Detectar y eliminar valores atípicos en Python
- Configurar el entorno y cargar el conjunto de datos
- Visualice el conjunto de datos en Python
- Métodos matemáticos para detectar valores atípicos en Python
- Eliminar los valores atípicos del marco de datos en Python
Dentro de un conjunto de datos, un valor atípico es un elemento que es anormalmente diferente del resto del conjunto de datos. Sin embargo, esta definición da suficiente espacio para que el analista de datos decida el umbral de anormalidad.
Tenemos valores atípicos debido a errores de medición, errores de ejecución, problemas de muestreo, entrada de datos incorrecta o incluso variación natural. La eliminación de valores atípicos es importante porque su presencia puede aumentar los errores, introducir sesgos e impactar significativamente en los modelos estadísticos.
En este tutorial, analizaremos métodos para detectar y eliminar valores atípicos de un conjunto de datos. Demostraremos esto aplicando nuestras técnicas a un conocido conjunto de datos de Boston Housing, parte de la biblioteca scikit-learn.
El artículo está estructurado de tal manera que exploraremos un método para detectar valores atípicos y luego discutiremos cómo se puede usar la técnica para eliminar los valores atípicos.
Si desea seguir el tutorial, puede hacerlo dentro de su navegador usando Google Colab. Es tan simple como abrir un nuevo cuaderno y escribir código.
Aquí hay una guía para comenzar a usar Google Colab paso a paso.
Configurar el entorno y cargar el conjunto de datos
Comenzamos importando algunas bibliotecas que usaremos.
import sklearn
from sklearn.datasets import load_boston
import pandas as pd
import matplotlib.pyplot as plt
Luego podemos cargar el conjunto de datos de Vivienda de Boston.
bh_dataset = load_boston()
El conjunto de datos contiene un atributo feature_names, una matriz que contiene los nombres de todas las características del conjunto de datos. El atributo datos contiene todos los datos.
Separaremos los dos y luego los combinaremos para crear un marco de datos de Pandas.
columns = bh_dataset.feature_names
df_boston = pd.DataFrame(bh_dataset.data)
df_boston.columns = columns
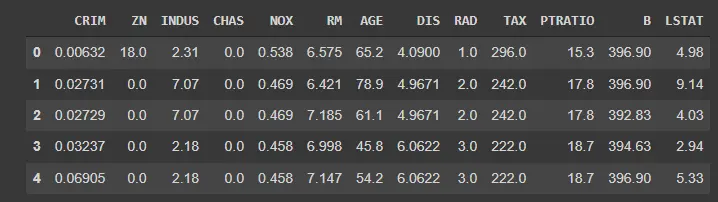
df_boston ahora contiene todo el conjunto de datos. Pandas nos permite una forma clara y sencilla de obtener una vista previa de nuestro conjunto de datos utilizando el método .head().
Llamar a la función como se muestra a continuación mostrará una vista previa del conjunto de datos (también se muestra a continuación).
df_boston.head()
Producción:
Visualice el conjunto de datos en Python
Genere un diagrama de caja para visualizar el conjunto de datos
Un diagrama de caja%20y%20promedios.), también conocido como diagrama de caja y bigotes, es una forma simple y efectiva de visualizar sus datos y es particularmente útil para buscar valores atípicos. En python, podemos usar la biblioteca [seaborn] para generar un diagrama de caja de nuestro conjunto de datos.
import seaborn as sns
sns.boxplot(df_boston["DIS"])
La trama para el código anterior:
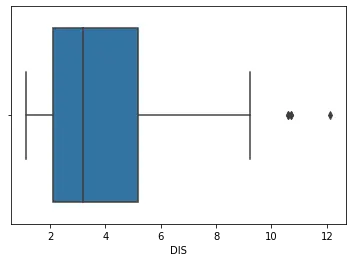
Indexar el conjunto de datos con 'DIS' significa pasar la columna DIS a la función de diagrama de caja. El diagrama de caja se genera en 1 dimensión.
Por lo tanto, solo toma una variable como entrada. La variable se puede cambiar para generar diferentes diagramas de caja.
En el gráfico anterior, podemos ver que los valores por encima de 10 son valores atípicos. Ahora usaremos esto como el estándar para valores atípicos en este conjunto de datos.
Podemos seleccionar entradas en el conjunto de datos que se ajusten a este criterio usando np.where como se muestra en el ejemplo a continuación.
import numpy as np
DIS_subset = df_boston["DIS"]
print(np.where(DIS_subset > 10))
Producción:

Estos son índices de matriz que contienen puntos de datos que son valores atípicos según lo definido por el criterio anterior. Al final del artículo, le mostraremos cómo usar estos índices para eliminar valores atípicos de su conjunto de datos.
Genere un gráfico de dispersión para visualizar el conjunto de datos
Los diagramas de caja se pueden usar cuando tenemos datos en una sola dimensión. Sin embargo, podemos usar un diagrama de dispersión si tenemos datos emparejados o si la relación que estamos analizando involucra dos variables.
Python nos permite generar diagramas de dispersión usando Matplotlib. El siguiente es un ejemplo de código de impresión de un diagrama de dispersión.
fig, axes = plt.subplots(figsize=(18, 10))
axes.scatter(df_boston["INDUS"], df_boston["TAX"])
axes.set_xlabel("Non-retail business acres per town")
axes.set_ylabel("Tax Rate")
plt.show()
Producción:
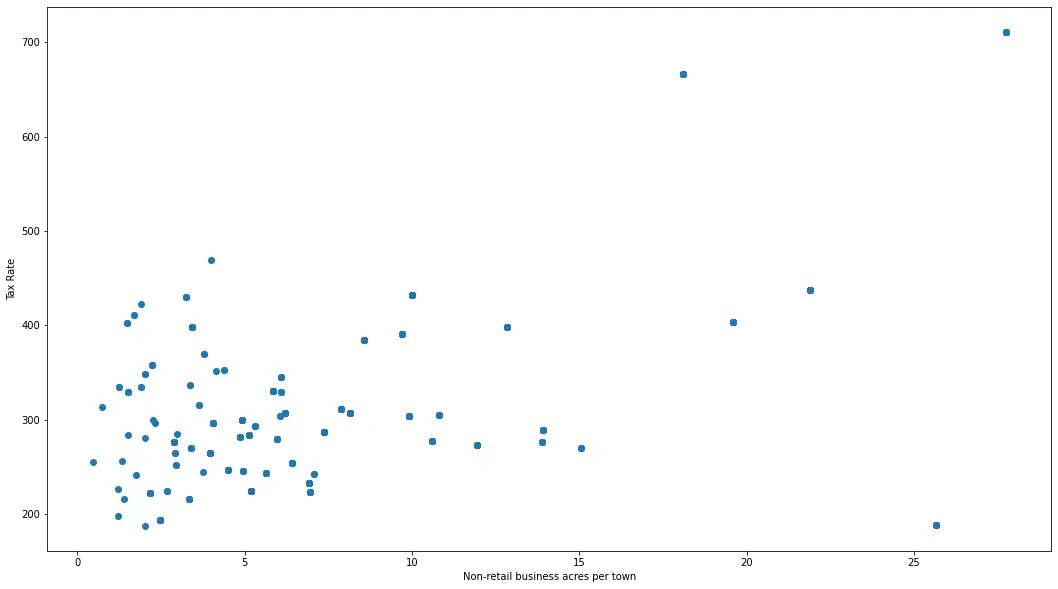
Obteniendo una estimación global, generalmente podemos decir que en el eje x, los valores superiores a 20 parecen valores atípicos, y en el eje y, los valores superiores a 500 parecen valores atípicos. Podemos usar esto como nuestro estándar para eliminar valores atípicos.
Usaremos la misma función numpy que usamos anteriormente para detectar índices que coincidan con este criterio.
print(np.where((df_boston["INDUS"] > 20) & (df_boston["TAX"] > 500)))
Producción:

Métodos matemáticos para detectar valores atípicos en Python
Calcule el Z-Score para detectar los valores atípicos en Python
El Z-Score (también conocido como Standard Score) es una estadística que mide cuántas desviaciones estándar se encuentra un punto de datos con respecto a la media. Una puntuación Z mayor muestra que el punto de datos está más lejos de la media.
Esto es importante porque la mayoría de los puntos de datos están cerca de la media en un conjunto de datos distribuidos normalmente. Un punto de datos con una puntuación Z grande está más lejos de la mayoría de los puntos de datos y es probable que sea un valor atípico.
Podemos usar la utilidad de Scipy para generar el puntaje Z. Una vez más, seleccionaremos una columna específica de nuestro conjunto de datos para aplicar el método.
from scipy import stats
z = stats.zscore(df_boston["DIS"])
z_abs = np.abs(z)
La primera línea en el código anterior es solo importar la biblioteca. La segunda línea usa el método scipy.zscore para calcular el puntaje Z para cada punto de datos en el conjunto de datos seleccionado.
La tercera línea tiene una función numpy para convertir todos los valores a valores positivos. Esto nos ayuda a aplicar un filtro simple.
Imprimir la matriz nos mostrará algo como esto:
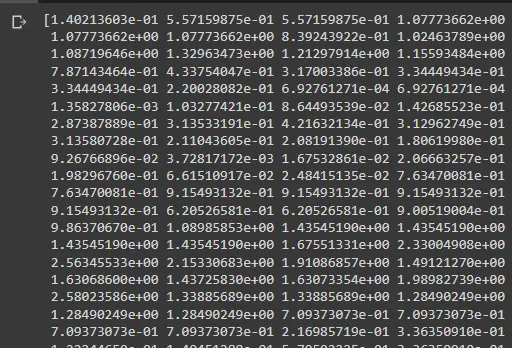
Esta imagen no incluye todos los puntos, pero puede visualizarla imprimiendo z_abs.
Ahora tenemos que decidir los criterios para qué puntos cuentan como valores atípicos. Cuando se trabaja con distribuciones normales, los puntos de datos tres desviaciones estándar por encima de la media se consideran valores atípicos.
Esto se debe a que el 99,7% de los puntos están dentro de las 3 desviaciones estándar de la media en una distribución normal. Esto significa que todos los puntos con una puntuación Z superior a 3 deben eliminarse.
Una vez más, usaremos la función np.where para encontrar nuestros índices atípicos. Más información sobre la función np.where.
print(np.where(z_abs > 3))
Producción:

Calcule el rango intercuartílico para detectar los valores atípicos en Python
Este es el método final que discutiremos. Este método se usa con mucha frecuencia en la investigación para limpiar datos mediante la eliminación de valores atípicos.
El rango intercuartil (IQR) es la diferencia entre el tercer cuartil y el primer cuartil de los datos. Definimos Q1 como el primer cuartil, lo que significa que el 25% de los datos se encuentran entre el mínimo y Q1.
Definimos Q3 como el tercer cuartil de los datos, lo que significa que el 75 % de los datos se encuentra entre el mínimo del conjunto de datos y Q3.
Con estas definiciones, podemos definir nuestros límites superior e inferior. Cualquier punto de datos por debajo del límite inferior y por encima del límite superior se considerará un valor atípico.
Lower bound = Q1 - (1.5 * IQR)
Upper bound = Q3 + (1.5 * IQR)
El 1.5 puede parecer arbitrario, pero tiene un significado matemático. Si está interesado en sus matemáticas detalladas, mire este artículo
Debe saber que esto es más o menos equivalente a encontrar datos al menos a 3 desviaciones estándar de la media (si nuestros datos se distribuyeron normalmente). En la práctica, este método es muy eficaz.
En Python, podemos usar la función NumPy percentile() para encontrar Q1 y Q3 y luego encontrar el IQR.
Q1 = np.percentile(df_boston["DIS"], 25, interpolation="midpoint")
Q3 = np.percentile(df_boston["DIS"], 75, interpolation="midpoint")
IQR = Q3 - Q1
En nuestro conjunto de datos, imprimimos el IQR y obtenemos lo siguiente:

Ahora definiremos nuestros límites superior e inferior de la siguiente manera:
upper_bound = df_boston["DIS"] >= (Q3 + 1.5 * IQR)
lower_bound = df_boston["DIS"] <= (Q1 - 1.5 * IQR)
Una vez más, podemos obtener los índices de los puntos que se ajustan a los criterios utilizando np.where.
print(np.where(upper_bound))
print(np.where(lower_bound))
Producción:

Eliminar los valores atípicos del marco de datos en Python
Usaremos la función dataframe.drop para eliminar los puntos atípicos. Haga clic aquí para más información sobre la función.
Para ello tendremos que pasar una lista con los índices de los outliers a la función. Podemos hacer esto de la siguiente manera:
upper_points = np.where(upper_bound)
df_boston.drop(upper_points[0], inplace=True)
Para verificar si los puntos se han eliminado o no, podemos imprimir la forma de nuestros datos para ver el número de entradas restantes.
print(df_boston.shape)
df_boston.drop(upper_points[0], inplace=True)
print(df_boston.shape)
Producción:
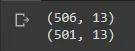
¡Felicidades! Esto confirma que hemos eliminado con éxito nuestros valores atípicos. Puede pasar cualquier lista de índices utilizando los métodos que empleamos anteriormente y pasarlos a la función de soltar.

Husnain is a professional Software Engineer and a researcher who loves to learn, build, write, and teach. Having worked various jobs in the IT industry, he especially enjoys finding ways to express complex ideas in simple ways through his content. In his free time, Husnain unwinds by thinking about tech fiction to solve problems around him.
LinkedIn