Calcule el intervalo de confianza usando SciPy

Este artículo tiene como objetivo ayudarlo a calcular los intervalos de confianza en Python usando SciPy. Antes de sumergirnos en la parte del cálculo, es necesario comprender cierta información básica sobre el intervalo de confianza.
Calcule el intervalo de confianza usando SciPy
Cuando medimos algo, siempre debemos calcular el grado de incertidumbre en el resultado. Los intervalos de confianza son una herramienta muy importante para calcular un rango dentro del cual podemos ubicar el verdadero valor de un observable con un alto grado de certeza.
Suponga que pregunta sobre la altura de uno. Uno podría decirte que mide 1,55 metros, pero eso no te dice nada sobre la incertidumbre de esta medida.
Los intervalos de confianza son intervalos en los que tenemos un alto nivel de confianza para determinar el verdadero valor del observable que se mide. Los científicos a menudo quieren un intervalo de confianza del 95 %, pero el 90 % o incluso el 99 % también es frecuente.
Entonces, si pregunta por la altura, uno debe darle una estimación o un intervalo de confianza, por ejemplo, con un 95% de confianza, uno tiene una altura entre 1,50 metros y 1,60 metros de altura.
Esta herramienta nos proporciona un intervalo para determinar el verdadero valor del observable.
Para calcular el intervalo de confianza, tenemos que usar la siguiente fórmula:

Dónde:
- La
x_barraes la media muestral. - La
zes el valor del nivel de confianza. - La
nes el tamaño de la muestra. - La
ses la desviación estándar de la muestra.
Supongamos que estamos trabajando con datos que tienen una muestra de menos de 30; entonces, se llama distribución t. Y para calcular su intervalo de confianza, utilizaremos la función t.interval() de la biblioteca scipy.stats.
Supongamos que tenemos conjuntos de datos de la población en diferentes pueblos. En este ejemplo, utilizaremos un conjunto de datos de tamaño (n=23) para calcular los intervalos de confianza del 95 % utilizando la distribución t y el método t.interval() en Python, con el parámetro de confianza establecido en 0,95.
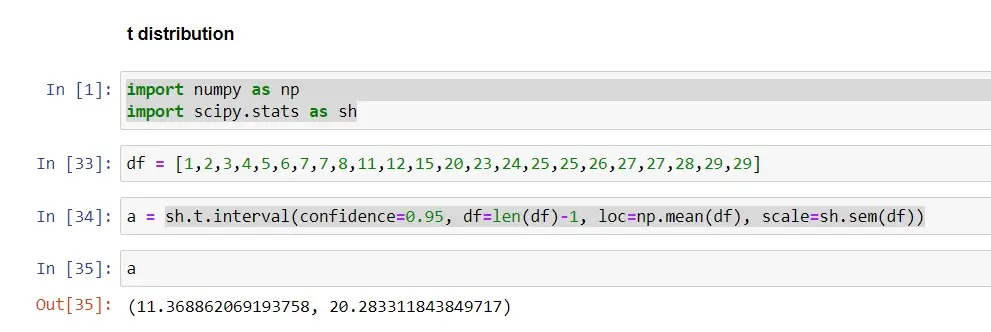
Aquí puedes ver que t.interval() toma los parámetros: confidence, data (df), loc (parámetro de ubicación) y scale.
Veamos la diferencia en el nivel de confianza cuando usamos el 99%.

Cuando usamos un intervalo de confianza del 95 %, el intervalo es (11,37-20,28), mientras que cuando usamos un intervalo de confianza del 99 %, el intervalo es (9,77-21,88). Al comparar ambos intervalos, podemos ver que el intervalo es más amplio cuando usamos un IC del 99 %, lo que significa que hay un 99 % de posibilidades de que el intervalo (9,77-21,88) contenga la población real.
¿Qué debemos hacer cuando tenemos un conjunto de datos de un tamaño de muestra superior a 30? Podemos usar el método norm.interval() de la biblioteca scipy.stats para obtener el intervalo de confianza para una media de población de un conjunto de datos dado cuando el conjunto de datos se distribuye normalmente en Python.
En este ejemplo, usaremos un conjunto de datos aleatorios de tamaño (n=60) para calcular los intervalos de confianza del 95% usando la distribución normal y el método norm.interval() en Python, con el parámetro alfa establecido en 0,95.
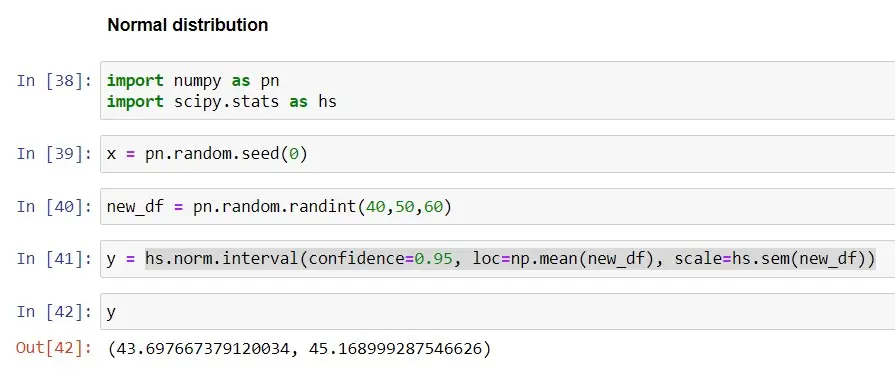
Veamos la diferencia en el nivel de confianza cuando usamos el 99%.

Cuando usamos un intervalo de confianza del 95%, el intervalo es (43,70-45,17); cuando usamos un intervalo de confianza del 99%, el intervalo es (43.47-45.41). Al comparar ambos intervalos, podemos ver que el intervalo es más amplio cuando usamos un IC del 99%, lo que significa que hay un 99% de posibilidades de que el intervalo (43.47-45.41) contenga la población real.
Los intervalos de confianza son fáciles de calcular y pueden proporcionar información valiosa a los analistas de datos y científicos. Proporcionan una estimación de error muy potente y, cuando se aplican correctamente, realmente pueden ayudarnos a extraer la mayor cantidad de información posible de nuestros datos.

Shiv is a self-driven and passionate Machine learning Learner who is innovative in application design, development, testing, and deployment and provides program requirements into sustainable advanced technical solutions through JavaScript, Python, and other programs for continuous improvement of AI technologies.
LinkedIn