The DISTINCT Clause in PostgreSQL
-
Introduction to the
DISTINCTClause in PostgreSQL -
Use of the
DISTINCTClause inPostgreSQL -
Use of the
DISTINCT ONClause in PostgreSQL
This tutorial illustrates the use of the DISTINCT clause using different code examples. It also demonstrates how to use this clause on the whole table and a specific set of attributes.
Introduction to the DISTINCT Clause in PostgreSQL
We know that if we want to display all the rows from a table, we can use a simple SELECT statement. So let us assume that we have the following table:
Create table sample ( Number int not null);
Now, let us insert some data into this sample table:
Insert into sample values (100), (200), (300), (100);
If we now run a simple SELECT * FROM sample query on this database, we get the following output which displays all the rows:
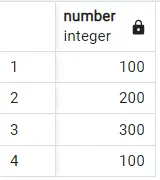
Can you see what is happening here? The value 100 is being printed twice since repeated during insertion. What if we want to display unique values? Is there any way to do this in PostgreSQL?
Yes, the DISTINCT clause allows us to filter out duplicates from a query’s result and display them only once. In detail below, let’s learn the DISTINCT and DISTINCT ON in PostgreSQL.
Use of the DISTINCT Clause inPostgreSQL
The DISTINCT clause in a SELECT statement removes all duplicate row values from the result. From the identical values, only one is displayed so that no value is repeated in the output.
Let us examine the syntax of the DISTINCT clause by applying it to the sample table defined above.
SELECT DISTINCT * FROM sample;
We get the output below by executing this query:

Did you notice the difference? Now the value of 100 is displayed only once instead of twice in a simple SELECT statement. That is the power of the DISTINCT clause.
Now that you understand the usage of the DISTINCT clause let us present another scenario. Suppose we have the following table:
Create table example(
Id int not null,
Number int not null,
Constraint PK2 primary key (id)
);
Insert into example values (1, 100), (2, 200), (3, 300), (4, 100);
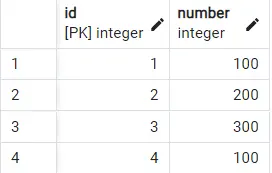
If we now run a simple SELECT * FROM example; query, we get the following output displaying all the rows:
We can see that the value of 100 is repeating, as expected. Let us use the DISTINCT clause as we have learned above:
SELECT DISTINCT * FROM example;
It did not work! We are still getting the same output. All rows with a value of 100 are not duplicated when treated as a whole along with id.
They are unique because the value of id is different in both, and thus they’re displayed in the output. So how do we go around this?
Do we have any way to filter out duplicates from particular attributes? Yes, the DISTINCT ON clause allows us to do so in PostgreSQL.
Use of the DISTINCT ON Clause in PostgreSQL
The DISTINCT ON clause allows us to remove duplicate values of specified attributes from the result of a SELECT query by displaying only the first occurrence of the value.
In this way, even if the values of the other attributes in the rows are different, only the first row spotted will be displayed. It has the following syntax:
DISTINCT ON (attribute1, attribute2,…)
Let us understand the syntax and working of the DISTINCT ON clause by running the following query on the example table defined above.
SELECT DISTINCT ON (number) * FROM example;
It gives the following output:
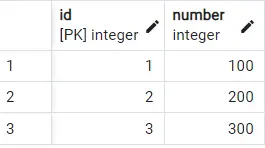
The duplicate value of 100 is gone! So we can see that only the first row having the repeating value of number is displayed in the output, as expected. The critical point is that the first row is not always predictable.
It means the query may return a different output every time it is run, which can be a problem. Therefore, using it along with the ORDER BY clause is a good practice.
The ORDER BY clause allows you to sort the data based on one or multiple attributes from the table. We can sort in descending or ascending order using that set of attributes.
Let us look at how the ORDER BY clause is used with the DISTINCT ON clause using the following query:
SELECT DISTINCT ON (number) * FROM example
ORDER BY number, id DESC;
Executing this query gives us the following output:
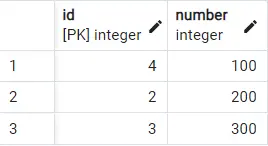
We can see that now the last row is displayed as the only repeated occurrence.
Because we ordered the rows in descending order according to id, the last row having id as 4 appears first and is treated as the first occurrence.
However, you must have noticed that even though we wanted to order the rows according to id, we still specified number as the first attribute in the ORDER BY clause.
PostgreSQL requires that the leftmost attribute or attributes specified in the ORDER BY clause must match those written in the DISTINCT ON clause. It is just a requirement of PostgreSQL.
If we analyze it, we can see that it does not disturb the results of the duplicate rows because the leftmost attributes will have the same values. Therefore, the rows will automatically be ordered according to the following attributes.
In this case, number had the exact value of 100, so the rows were ordered according to the following attribute, i.e., id. Let us try to execute the following query, which we know will give an error:
SELECT DISTINCT ON (number) * FROM example
ORDER BY id DESC;
As expected, we get the following error:


Hello, I am Bilal, a research enthusiast who tends to break and make code from scratch. I dwell deep into the latest issues faced by the developer community and provide answers and different solutions. Apart from that, I am just another normal developer with a laptop, a mug of coffee, some biscuits and a thick spectacle!
GitHub