在 Pandas 中删除最后一行和最后一列
-
在 Pandas 中使用
drop()方法删除行和列 -
在 Pandas 中使用
drop()方法删除多索引 DataFrame 中的最后一行 -
使用
drop()方法删除 Pandas 中的最后一列

本文探讨了使用 Python 删除 Pandas DataFrame 中特定行的不同方法。
大多数数据工程师和数据分析师都使用 Python,因为它具有惊人的数据集中包生态系统。其中一些是 Pandas、Matplotlib、SciPy 等。
Pandas 具有强大的导入各种文件类型和高效探索数据的能力。分析师可以使用 .drop() 方法删除行和列中的各种元素。
在 Pandas 中使用 drop() 方法删除行和列
drop() 的语法:
DataFrame.drop(
labels=None,
axis=0,
index=None,
columns=None,
level=None,
inplace=False,
errors="raise",
)
可用于删除行和列的不同参数如下。
label- 指行或列的名称。axis- 主要是从 0 开始的整数或字符串值。index- 用作axis的替代品。level- 当数据在多个级别时用于指定级别。inplace- 如果条件为True,可以更改数据。errors- 如果该值设置为ignore,程序将忽略该特定错误并在不中断的情况下执行。此外,raise可以用作ignore的替代品。
让我们首先在 Pandas 中创建一个虚拟 DataFrame,以便我们使用我们的技巧来操作数据和探索。
import numpy as np
import pandas as pd
df = pd.DataFrame(np.arange(12).reshape(3, 4), columns=["P", "Q", "R", "S"])
print(df)
上述代码的输出如下。
P Q R S
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
如你所见,DataFrame 已准备好处理。
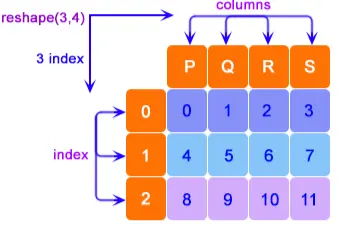
索引从 0 开始,列命名为 P、Q、R 和 S。reshape(x,y) 将行称为 x,将列称为 y。
让我们使用下面的代码从表中删除列。
print(df.drop(["Q", "R"], axis=1))
上述代码的输出如下。
P S
0 0 3
1 4 7
2 8 11
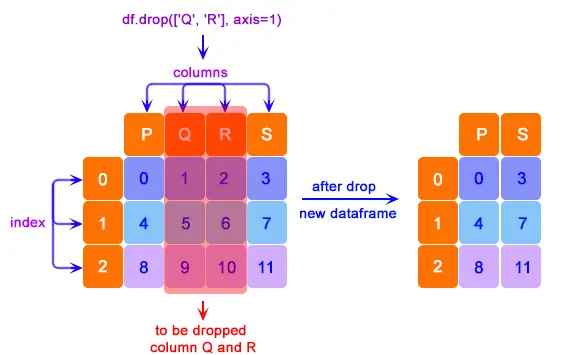
我们可以观察到,列 Q 和 R 已从 DataFrame 中删除。新形成的 DataFrame 仅由 P 和 S 组成。
在 Pandas 中使用 drop() 方法删除多索引 DataFrame 中的最后一行
让我们制作一个多索引 DataFrame,看看我们如何对该数据执行不同的操作。下面是用于生成多索引虚拟数据的代码。
midex = pd.MultiIndex(
levels=[["deer", "dog", "eagle"], ["speed", "weight", "length"]],
codes=[[0, 0, 0, 1, 1, 1, 2, 2, 2], [0, 1, 2, 0, 1, 2, 0, 1, 2]],
)
df = pd.DataFrame(
index=midex,
columns=["big", "small"],
data=[
[61, 36],
[29, 14],
[5.6, 2],
[43, 24],
[27, 11],
[4.5, 0.8],
[300, 250],
[3, 0.9],
[2.3, 0.3],
],
)
print(df)
上面代码的输出如下。
big small
deer speed 61.0 36.0
weight 29.0 14.0
length 5.6 2.0
dog speed 43.0 24.0
weight 27.0 11.0
length 4.5 0.8
eagle speed 300.0 250.0
weight 3.0 0.9
length 2.3 0.3
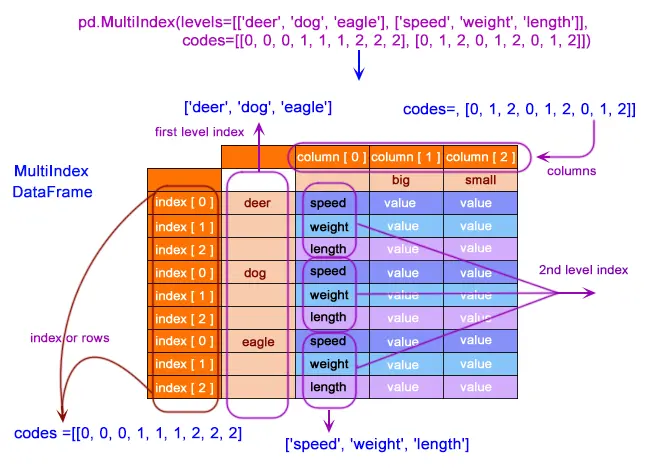
正如我们所看到的,这里每个特征的索引,deer、dog 和 eagle,都是从 0 开始的,与表中的整体索引无关。我们称之为二级索引,一级索引仍然是 deer、dog 和 eagle。
我们可以提到要同时删除的最后 n 个行和列。例如,我们可以提到我们要删除最后 2 行或最后 3 列,程序会立即为我们执行此操作。
这是一个示例,说明我们如何从 Pandas 中的上述 DataFrame 中删除最后一行。我们现在将从我们创建的虚拟 DataFrame 中删除最后 3 行。
df.drop(df.tail(3).index, inplace=True) # drop last n rows
print(df)
在这里,我们给出了 3 作为要删除的最后 n 行数。
上述代码的输出如下。
big small
deer speed 61.0 36.0
weight 29.0 14.0
length 5.6 2.0
dog speed 43.0 24.0
weight 27.0 11.0
length 4.5 0.8
同样,我们可以以相同的方式从 DataFrame 中删除列。
使用 drop() 方法删除 Pandas 中的最后一列
删除最后 n 列的语法如下。
df.drop(
df.columns[
[
-n,
]
],
axis=1,
inplace=True,
)
我们必须用上面代码中给出的 n 替换我们需要删除的列数。如果我们想删除 DataFrame 最右边的一列,我们需要将 n 替换为 1。
上述代码的输出如下。
big
deer speed 61.0
weight 29.0
length 5.6
dog speed 43.0
weight 27.0
length 4.5
因此,通过这种方式,你只需正确提及标签或提及你要删除的列或行的索引即可轻松执行不同的操作。
因此,使用上述技术,我们可以有效地找到在 Python 中从 Pandas DataFrame 中删除行和列的方法。
