NumPy와 Python을 사용하여 경사하강법 구현
머신러닝은 요즘 트렌드입니다. 모든 회사 또는 스타트업은 기계 학습을 사용하여 실제 문제를 해결하는 솔루션을 제시하려고 합니다. 이러한 문제를 해결하기 위해 프로그래머는 일부 필수적이고 가치 있는 데이터에 대해 훈련된 기계 학습 모델을 구축합니다. 모델을 훈련하는 동안 선택할 수 있는 많은 전술, 알고리즘 및 방법이 있습니다. 일부는 작동하고 일부는 작동하지 않을 수 있습니다.
일반적으로 Python은 이러한 모델을 훈련하는 데 사용됩니다. Python은 기계 학습 개념을 쉽게 구현할 수 있도록 하는 수많은 라이브러리를 지원합니다. 그러한 개념 중 하나가 경사하강법입니다. 이 기사에서는 Python을 사용하여 경사하강법을 구현하는 방법을 배웁니다.
경사하강법
Gradient Descent는 기계 학습 모델을 훈련하는 동안 사용되는 볼록 함수 기반 최적화 알고리즘입니다. 이 알고리즘은 문제를 보다 효율적으로 해결하기 위해 최상의 모델 매개변수를 찾는 데 도움이 됩니다. 일부 데이터에 대해 기계 학습 모델을 훈련하는 동안 이 알고리즘은 각 반복에 대한 모델 매개변수를 조정하여 최종적으로 미분 가능한 함수에 대한 전역 최소값, 때로는 국소 최소값을 산출합니다.
모델 매개변수를 조정하는 동안 학습률이라는 값은 값을 조정해야 하는 양을 결정합니다. 이 값이 너무 크면 학습이 빨라지고 모델이 과소적합될 수 있습니다. 그리고 이 값이 너무 작으면 학습이 느려지고 모델을 학습 데이터에 과적합하게 될 수 있습니다. 따라서 우리는 균형을 유지하고 마침내 좋은 정확도로 좋은 기계 학습 모델을 산출하는 값을 제시해야 합니다.
Python을 사용한 경사하강법 구현
이제 간단한 경사 하강법 이론을 마쳤으므로 NumPy 모듈과 Python 프로그래밍 언어를 사용하여 예제를 통해 이를 구현하는 방법을 이해하겠습니다.
y = mx + c 또는 y = ax + b 형식의 y = 0.5x + 2 방정식에 대한 기계 학습 모델을 훈련합니다. 기본적으로 이 방정식을 사용하여 생성된 데이터에 대해 기계 학습 모델을 훈련합니다. 모델은 m과 c 또는 a와 b, 즉 기울기와 절편의 값을 각각 추측합니다. 기계 학습 모델은 학습할 데이터와 정확도를 테스트하기 위한 테스트 데이터가 필요하므로 Python 스크립트를 사용하여 동일한 데이터를 생성합니다. 이 작업을 수행하기 위해 선형 회귀를 수행합니다.
훈련 입력 및 테스트 입력은 다음과 같은 형식입니다. 2차원 NumPy 배열. 이 예에서 입력은 단일 정수 값이고 출력은 단일 정수 값입니다. 단일 입력은 정수 및 부동 소수점 값의 배열일 수 있으므로 코드 또는 동적 특성의 재사용성을 촉진하기 위해 다음 형식이 사용됩니다.
[[1], [2], [3], [4], [5], [6], [7], ...]
그리고 훈련 레이블과 테스트 레이블은 다음과 같은 형식입니다. 1차원 NumPy 배열.
[1, 4, 9, 16, 25, 36, 49, ...]
파이썬 코드
다음은 위의 예를 구현한 것입니다.
import random
import numpy as np
import matplotlib.pyplot as plt
def linear_regression(inputs, targets, epochs, learning_rate):
"""
A utility function to run linear regression and get weights and bias
"""
costs = [] # A list to store losses at each epoch
values_count = inputs.shape[1] # Number of values within a single input
size = inputs.shape[0] # Total number of inputs
weights = np.zeros((values_count, 1)) # Weights
bias = 0 # Bias
for epoch in range(epochs):
# Calculating the predicted values
predicted = np.dot(inputs, weights) + bias
loss = predicted - targets # Calculating the individual loss for all the inputs
d_weights = np.dot(inputs.T, loss) / (2 * size) # Calculating gradient
d_bias = np.sum(loss) / (2 * size) # Calculating gradient
weights = weights - (learning_rate * d_weights) # Updating the weights
bias = bias - (learning_rate * d_bias) # Updating the bias
cost = np.sqrt(
np.sum(loss ** 2) / (2 * size)
) # Root Mean Squared Error Loss or RMSE Loss
costs.append(cost) # Storing the cost
print(
f"Iteration: {epoch + 1} | Cost/Loss: {cost} | Weight: {weights} | Bias: {bias}"
)
return weights, bias, costs
def plot_test(inputs, targets, weights, bias):
"""
A utility function to test the weights
"""
predicted = np.dot(inputs, weights) + bias
predicted = predicted.astype(int)
plt.plot(
predicted,
[i for i in range(len(predicted))],
color=np.random.random(3),
label="Predictions",
linestyle="None",
marker="x",
)
plt.plot(
targets,
[i for i in range(len(targets))],
color=np.random.random(3),
label="Targets",
linestyle="None",
marker="o",
)
plt.xlabel("Indexes")
plt.ylabel("Values")
plt.title("Predictions VS Targets")
plt.legend()
plt.show()
def rmse(inputs, targets, weights, bias):
"""
A utility function to calculate RMSE or Root Mean Squared Error
"""
predicted = np.dot(inputs, weights) + bias
mse = np.sum((predicted - targets) ** 2) / (2 * inputs.shape[0])
return np.sqrt(mse)
def generate_data(m, n, a, b):
"""
A function to generate training data, training labels, testing data, and testing inputs
"""
x, y, tx, ty = [], [], [], []
for i in range(1, m + 1):
x.append([float(i)])
y.append([float(i) * a + b])
for i in range(n):
tx.append([float(random.randint(1000, 100000))])
ty.append([tx[-1][0] * a + b])
return np.array(x), np.array(y), np.array(tx), np.array(ty)
learning_rate = 0.0001 # Learning rate
epochs = 200000 # Number of epochs
a = 0.5 # y = ax + b
b = 2.0 # y = ax + b
inputs, targets, train_inputs, train_targets = generate_data(300, 50, a, b)
weights, bias, costs = linear_regression(
inputs, targets, epochs, learning_rate
) # Linear Regression
indexes = [i for i in range(1, epochs + 1)]
plot_test(train_inputs, train_targets, weights, bias) # Testing
print(f"Weights: {[x[0] for x in weights]}")
print(f"Bias: {bias}")
print(
f"RMSE on training data: {rmse(inputs, targets, weights, bias)}"
) # RMSE on training data
print(
f"RMSE on testing data: {rmse(train_inputs, train_targets, weights, bias)}"
) # RMSE on testing data
plt.plot(indexes, costs)
plt.xlabel("Epochs")
plt.ylabel("Overall Cost/Loss")
plt.title(f"Calculated loss over {epochs} epochs")
plt.show()
Python 코드에 대한 간략한 설명
코드에는 다음 메서드가 구현되어 있습니다.
linear_regression(inputs, target, epochs, learning_rate): 이 함수는 데이터에 대해 선형 회귀를 수행하고 각 epoch에 대한 모델 가중치, 모델 편향 및 중간 비용 또는 손실을 반환합니다.plot_test(inputs, targets, weights, bias): 이 함수는 입력, 목표, 가중치 및 편향을 받아들이고 입력에 대한 출력을 예측합니다. 그런 다음 실제 값에서 모델 예측이 얼마나 근접했는지 보여주는 그래프를 그립니다.rmse(inputs, targets, weights, bias): 이 함수는 일부 입력, 가중치, 편향, 목표 또는 레이블에 대한 제곱 평균 제곱근 오차를 계산하고 반환합니다.generate_data(m, n, a, b): 이 함수는y = ax + b방정식을 사용하여 학습할 기계 학습 모델에 대한 샘플 데이터를 생성합니다. 훈련 및 테스트 데이터를 생성합니다.m및n은 각각 생성된 훈련 및 테스트 샘플의 수를 나타냅니다.
다음은 위 코드의 실행 흐름입니다.
-
generate_data()메소드는 일부 샘플 학습 입력, 학습 레이블, 테스트 입력 및 테스트 레이블을 생성하기 위해 호출됩니다. -
학습률, Epoch 횟수 등 일부 상수가 초기화됩니다.
-
linear_regression()메서드를 호출하여 생성된 학습 데이터에 대해 선형 회귀를 수행하고 각 epoch에서 찾은 가중치, 편향, 비용을 저장합니다. -
모델 가중치와 편향은 생성된 테스트 데이터를 사용하여 테스트되고 예측이 실제 값에 얼마나 가까운지를 보여주는 플롯이 그려집니다.
-
훈련 및 테스트 데이터에 대한 RMSE 손실이 계산되고 인쇄됩니다.
-
각 에포크에 대해 발견된 비용은
Matplotlib모듈(Python용 그래프 플로팅 라이브러리)을 사용하여 플롯됩니다.
산출
Python 코드는 각 에포크 또는 반복에 대해 모델 교육 상태를 콘솔에 출력합니다. 다음과 같이 됩니다.
...
Iteration: 199987 | Cost/Loss: 0.05856315870190882 | Weight: [[0.5008289]] | Bias: 1.8339454694938624
Iteration: 199988 | Cost/Loss: 0.05856243033468181 | Weight: [[0.50082889]] | Bias: 1.8339475347628937
Iteration: 199989 | Cost/Loss: 0.05856170197651294 | Weight: [[0.50082888]] | Bias: 1.8339496000062387
Iteration: 199990 | Cost/Loss: 0.058560973627402625 | Weight: [[0.50082887]] | Bias: 1.8339516652238976
Iteration: 199991 | Cost/Loss: 0.05856024528735169 | Weight: [[0.50082886]] | Bias: 1.8339537304158708
Iteration: 199992 | Cost/Loss: 0.05855951695635694 | Weight: [[0.50082885]] | Bias: 1.8339557955821586
Iteration: 199993 | Cost/Loss: 0.05855878863442534 | Weight: [[0.50082884]] | Bias: 1.8339578607227613
Iteration: 199994 | Cost/Loss: 0.05855806032154768 | Weight: [[0.50082883]] | Bias: 1.8339599258376793
...
모델이 훈련되면 프로그램은 모델을 테스트하고 모델 예측과 실제 값으로 플롯을 그립니다. 훈련된 플롯은 아래 표시된 것과 유사합니다. 테스트 데이터는 random 모듈을 사용하여 생성되므로 무작위 값이 즉석에서 생성되므로 아래에 표시된 그래프가 귀하의 것과 다를 가능성이 큽니다.
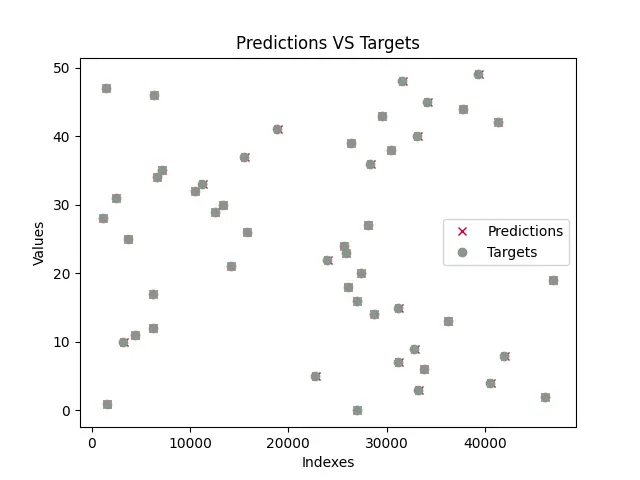
보시다시피 예측은 모든 실제 값과 거의 겹칩니다(예측은 x로 표시되고 목표는 o로 표시됨). 이는 모델이 a와 b 또는 m과 c의 값을 거의 성공적으로 예측했음을 의미합니다.
다음으로, 프로그램은 모델을 훈련하는 동안 발견된 모든 손실을 인쇄합니다.
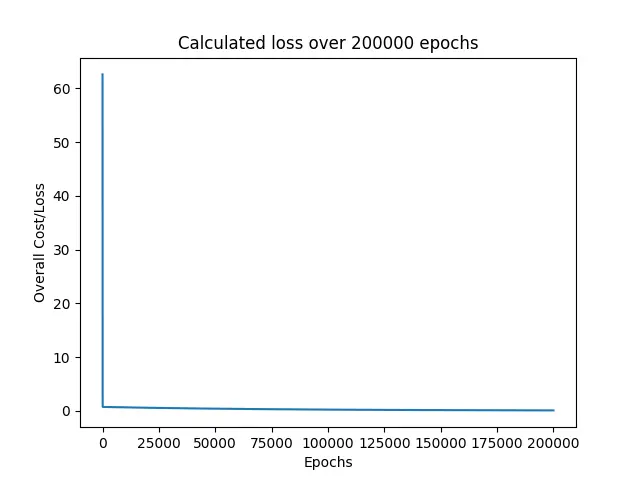
우리가 볼 수 있듯이, 손실은 즉시 0에 가까운 60 부근에서 떨어졌고 나머지 시대 동안 계속 그 주변을 유지했습니다.
마지막으로 훈련 및 테스트 데이터에 대한 RMSE 손실을 인쇄하고 a 및 b 또는 모델 매개변수에 대한 예측 값을 인쇄했습니다.
Weights: [0.5008287639956263]
Bias: 1.8339723159878247
RMSE on training data: 0.05855296238504223
RMSE on testing data: 30.609530314187527
이 예에 사용한 방정식은 y = 0.5x + 2이며, 여기서 a = 0.5 및 b = 2입니다. 그리고 모델은 실제 값에 매우 가까운 a = 0.50082와 b = 1.83397을 예측했습니다. 그래서 우리의 예측이 실제 목표와 겹쳤습니다.
이 예에서는 epoch 수를 200000으로 설정하고 학습률을 0.0001로 설정했습니다. 다행히도 이것은 매우 훌륭하고 거의 완벽한 결과를 제공한 구성 세트 중 하나일 뿐입니다. 이 기사의 독자들이 이러한 값을 가지고 놀고 더 나은 결과를 산출하는 일부 값 세트를 생각해 낼 수 있는지 확인하는 것이 좋습니다.

Vaibhav is an artificial intelligence and cloud computing stan. He likes to build end-to-end full-stack web and mobile applications. Besides computer science and technology, he loves playing cricket and badminton, going on bike rides, and doodling.