Leer archivo de parquet en Pandas DataFrame

En la ciencia de datos y las estructuras de datos modernas, un archivo Parquet es una forma modernizada y mejorada de almacenar información más organizada que un archivo CSV. En este artículo, exploraremos la naturaleza de los archivos de Parquet y cómo podemos leerlos en un Pandas DataFrame en Python.
Archivos de parquet
Los archivos de parquet almacenan información en un formato de archivo de datos en columnas. Estos archivos se modernizan, son más eficientes y están organizados para el almacenamiento y la recuperación de datos.
Los archivos de parquet también tienen una ventaja significativa sobre los archivos CSV, ya que permiten leer directamente los datos relevantes y omitir los datos irrelevantes. Esta forma de almacenamiento reduce significativamente la latencia durante varios procesos de lectura y recuperación de datos.
Además, almacenar big data, como videos, audio, imágenes, etc., no es un problema con Parquet.
Leer archivo de parquet en Pandas DataFrame
Para leer un archivo de parquet en un DataFrame en Pandas, solo necesitamos seguir una serie de pasos simples para cubrir las instalaciones requeridas antes de pasar al código.
Primero debemos asegurarnos de tener Python instalado en nuestro sistema. Podemos verificar la versión de Python instalada usando el siguiente comando.
python --version
El siguiente paso es tan simple como ejecutar el siguiente comando para instalar la biblioteca de Pandas si aún no la tenemos.
pip install pandas
Ahora tenemos las necesidades básicas cubiertas y necesitamos un motor que el módulo Pandas pueda usar para leer el archivo Parquet. En este caso, usaremos Apache Arrow.
Podemos instalarlo usando el siguiente comando.
pip install pyarrow
Esos eran todos los requisitos previos necesarios para leer el archivo de parquet en un DataFrame de Pandas.
Para leer un archivo de parquet en un marco de datos, se utiliza el método read_parquet(). Tiene 5 parámetros que se pueden agregar o usar según los requisitos del desarrollador.
Sintaxis:
pandas.read_parquet(
path,
engine="auto",
columns=None,
storage_options=None,
use_nullable_dtypes=False,
**kwargs
)
Es importante tener en cuenta que hay tres opciones de motor disponibles y que se puede usar cualquier motor.
autopyarrowfastparquet
Ahora que hemos cubierto los requisitos previos y el método que usaremos, podemos formular un código para leer el archivo. El código para leer un archivo de parquet es bastante simple y relativamente directo.
Para ello, solo necesitamos un archivo de parquet y (para este artículo, primero crearemos un archivo de parquet) el método read_parquet().
Código de ejemplo:
import pandas as pd
df = pd.DataFrame(
{
"student": ["Alia", "Zoya", "Ali"],
"marks": [20, 10, 22],
}
)
df.to_parquet("student.parquet")
pd.read_parquet("student.parquet", engine="pyarrow")
Producción:
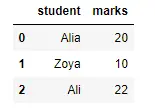
Eso fue todo en general leyendo archivos de parquet en frente de marcos de datos. Ahora que podemos leer el archivo, podemos continuar realizando varias técnicas de análisis de datos y búsquedas según nuestros requisitos únicos.

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn