Ausreißer in Python erkennen und entfernen
- Richten Sie die Umgebung ein und laden Sie den Datensatz
- Visualisieren Sie den Datensatz in Python
- Mathematische Methoden zur Erkennung der Ausreißer in Python
- Entfernen Sie die Ausreißer aus dem DataFrame in Python
Innerhalb eines Datensatzes ist ein Ausreißer ein Element, das sich ungewöhnlich vom Rest des Datensatzes unterscheidet. Diese Definition gibt dem Datenanalysten jedoch genügend Spielraum, um den Schwellenwert für Anomalien festzulegen.
Wir haben Ausreißer aufgrund von Messfehlern, Ausführungsfehlern, Stichprobenproblemen, falscher Dateneingabe oder sogar natürlichen Schwankungen. Das Entfernen von Ausreißern ist wichtig, da ihre Anwesenheit Fehler erhöhen, Verzerrungen einführen und statistische Modelle erheblich beeinflussen kann.
In diesem Lernprogramm werden Methoden zum Erkennen und Entfernen von Ausreißern aus einem Datensatz erörtert. Wir werden dies demonstrieren, indem wir unsere Techniken auf einen bekannten Boston Housing-Datensatz anwenden, der Teil der scikit-learn-Bibliothek ist.
Der Artikel ist so strukturiert, dass wir eine Methode zum Erkennen von Ausreißern untersuchen und dann diskutieren, wie die Technik zum Entfernen von Ausreißern verwendet werden kann.
Wenn Sie dem Tutorial folgen möchten, können Sie dies in Ihrem Browser mit Google Colab tun. Es ist so einfach wie das Öffnen eines neuen Notizbuchs und das Schreiben von Code.
Hier ist eine Schritt-für-Schritt-Anleitung für die ersten Schritte mit Google Colab.
Richten Sie die Umgebung ein und laden Sie den Datensatz
Wir beginnen mit dem Importieren einiger Bibliotheken, die wir verwenden werden.
import sklearn
from sklearn.datasets import load_boston
import pandas as pd
import matplotlib.pyplot as plt
Wir können dann den Boston Housing-Datensatz laden.
bh_dataset = load_boston()
Der Datensatz enthält ein feature_names-Attribut, ein Array, das die Namen aller Features im Datensatz enthält. Das Attribut data enthält alle Daten.
Wir werden die beiden trennen und dann kombinieren, um einen Pandas-Datenrahmen zu erstellen.
columns = bh_dataset.feature_names
df_boston = pd.DataFrame(bh_dataset.data)
df_boston.columns = columns
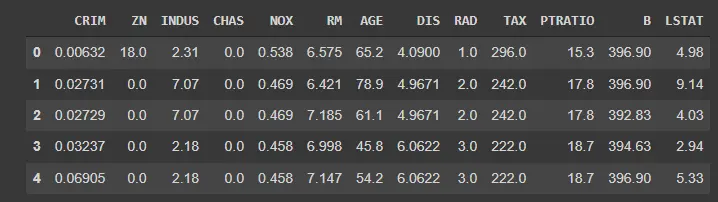
df_boston enthält jetzt den gesamten Datensatz. Pandas ermöglicht uns eine saubere und unkomplizierte Möglichkeit, eine Vorschau unseres Datensatzes mit der Methode .head() zu erhalten.
Wenn Sie die Funktion wie unten gezeigt aufrufen, wird eine Vorschau des Datensatzes angezeigt (ebenfalls unten gezeigt).
df_boston.head()
Ausgang:
Visualisieren Sie den Datensatz in Python
Generieren Sie einen Boxplot, um den Datensatz zu visualisieren
Ein Box-Plot%20and%20Averages.), auch bekannt als Box-and-Whisker-Plot, ist eine einfache und effektive Methode zur Visualisierung Ihrer Daten und ist besonders hilfreich bei der Suche nach Ausreißern. In Python können wir die Bibliothek [seaborn] verwenden, um einen Boxplot unseres Datensatzes zu generieren.
import seaborn as sns
sns.boxplot(df_boston["DIS"])
Die Handlung für den obigen Code:
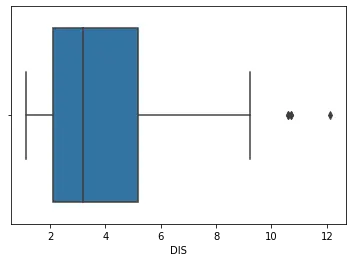
Das Indizieren des Datensatzes mit DIS bedeutet, dass die Spalte DIS in die Boxplot-Funktion übergeben wird. Der Boxplot wird eindimensional erstellt.
Daher wird nur eine Variable als Eingabe verwendet. Die Variable kann geändert werden, um verschiedene Boxplots zu erzeugen.
Im Diagramm oben sehen wir, dass die Werte über 10 Ausreißer sind. Wir werden dies nun als Standard für Ausreißer in diesem Datensatz verwenden.
Wir können Einträge im Datensatz auswählen, die dieses Kriterium erfüllen, indem wir das np.where verwenden, wie im folgenden Beispiel gezeigt.
import numpy as np
DIS_subset = df_boston["DIS"]
print(np.where(DIS_subset > 10))
Ausgang:

Dies sind Array-Indizes, die Datenpunkte enthalten, die gemäß dem obigen Kriterium Ausreißer sind. Am Ende des Artikels zeigen wir Ihnen, wie Sie diese Indizes verwenden, um Ausreißer aus Ihrem Datensatz zu entfernen.
Generieren Sie ein Streudiagramm, um den Datensatz zu visualisieren
Boxplots können verwendet werden, wenn wir Daten über eine einzelne Dimension haben. Wir können jedoch ein Streudiagramm verwenden, wenn wir gepaarte Daten haben oder die Beziehung, die wir analysieren, zwei Variablen umfasst.
Mit Python können wir Streudiagramme mit Matplotlib erstellen. Im Folgenden finden Sie ein Codebeispiel zum Drucken eines Streudiagramms.
fig, axes = plt.subplots(figsize=(18, 10))
axes.scatter(df_boston["INDUS"], df_boston["TAX"])
axes.set_xlabel("Non-retail business acres per town")
axes.set_ylabel("Tax Rate")
plt.show()
Ausgang:
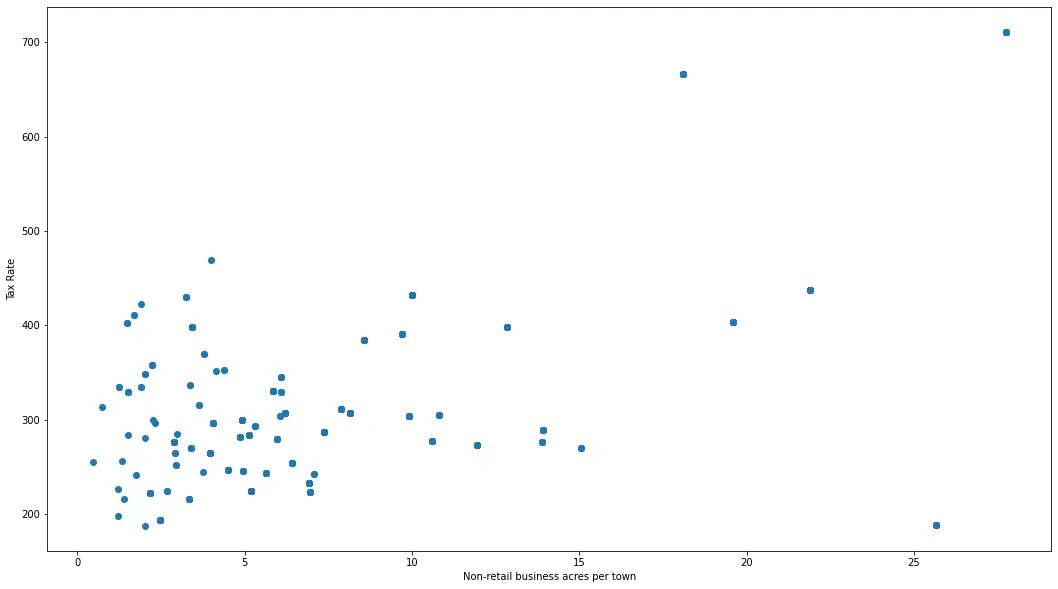
Wenn wir eine Augapfelschätzung erhalten, können wir im Allgemeinen sagen, dass auf der x-Achse Werte größer als 20 wie Ausreißer aussehen und auf der y-Achse Werte größer als 500 wie Ausreißer aussehen. Wir können dies als unseren Standard zum Entfernen von Ausreißern verwenden.
Wir werden dieselbe numpy-Funktion verwenden, die wir zuvor verwendet haben, um Indizes zu erkennen, die diesem Kriterium entsprechen.
print(np.where((df_boston["INDUS"] > 20) & (df_boston["TAX"] > 500)))
Ausgang:

Mathematische Methoden zur Erkennung der Ausreißer in Python
Berechnen Sie den Z-Score, um die Ausreißer in Python zu erkennen
Der Z-Score (auch als Standard-Score bekannt) ist eine Statistik, die misst, wie viele Standardabweichungen ein Datenpunkt vom Mittelwert entfernt ist. Ein größerer Z-Score zeigt, dass der Datenpunkt weiter vom Mittelwert entfernt ist.
Dies ist wichtig, da die meisten Datenpunkte in einem normalverteilten Datensatz nahe dem Mittelwert liegen. Ein Datenpunkt mit einem großen Z-Score ist weiter von den meisten Datenpunkten entfernt und ist wahrscheinlich ein Ausreißer.
Wir können das Dienstprogramm von Scipy verwenden, um den Z-Score zu generieren. Wiederum werden wir eine bestimmte Spalte unseres Datensatzes auswählen, um die Methode anzuwenden.
from scipy import stats
z = stats.zscore(df_boston["DIS"])
z_abs = np.abs(z)
Die erste Zeile im obigen Code importiert nur die Bibliothek. Die zweite Zeile verwendet die scipy.zscore-Methode, um den Z-Score für jeden Datenpunkt im ausgewählten Datensatz zu berechnen.
Die dritte Zeile hat eine numpy-Funktion, um alle Werte in positive Werte umzuwandeln. Dies hilft uns, einen einfachen Filter anzuwenden.
Das Drucken des Arrays zeigt uns etwa Folgendes:
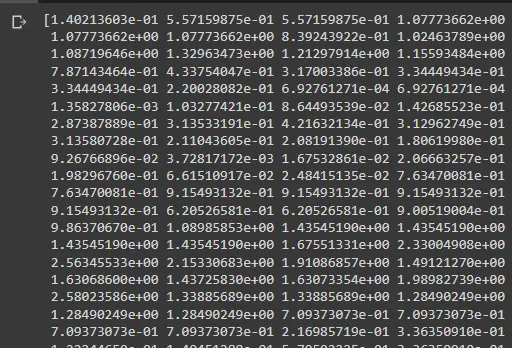
Dieses Bild enthält nicht alle Punkte, aber Sie können es anzeigen, indem Sie z_abs drucken.
Wir müssen nun entscheiden, nach welchen Kriterien Punkte als Ausreißer gelten. Beim Arbeiten mit Normalverteilungen werden Datenpunkte, die drei Standardabweichungen über dem Mittelwert liegen, als Ausreißer betrachtet.
Dies liegt daran, dass 99,7 % der Punkte innerhalb von 3 Standardabweichungen vom Mittelwert in einer Normalverteilung liegen. Das bedeutet, dass alle Punkte mit einem Z-Score größer als 3 entfernt werden sollten.
Auch hier werden wir die Funktion np.where verwenden, um unsere Ausreißer-Indizes zu finden. Erfahren Sie mehr über die Funktion np.where.
print(np.where(z_abs > 3))
Ausgang:

Berechnen Sie den Interquartilbereich, um die Ausreißer in Python zu erkennen
Dies ist die letzte Methode, die wir besprechen werden. Diese Methode wird in der Forschung sehr häufig zum Bereinigen von Daten durch Entfernen von Ausreißern verwendet.
Der Inter-Quartile Range (IQR) ist die Differenz zwischen dem dritten Quartil und dem ersten Quartil der Daten. Wir definieren Q1 als erstes Quartil, was bedeutet, dass 25% der Daten zwischen dem Minimum und Q1 liegen.
Wir definieren Q3 als drittes Quartil der Daten, was bedeutet, dass 75% der Daten zwischen dem Datensatzminimum und Q3 liegen.
Mit diesen Definitionen können wir unsere oberen und unteren Grenzen definieren. Jeder Datenpunkt unterhalb der Untergrenze und oberhalb der Obergrenze wird als Ausreißer betrachtet.
Lower bound = Q1 - (1.5 * IQR)
Upper bound = Q3 + (1.5 * IQR)
Die 1,5 mag willkürlich aussehen, hat aber mathematische Bedeutung. Wenn Sie an der detaillierten Mathematik interessiert sind, schauen Sie sich diesen Artikel an.
Sie müssen wissen, dass dies ungefähr dem Finden von Daten entspricht, die mindestens 3 Standardabweichungen vom Mittelwert entfernt sind (wenn unsere Daten normalverteilt waren). In der Praxis ist diese Methode sehr effektiv.
In Python können wir die NumPy-Funktion percentile() verwenden, um Q1 und Q3 zu finden und dann den IQR zu finden.
Q1 = np.percentile(df_boston["DIS"], 25, interpolation="midpoint")
Q3 = np.percentile(df_boston["DIS"], 75, interpolation="midpoint")
IQR = Q3 - Q1
In unserem Datensatz drucken wir den IQR aus und erhalten Folgendes:

Wir werden nun unsere oberen und unteren Grenzen wie folgt definieren:
upper_bound = df_boston["DIS"] >= (Q3 + 1.5 * IQR)
lower_bound = df_boston["DIS"] <= (Q1 - 1.5 * IQR)
Wiederum können wir die Indizes für die Punkte, die den Kriterien entsprechen, mit np.where erhalten.
print(np.where(upper_bound))
print(np.where(lower_bound))
Ausgang:

Entfernen Sie die Ausreißer aus dem DataFrame in Python
Wir werden die Funktion dataframe.drop verwenden, um die Ausreißerpunkte zu löschen. Klicken Sie hier, um weitere Informationen zur Funktion zu erhalten.
Dazu müssen wir der Funktion eine Liste mit den Indizes der Ausreißer übergeben. Wir können dies wie folgt tun:
upper_points = np.where(upper_bound)
df_boston.drop(upper_points[0], inplace=True)
Um zu überprüfen, ob die Punkte fallen gelassen wurden oder nicht, können wir die Form unserer Daten ausdrucken, um die Anzahl der verbleibenden Einträge zu sehen.
print(df_boston.shape)
df_boston.drop(upper_points[0], inplace=True)
print(df_boston.shape)
Ausgang:
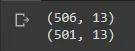
Glückwunsch! Dies bestätigt, dass wir unsere Ausreißer erfolgreich entfernt haben. Sie können eine beliebige Liste von Indizes mit den oben verwendeten Methoden übergeben und an die Drop-Funktion übergeben.

Husnain is a professional Software Engineer and a researcher who loves to learn, build, write, and teach. Having worked various jobs in the IT industry, he especially enjoys finding ways to express complex ideas in simple ways through his content. In his free time, Husnain unwinds by thinking about tech fiction to solve problems around him.
LinkedIn