PostgreSQL의 DISTINCT 절
이 자습서는 다양한 코드 예제를 사용하여 DISTINCT 절의 사용을 보여줍니다. 또한 전체 테이블과 특정 특성 집합에서 이 절을 사용하는 방법을 보여 줍니다.
PostgreSQL의 DISTINCT 절 소개
테이블의 모든 행을 표시하려면 간단한 SELECT 문을 사용할 수 있습니다. 따라서 다음 테이블이 있다고 가정해 보겠습니다.
Create table sample ( Number int not null);
이제 이 샘플 테이블에 일부 데이터를 삽입해 보겠습니다.
Insert into sample values (100), (200), (300), (100);
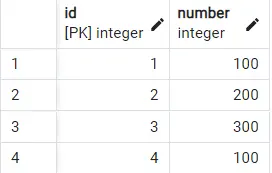
이제 이 데이터베이스에서 간단한 SELECT * FROM sample 쿼리를 실행하면 모든 행을 표시하는 다음 출력이 표시됩니다.
여기서 무슨 일이 일어나고 있는지 볼 수 있습니까? 삽입하는 동안 반복된 이후 값 100이 두 번 인쇄됩니다. 고유한 값을 표시하려면 어떻게 해야 합니까? PostgreSQL에서 이를 수행할 수 있는 방법이 있습니까?
예, DISTINCT 절을 사용하면 쿼리 결과에서 중복 항목을 필터링하여 한 번만 표시할 수 있습니다. 아래에서 PostgreSQL의 DISTINCT와 DISTINCT ON에 대해 자세히 알아보겠습니다.
PostgreSQL에서 DISTINCT 절 사용
SELECT 문의 DISTINCT 절은 결과에서 모든 중복 행 값을 제거합니다. 동일한 값 중에서 하나만 표시되므로 출력에 값이 반복되지 않습니다.
위에서 정의한 sample 테이블에 적용하여 DISTINCT 절의 구문을 살펴보겠습니다.
SELECT DISTINCT * FROM sample;
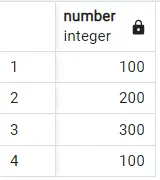
이 쿼리를 실행하여 아래 출력을 얻습니다.

차이점을 눈치채셨나요? 이제 100의 값이 간단한 SELECT 문에서 두 번이 아니라 한 번만 표시됩니다. 이것이 DISTINCT 절의 힘입니다.
이제 DISTINCT 절의 사용법을 이해했으므로 다른 시나리오를 제시하겠습니다. 다음 테이블이 있다고 가정합니다.
Create table example(
Id int not null,
Number int not null,
Constraint PK2 primary key (id)
);
Insert into example values (1, 100), (2, 200), (3, 300), (4, 100);
이제 간단한 SELECT * FROM example;을 실행하면 쿼리를 실행하면 모든 행을 표시하는 다음 출력이 표시됩니다.
예상대로 100의 값이 반복되는 것을 볼 수 있습니다. 위에서 배운 대로 DISTINCT 절을 사용하겠습니다.
SELECT DISTINCT * FROM example;
그것은 작동하지 않았다! 우리는 여전히 같은 결과를 얻고 있습니다. 값이 100인 모든 행은 id와 함께 전체로 처리될 때 중복되지 않습니다.
둘 다 id의 값이 다르기 때문에 고유하므로 출력에 표시됩니다. 그럼 이 문제를 어떻게 해결해야 할까요?
특정 속성에서 중복을 걸러낼 방법이 있습니까? 예, DISTINCT ON 절을 사용하면 PostgreSQL에서 그렇게 할 수 있습니다.
PostgreSQL에서 DISTINCT ON 절 사용
DISTINCT ON 절을 사용하면 SELECT 쿼리 결과에서 지정된 속성의 중복 값을 제거하여 값의 첫 번째 항목만 표시할 수 있습니다.
이렇게 하면 행의 다른 속성 값이 다르더라도 첫 번째로 발견된 행만 표시됩니다. 다음과 같은 구문이 있습니다.
DISTINCT ON (attribute1, attribute2,…)
위에서 정의한 example 테이블에서 다음 쿼리를 실행하여 DISTINCT ON 절의 구문과 작업을 이해해 보겠습니다.
SELECT DISTINCT ON (number) * FROM example;
다음 출력을 제공합니다.
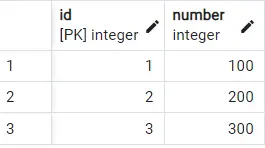
100의 중복 값이 사라졌습니다! 따라서 예상대로 반복되는 숫자 값이 있는 첫 번째 행만 출력에 표시되는 것을 볼 수 있습니다. 중요한 점은 첫 번째 행이 항상 예측 가능한 것은 아니라는 것입니다.
이는 쿼리가 실행될 때마다 다른 출력을 반환할 수 있으며 이는 문제가 될 수 있음을 의미합니다. 따라서 ORDER BY 절과 함께 사용하는 것이 좋습니다.
ORDER BY 절을 사용하면 테이블의 하나 이상의 속성을 기반으로 데이터를 정렬할 수 있습니다. 해당 속성 집합을 사용하여 내림차순 또는 오름차순으로 정렬할 수 있습니다.
다음 쿼리를 사용하여 DISTINCT ON 절과 함께 ORDER BY 절을 사용하는 방법을 살펴보겠습니다.
SELECT DISTINCT ON (number) * FROM example
ORDER BY number, id DESC;
이 쿼리를 실행하면 다음과 같은 결과가 나타납니다.
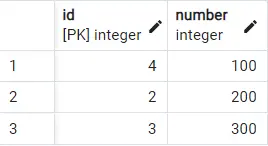
이제 마지막 행이 유일하게 반복되는 항목으로 표시되는 것을 볼 수 있습니다.
id에 따라 내림차순으로 행을 정렬했기 때문에 id가 4인 마지막 행이 먼저 나타나고 첫 번째 항목으로 처리됩니다.
그러나 id에 따라 행을 정렬하려고 했지만 여전히 ORDER BY 절의 첫 번째 속성으로 number를 지정했습니다.
PostgreSQL에서는 ORDER BY 절에 지정된 가장 왼쪽 속성이 DISTINCT ON 절에 기록된 속성과 일치해야 합니다. PostgreSQL의 요구 사항일 뿐입니다.
이를 분석하면 가장 왼쪽 속성이 동일한 값을 가지므로 중복 행의 결과를 방해하지 않는다는 것을 알 수 있습니다. 따라서 행은 다음 속성에 따라 자동으로 정렬됩니다.
이 경우 숫자의 정확한 값은 100이므로 다음 속성(예: id)에 따라 행이 정렬되었습니다. 오류가 발생한다는 것을 알고 있는 다음 쿼리를 실행해 보겠습니다.
SELECT DISTINCT ON (number) * FROM example
ORDER BY id DESC;
예상대로 다음 오류가 발생합니다.


Hello, I am Bilal, a research enthusiast who tends to break and make code from scratch. I dwell deep into the latest issues faced by the developer community and provide answers and different solutions. Apart from that, I am just another normal developer with a laptop, a mug of coffee, some biscuits and a thick spectacle!
GitHub