Berechnen Sie das Konfidenzintervall mit SciPy

Dieser Artikel soll Ihnen helfen, die Konfidenzintervalle in Python mit SciPy zu berechnen. Bevor wir in den Berechnungsteil eintauchen, müssen einige grundlegende Informationen über das Konfidenzintervall verstanden werden.
Berechnen Sie das Konfidenzintervall mit SciPy
Wenn wir etwas messen, müssen wir immer den Grad der Unsicherheit im Ergebnis berechnen. Konfidenzintervalle sind ein äußerst wichtiges Werkzeug zur Berechnung eines Bereichs, innerhalb dessen wir den wahren Wert einer Observablen mit hoher Sicherheit lokalisieren können.
Angenommen, Sie fragen nach der Körpergröße. Man könnte Ihnen sagen, dass er 1,55 Meter groß ist, aber das sagt nichts über die Unsicherheit dieser Messung aus.
Konfidenzintervalle sind Intervalle, in denen wir ein hohes Konfidenzniveau bei der Bestimmung des wahren Werts der zu messenden Observablen haben. Wissenschaftler wollen oft ein Konfidenzintervall von 95 %, aber 90 % oder sogar 99 % sind auch häufig.
Wenn Sie also nach der Körpergröße fragen, sollte man Ihnen eine Schätzung oder ein Konfidenzintervall nennen, z. B. mit 95%iger Sicherheit ist man zwischen 1,50 Meter und 1,60 Meter groß.
Dieses Tool liefert uns ein Intervall zur Bestimmung des wahren Werts der Observablen.
Um das Konfidenzintervall zu berechnen, müssen wir die folgende Formel verwenden:

Wo:
- Der
x_barist der Stichprobenmittelwert. - Das
zist der Konfidenzniveauwert. - Das
nist die Stichprobengrösse. - Das
sist die Stichproben-Standardabweichung.
Angenommen, wir arbeiten an Daten mit einer Stichprobe von weniger als 30; dann spricht man von einer t-Verteilung. Und um sein Konfidenzintervall zu berechnen, verwenden wir die Funktion t.interval() aus der Bibliothek scipy.stats.
Angenommen, wir haben Datensätze der Bevölkerung in verschiedenen Dörfern. In diesem Beispiel verwenden wir einen Datensatz der Größe (n=23), um die 95 %-Konfidenzintervalle mithilfe der t-Verteilung und der Methode t.interval() in Python zu berechnen, wobei der Konfidenzparameter auf 0,95 gesetzt ist.
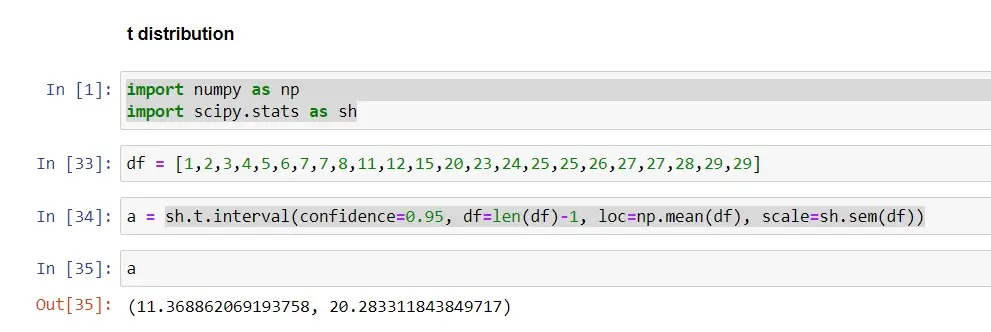
Hier sehen Sie, dass t.interval() die Parameter confidence, data (df), loc (location parameter) und scale übernimmt.
Sehen wir uns den Unterschied im Konfidenzniveau an, wenn wir 99 % verwenden.

Wenn wir ein 95-%-Konfidenzintervall verwenden, ist das Intervall (11,37-20,28), während bei einem 99-%-Konfidenzintervall das Intervall (9,77-21,88) ist. Beim Vergleich beider Intervalle sehen wir, dass das Intervall breiter ist, wenn wir ein KI von 99 % verwenden, was bedeutet, dass das Intervall (9,77-21,88) mit einer Wahrscheinlichkeit von 99 % die wahre Grundgesamtheit enthält.
Was sollten wir tun, wenn wir einen Datensatz mit einer Stichprobengröße von mehr als 30 haben? Wir können die Methode norm.interval() der scipy.stats-Bibliothek verwenden, um das Konfidenzintervall für einen Populationsmittelwert eines gegebenen Datensatzes zu erhalten, wenn der Datensatz in Python normalverteilt ist.
In diesem Beispiel verwenden wir einen zufälligen Datensatz der Größe (n=60), um die 95%-Konfidenzintervalle mit der Normalverteilung und der Methode norm.interval() in Python zu berechnen, wobei der Parameter alpha auf eingestellt ist 0,95.
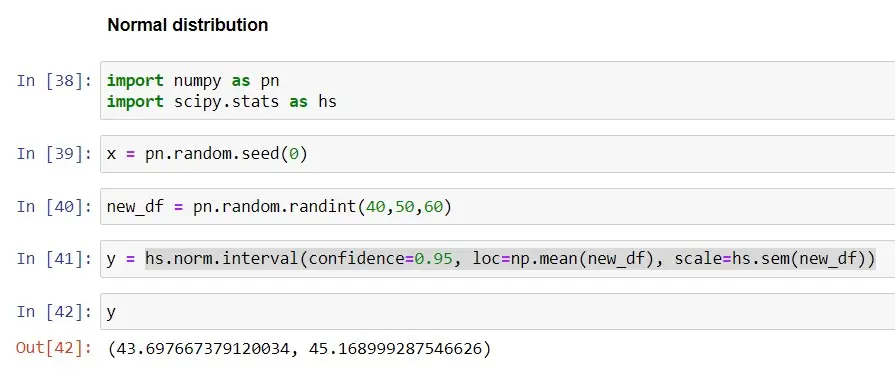
Sehen wir uns den Unterschied im Konfidenzniveau an, wenn wir 99 % verwenden.

Wenn wir ein Konfidenzintervall von 95 % verwenden, ist das Intervall (43,70-45,17); Wenn wir ein Konfidenzintervall von 99 % verwenden, ist das Intervall (43,47-45,41). Beim Vergleich beider Intervalle sehen wir, dass das Intervall breiter ist, wenn wir ein KI von 99 % verwenden, was bedeutet, dass eine Wahrscheinlichkeit von 99 % besteht, dass das Intervall (43,47–45,41) die wahre Grundgesamtheit enthält.
Konfidenzintervalle sind einfach zu berechnen und können Datenanalysten und Wissenschaftlern wertvolle Informationen liefern. Sie bieten eine sehr aussagekräftige Fehlerschätzung und können uns bei richtiger Anwendung wirklich dabei helfen, so viele Informationen wie möglich aus unseren Daten zu extrahieren.

Shiv is a self-driven and passionate Machine learning Learner who is innovative in application design, development, testing, and deployment and provides program requirements into sustainable advanced technical solutions through JavaScript, Python, and other programs for continuous improvement of AI technologies.
LinkedIn