在 Pandas 中刪除最後一行和最後一列
-
在 Pandas 中使用
drop()方法刪除行和列 -
在 Pandas 中使用
drop()方法刪除多索引 DataFrame 中的最後一行 -
使用
drop()方法刪除 Pandas 中的最後一列

本文探討了使用 Python 刪除 Pandas DataFrame 中特定行的不同方法。
大多數資料工程師和資料分析師都使用 Python,因為它具有驚人的資料集中包生態系統。其中一些是 Pandas、Matplotlib、SciPy 等。
Pandas 具有強大的匯入各種檔案型別和高效探索資料的能力。分析師可以使用 .drop() 方法刪除行和列中的各種元素。
在 Pandas 中使用 drop() 方法刪除行和列
drop() 的語法:
DataFrame.drop(
labels=None,
axis=0,
index=None,
columns=None,
level=None,
inplace=False,
errors="raise",
)
可用於刪除行和列的不同引數如下。
label- 指行或列的名稱。axis- 主要是從 0 開始的整數或字串值。index- 用作axis的替代品。level- 當資料在多個級別時用於指定級別。inplace- 如果條件為True,可以更改資料。errors- 如果該值設定為ignore,程式將忽略該特定錯誤並在不中斷的情況下執行。此外,raise可以用作ignore的替代品。
讓我們首先在 Pandas 中建立一個虛擬 DataFrame,以便我們使用我們的技巧來運算元據和探索。
import numpy as np
import pandas as pd
df = pd.DataFrame(np.arange(12).reshape(3, 4), columns=["P", "Q", "R", "S"])
print(df)
上述程式碼的輸出如下。
P Q R S
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
如你所見,DataFrame 已準備好處理。
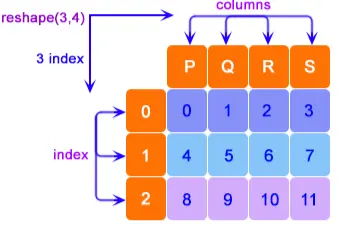
索引從 0 開始,列命名為 P、Q、R 和 S。reshape(x,y) 將行稱為 x,將列稱為 y。
讓我們使用下面的程式碼從表中刪除列。
print(df.drop(["Q", "R"], axis=1))
上述程式碼的輸出如下。
P S
0 0 3
1 4 7
2 8 11
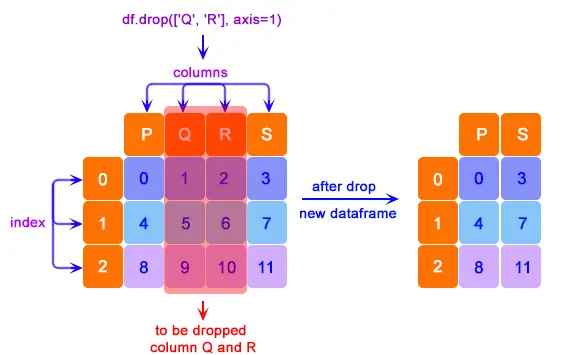
我們可以觀察到,列 Q 和 R 已從 DataFrame 中刪除。新形成的 DataFrame 僅由 P 和 S 組成。
在 Pandas 中使用 drop() 方法刪除多索引 DataFrame 中的最後一行
讓我們製作一個多索引 DataFrame,看看我們如何對該資料執行不同的操作。下面是用於生成多索引虛擬資料的程式碼。
midex = pd.MultiIndex(
levels=[["deer", "dog", "eagle"], ["speed", "weight", "length"]],
codes=[[0, 0, 0, 1, 1, 1, 2, 2, 2], [0, 1, 2, 0, 1, 2, 0, 1, 2]],
)
df = pd.DataFrame(
index=midex,
columns=["big", "small"],
data=[
[61, 36],
[29, 14],
[5.6, 2],
[43, 24],
[27, 11],
[4.5, 0.8],
[300, 250],
[3, 0.9],
[2.3, 0.3],
],
)
print(df)
上面程式碼的輸出如下。
big small
deer speed 61.0 36.0
weight 29.0 14.0
length 5.6 2.0
dog speed 43.0 24.0
weight 27.0 11.0
length 4.5 0.8
eagle speed 300.0 250.0
weight 3.0 0.9
length 2.3 0.3
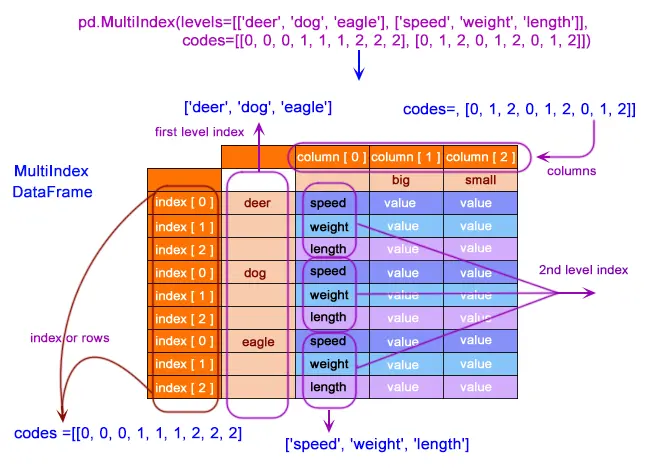
正如我們所看到的,這裡每個特徵的索引,deer、dog 和 eagle,都是從 0 開始的,與表中的整體索引無關。我們稱之為二級索引,一級索引仍然是 deer、dog 和 eagle。
我們可以提到要同時刪除的最後 n 個行和列。例如,我們可以提到我們要刪除最後 2 行或最後 3 列,程式會立即為我們執行此操作。
這是一個示例,說明我們如何從 Pandas 中的上述 DataFrame 中刪除最後一行。我們現在將從我們建立的虛擬 DataFrame 中刪除最後 3 行。
df.drop(df.tail(3).index, inplace=True) # drop last n rows
print(df)
在這裡,我們給出了 3 作為要刪除的最後 n 行數。
上述程式碼的輸出如下。
big small
deer speed 61.0 36.0
weight 29.0 14.0
length 5.6 2.0
dog speed 43.0 24.0
weight 27.0 11.0
length 4.5 0.8
同樣,我們可以以相同的方式從 DataFrame 中刪除列。
使用 drop() 方法刪除 Pandas 中的最後一列
刪除最後 n 列的語法如下。
df.drop(
df.columns[
[
-n,
]
],
axis=1,
inplace=True,
)
我們必須用上面程式碼中給出的 n 替換我們需要刪除的列數。如果我們想刪除 DataFrame 最右邊的一列,我們需要將 n 替換為 1。
上述程式碼的輸出如下。
big
deer speed 61.0
weight 29.0
length 5.6
dog speed 43.0
weight 27.0
length 4.5
因此,通過這種方式,你只需正確提及標籤或提及你要刪除的列或行的索引即可輕鬆執行不同的操作。
因此,使用上述技術,我們可以有效地找到在 Python 中從 Pandas DataFrame 中刪除行和列的方法。
