also hold a significant advantage over CSV files as they allow relevant data to be read directly and irrelevant data to be skipped. This manner of storage significantly reduces latency during various data reading and retrieval processes.
Furthermore, storing big data, such as videos, audio, images, etc., is not a problem with Parquet.
Read Parquet File Into Pandas DataFrame
To read a parquet file into a DataFrame in Pandas, we need only follow a series of simple steps to cover the required installations before moving on to the code.
We must first ensure that we have Python installed in our system. We can check the version of Python installed by using the below command.
python --version
The next step is just as simple as we run the following command to install the Pandas library if we don’t already have it.
pip install pandas
Now we have the basic needs covered, and we need an engine that the Pandas module can use to read the Parquet file. In this case, we will be using Apache Arrow.
We can install it using the following command.
pip install pyarrow
Those were all the required prerequisites to read the parquet file into a Pandas DataFrame.
For reading a parquet file into a data frame, the read_parquet() method is used. It has 5 parameters that can be added or used per the developer’s requirement.
Syntax:
pandas.read_parquet(
path,
engine="auto",
columns=None,
storage_options=None,
use_nullable_dtypes=False,
**kwargs
)
It’s important to note that three engine options are available, and any engine can be used.
autopyarrowfastparquet
Now that we’ve covered the prerequisites and the method we will use, we can formulate a code for reading the file. The code for reading a parquet file is pretty simple and relatively straightforward.
For it, we need only a parquet file and (for this article, we will first create a parquet file) the read_parquet() method.
Example Code:
import pandas as pd
df = pd.DataFrame(
{
"student": ["Alia", "Zoya", "Ali"],
"marks": [20, 10, 22],
}
)
df.to_parquet("student.parquet")
pd.read_parquet("student.parquet", engine="pyarrow")
Output:
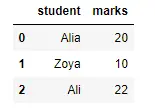
That was all on the whole reading parquet files into data frames front. Now that we can read the file, we can continue performing various data analyzing techniques and searches per our unique requirements.

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn