Python에서 이상값 감지 및 제거
데이터 세트 내에서 이상값은 나머지 데이터 세트와 비정상적으로 다른 항목입니다. 그러나 이 정의는 데이터 분석가가 이상에 대한 임계값을 결정할 수 있는 충분한 공간을 제공합니다.
측정 오류, 실행 오류, 샘플링 문제, 잘못된 데이터 입력 또는 자연 변동으로 인해 이상값이 있습니다. 이상값이 있으면 오류가 증가하고 편향이 생기며 통계 모델에 상당한 영향을 줄 수 있으므로 이상값을 제거하는 것이 중요합니다.
이 자습서에서는 데이터 세트에서 이상값을 감지하고 제거하는 방법에 대해 설명합니다. scikit-learn 라이브러리의 일부인 잘 알려진 Boston Housing 데이터 세트에 기술을 적용하여 이를 시연합니다.
이 기사는 이상값을 감지하는 방법을 탐색한 다음 이 기술을 사용하여 이상값을 제거하는 방법을 논의하도록 구성되어 있습니다.
튜토리얼을 따라하려면 Google Colab을 사용하여 브라우저 내에서 수행할 수 있습니다. 새 노트북을 열고 코드를 작성하는 것만큼 간단합니다.
다음은 단계별 Google Colab 시작 가이드입니다.
환경 설정 및 데이터 세트 로드
사용할 몇 가지 라이브러리를 가져오는 것으로 시작합니다.
import sklearn
from sklearn.datasets import load_boston
import pandas as pd
import matplotlib.pyplot as plt
그런 다음 Boston Housing 데이터 세트를 로드할 수 있습니다.
bh_dataset = load_boston()
데이터세트에는 데이터세트의 모든 기능 이름이 포함된 배열인 feature_names 속성이 포함되어 있습니다. data 속성에는 모든 데이터가 포함됩니다.
둘을 분리한 다음 결합하여 Pandas 데이터 프레임을 만듭니다.
columns = bh_dataset.feature_names
df_boston = pd.DataFrame(bh_dataset.data)
df_boston.columns = columns
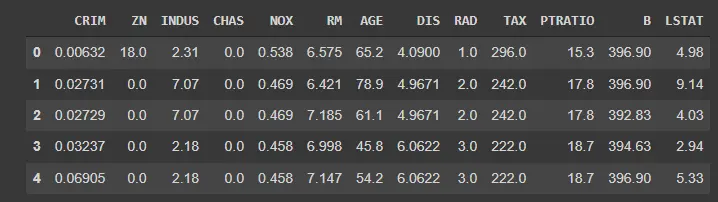
이제 df_boston에는 전체 데이터 세트가 포함됩니다. Pandas는 .head() 메서드를 사용하여 데이터세트의 미리보기를 얻을 수 있는 깨끗하고 간단한 방법을 제공합니다.
아래와 같이 함수를 호출하면 데이터 세트의 미리 보기가 표시됩니다(아래에도 표시됨).
df_boston.head()
출력:
Python에서 데이터 세트 시각화
데이터 세트를 시각화하기 위한 박스 플롯 생성
Box-and-whisker plot이라고도 하는 Box Plot%20and%20averages.)는 데이터를 시각화하는 간단하고 효과적인 방법이며 이상값을 찾는 데 특히 유용합니다. Python에서는 [seaborn] 라이브러리를 사용하여 데이터 세트의 Box plot을 생성할 수 있습니다.
import seaborn as sns
sns.boxplot(df_boston["DIS"])
위 코드의 플롯:
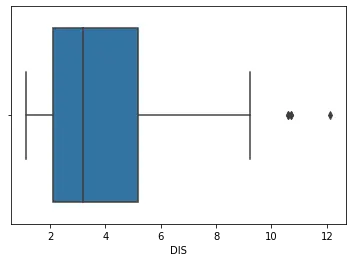
'DIS'로 데이터 세트를 인덱싱한다는 것은 DIS 열을 박스 플롯 함수로 전달하는 것을 의미합니다. 박스 플롯은 1차원으로 생성됩니다.
따라서 하나의 변수만 입력으로 사용합니다. 변수를 변경하여 다른 박스 플롯을 생성할 수 있습니다.
위의 도표에서 10 이상의 값이 이상값임을 알 수 있습니다. 이제 이것을 이 데이터 세트의 이상값에 대한 표준으로 사용합니다.
아래 예와 같이 np.where를 사용하여 이 기준에 맞는 데이터 세트의 항목을 선택할 수 있습니다.
import numpy as np
DIS_subset = df_boston["DIS"]
print(np.where(DIS_subset > 10))
출력:

이들은 위의 기준에 의해 정의된 이상치인 데이터 포인트를 포함하는 배열 인덱스입니다. 이 기사의 끝에서 이러한 인덱스를 사용하여 데이터 세트에서 이상값을 제거하는 방법을 보여줍니다.
데이터 세트를 시각화하기 위한 산점도 생성
박스 플롯은 단일 차원에 대한 데이터가 있을 때 사용할 수 있습니다. 그러나 데이터 쌍이 있거나 분석 중인 관계에 두 개의 변수가 포함된 경우 산점도를 사용할 수 있습니다.
Python을 사용하면 Matplotlib를 사용하여 산점도를 생성할 수 있습니다. 다음은 산점도를 인쇄하는 코드 예제입니다.
fig, axes = plt.subplots(figsize=(18, 10))
axes.scatter(df_boston["INDUS"], df_boston["TAX"])
axes.set_xlabel("Non-retail business acres per town")
axes.set_ylabel("Tax Rate")
plt.show()
출력:
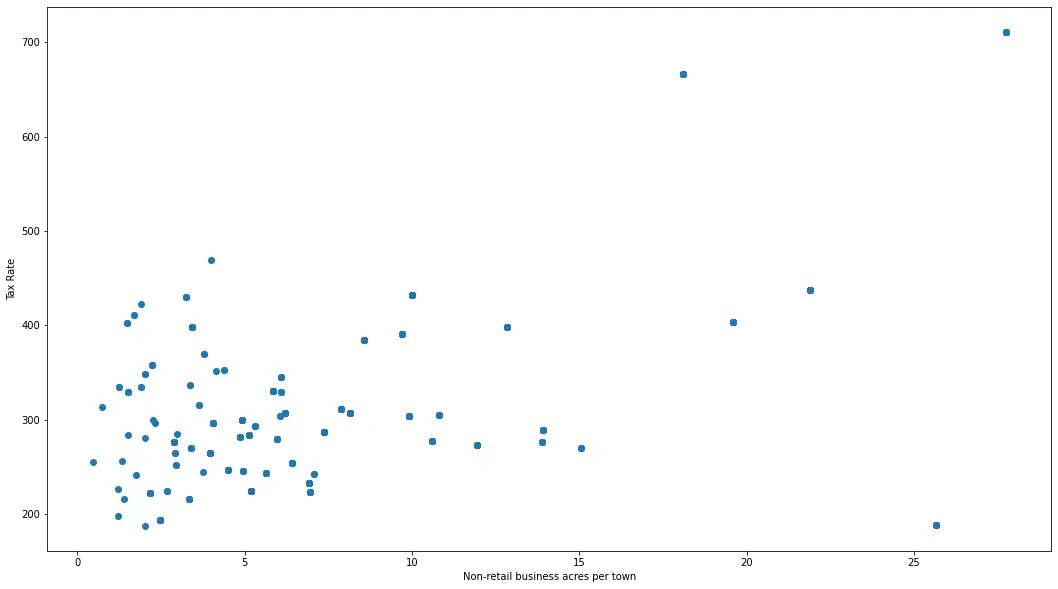
안구 추정치를 얻으면 일반적으로 x축에서 20보다 큰 값은 이상치처럼 보이고 y축에서 500보다 큰 값은 이상치처럼 보입니다. 이를 이상값을 제거하기 위한 표준으로 사용할 수 있습니다.
이 기준과 일치하는 인덱스를 감지하기 위해 이전에 사용한 것과 동일한 numpy 기능을 사용합니다.
print(np.where((df_boston["INDUS"] > 20) & (df_boston["TAX"] > 500)))
출력:

Python에서 이상값을 감지하는 수학적 방법
Python에서 이상치를 감지하기 위한 Z-Score 계산
[Z 점수](표준 점수라고도 함)는 데이터 포인트가 평균에서 얼마나 많은 표준 편차가 있는지 측정하는 통계입니다. Z 점수가 클수록 데이터 포인트가 평균에서 더 멀리 떨어져 있음을 나타냅니다.
이것은 대부분의 데이터 포인트가 정규 분포 데이터 세트의 평균 근처에 있기 때문에 중요합니다. Z 점수가 큰 데이터 포인트는 대부분의 데이터 포인트에서 멀리 떨어져 있으며 이상치일 가능성이 높습니다.
Scipy의 유틸리티를 사용하여 Z 점수를 생성할 수 있습니다. 다시 한 번 방법을 적용하기 위해 데이터 세트의 특정 열을 선택합니다.
from scipy import stats
z = stats.zscore(df_boston["DIS"])
z_abs = np.abs(z)
위 코드의 첫 번째 줄은 라이브러리를 가져오는 것입니다. 두 번째 줄은 scipy.zscore 메서드를 사용하여 선택한 데이터 세트의 각 데이터 포인트에 대한 Z 점수를 계산합니다.
세 번째 줄에는 모든 값을 양수 값으로 변환하는 numpy 함수가 있습니다. 이는 간단한 필터를 적용하는 데 도움이 됩니다.
배열을 인쇄하면 다음과 같이 표시됩니다.
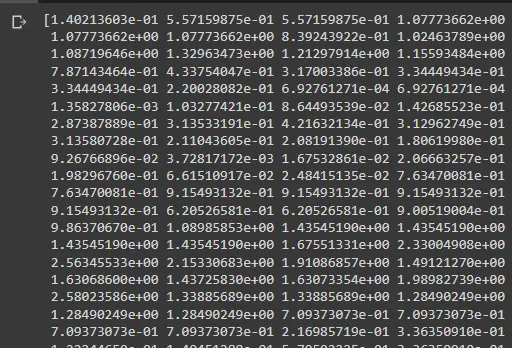
이 이미지에는 모든 점이 포함되어 있지 않지만 z_abs를 인쇄하여 표시할 수 있습니다.
이제 어떤 점이 이상치로 간주되는지에 대한 기준을 결정해야 합니다. 정규 분포로 작업할 때 평균보다 3 표준 편차가 높은 데이터 포인트는 이상치로 간주됩니다.
99.7%의 포인트가 정규 분포에서 평균의 3 표준 편차 내에 있기 때문입니다. 이는 Z 점수가 3보다 큰 모든 포인트를 제거해야 함을 의미합니다.
다시 한 번 np.where 기능을 사용하여 이상치 지수를 찾습니다. np.where 기능에 대해 자세히 알아보십시오.
print(np.where(z_abs > 3))
출력:

Python에서 이상값을 감지하기 위한 사분위수 범위 계산
이것이 우리가 논의할 마지막 방법입니다. 이 방법은 이상값을 제거하여 데이터를 정리하는 연구에서 매우 일반적으로 사용됩니다.
사분위수 범위(IQR)는 데이터의 세 번째 사분위수와 첫 번째 사분위수 간의 차이입니다. Q1을 첫 번째 사분위수로 정의합니다. 즉, 데이터의 25%가 최소값과 Q1 사이에 있음을 의미합니다.
Q3을 데이터의 세 번째 사분위수로 정의합니다. 즉, 데이터의 75%가 데이터 세트 최소값과 Q3 사이에 있음을 의미합니다.
이러한 정의를 통해 상한 및 하한을 정의할 수 있습니다. 하한 아래 및 상한 위의 모든 데이터 포인트는 이상값으로 간주됩니다.
Lower bound = Q1 - (1.5 * IQR)
Upper bound = Q3 + (1.5 * IQR)
1.5는 임의적으로 보일 수 있지만 수학적 의미가 있습니다. 자세한 수학에 관심이 있다면 이 기사를 보십시오.
이것은 평균에서 최소 3 표준 편차 떨어진 데이터를 찾는 것과 대략 동일하다는 것을 알아야 합니다(데이터가 정규 분포된 경우). 실제로 이 방법은 매우 효과적입니다.
Python에서는 NumPy 함수 percentile()을 사용하여 Q1 및 Q3을 찾은 다음 IQR을 찾을 수 있습니다.
Q1 = np.percentile(df_boston["DIS"], 25, interpolation="midpoint")
Q3 = np.percentile(df_boston["DIS"], 75, interpolation="midpoint")
IQR = Q3 - Q1
데이터 세트에서 IQR을 인쇄하고 다음을 얻습니다.

이제 다음과 같이 상한 및 하한을 정의합니다.
upper_bound = df_boston["DIS"] >= (Q3 + 1.5 * IQR)
lower_bound = df_boston["DIS"] <= (Q1 - 1.5 * IQR)
다시 한 번 np.where를 사용하여 기준에 맞는 포인트에 대한 인덱스를 얻을 수 있습니다.
print(np.where(upper_bound))
print(np.where(lower_bound))
출력:

Python의 DataFrame에서 이상값 제거
dataframe.drop 기능을 사용하여 이상점을 삭제합니다. 기능에 대한 자세한 정보를 보려면 여기를 클릭하십시오.
이를 위해 이상값의 인덱스가 포함된 목록을 함수에 전달해야 합니다. 다음과 같이 할 수 있습니다.
upper_points = np.where(upper_bound)
df_boston.drop(upper_points[0], inplace=True)
포인트가 삭제되었는지 여부를 확인하기 위해 데이터의 모양을 인쇄하여 남아 있는 항목 수를 확인할 수 있습니다.
print(df_boston.shape)
df_boston.drop(upper_points[0], inplace=True)
print(df_boston.shape)
출력:
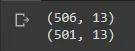
축하해요! 이는 이상값을 성공적으로 제거했음을 확인합니다. 위에서 사용한 방법을 사용하여 인덱스 목록을 전달하고 드롭 함수에 전달할 수 있습니다.

Husnain is a professional Software Engineer and a researcher who loves to learn, build, write, and teach. Having worked various jobs in the IT industry, he especially enjoys finding ways to express complex ideas in simple ways through his content. In his free time, Husnain unwinds by thinking about tech fiction to solve problems around him.
LinkedIn