Ajuste la distribución de Poisson a diferentes conjuntos de datos en Python
- Ajuste la distribución de Poisson a diferentes conjuntos de datos en Python
- Método de mínimos cuadrados agrupados para ajustar la distribución de Poisson en Python
- Use un binomial negativo para ajustar la distribución de Poisson en un conjunto de datos demasiado disperso
- Distribución de Poisson para datos altamente dispersos mediante binomial negativa
- Conclusión
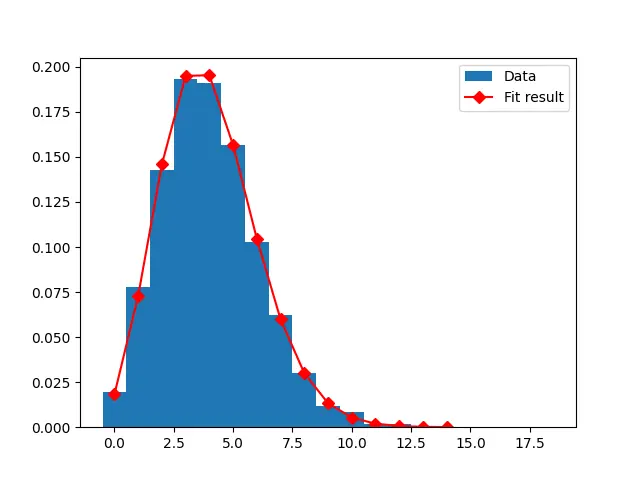
La distribución de probabilidad de Poisson muestra la posibilidad de que ocurra un evento en un período o espacio fijo. Estos datos se pueden trazar como un histograma usando Python para observar la tasa de ocurrencia del evento.
Las distribuciones son curvas que se pueden trazar en los histogramas u otras estructuras para encontrar la mejor curva de ajuste para el conjunto de datos. Este artículo le enseñará cómo ajustar la distribución de Poisson en un conjunto de datos usando Python.
Ajuste la distribución de Poisson a diferentes conjuntos de datos en Python
Comprendamos cómo trazar múltiples distribuciones en un conjunto de datos y ajustar la distribución de Poisson usando SciPy y Python.
Método de mínimos cuadrados agrupados para ajustar la distribución de Poisson en Python
En este ejemplo, se crea un conjunto de datos de Poisson ficticio y se traza un histograma con estos datos. Después de trazar el histograma, el método de mínimos cuadrados agrupados ajusta una curva sobre el histograma para ajustarse a la distribución de Poisson.
Funciones de importación para el programa
Este programa utiliza las siguientes funciones de importación.
- Brazo matemático de Matplotlib -
Numpy. - La sub-biblioteca de Matplotlib
Pyplotpara trazar gráficos. - SciPy
curve_fitpara importar el ajuste de la curva. poissonpara el conjunto de datos.
Cree un conjunto de datos ficticio para la distribución de Poisson y trace el histograma con el conjunto de datos
Se crea una variable dataset_size con números desviados de Poisson dentro del rango de 4 a 20 000 usando la función np.random.poisson(). Devuelve una matriz con valores de Poisson aleatorios.
data_set = np.random.poisson(4, 2000)
Las diferencias en los datos del histograma se almacenan dentro de una nueva variable, bins. Utiliza la función np.arrange() para devolver una matriz con valores entre el rango de -0.5 a 20 con 0.5 como diferencia media.
bins = np.arange(20) - 0.5
Se traza un histograma usando la función plt.hist(), donde los parámetros son:
data_setpara los datos utilizados.cubospara las diferencias.densidad, que se establece como verdadera.label, que añade una etiqueta a la trama.
Mientras se traza el histograma, se devuelven tres valores de la función plt.hist(), que se almacena en tres nuevas variables: entradas para valores de contenedores de histograma, bin_edges para bordes de contenedores y parches para parches individuales para el histograma.
entries, bin_edges, patches = plt.hist(data_set, bins=bins, density=True, label="Data")
Ajustar la curva al histograma usando Ajuste de curva
Una vez que se traza el histograma, se usa la función de ajuste de curva para ajustar la distribución de Poisson a los datos. La función de curva traza la línea de mejor ajuste de un conjunto de datos dispersos.
El ajuste de la curva requiere una función de ajuste que convierta una matriz de valores en una distribución de Poisson y los devuelva como parámetros en los que se trazará la curva. Se crea un método fit_function con dos parámetros, k y parameters.
La biblioteca SciPy poisson.pmf se utiliza para obtener los parámetros. El pmf significa función de masa de probabilidad, y esta función devuelve la frecuencia de una distribución aleatoria.
La variable k almacena el número de veces que ha ocurrido el evento, y la variable lamb es el popt (suma de cuadrados reducidos) que se utiliza como parámetro de ajuste para la función de curva.
La función SciPy curve_fit toma tres parámetros, fit_function, middle_bins y entries y devuelve dos valores: parameters (valores óptimos que reducen la suma de los residuos cuadrados) y cov_matrix (parámetros covarianza estimada).
parameters, cov_matrix = curve_fit(fit_function, middles_bins, entries)
Se crea un conjunto de datos de 15 valores ascendentes para trazar la curva, y la distribución de Poisson de estos valores ascendentes se ajusta utilizando el método fit_function. Se proporcionan los atributos del gráfico y se muestra el resultado.
x_plot = np.arange(0, 15)
plt.plot(
x_plot,
fit_function(x_plot, *parameters),
marker="D",
linestyle="-",
color="red",
label="Fit result",
)
Código completo:
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
from scipy.stats import poisson
# get random numbers that are poisson deviated
data_set = np.random.poisson(4, 2000)
# the bins have to be kept as a positive integer because poisson is a positive integer distribution
bins = np.arange(20) - 0.5
entries, bin_edges, patches = plt.hist(data_set, bins=bins, density=True, label="Data")
# calculate bin centers
middles_bins = (bin_edges[1:] + bin_edges[:-1]) * 0.5
def fit_function(k, lamb):
# The parameter lamb will be used as the fit parameter
return poisson.pmf(k, lamb)
# fit with curve_fit
parameters, cov_matrix = curve_fit(fit_function, middles_bins, entries)
# plot poisson-deviation with fitted parameter
x_plot = np.arange(0, 15)
plt.plot(
x_plot,
fit_function(x_plot, *parameters),
marker="D",
linestyle="-",
color="red",
label="Fit result",
)
plt.legend()
plt.show()
Producción:
Use un binomial negativo para ajustar la distribución de Poisson en un conjunto de datos demasiado disperso
En este ejemplo, se crea un marco de datos de distribución de Poisson con datos muy dispersos y aprenderemos cómo ajustar la distribución de Poisson a estos datos.
A diferencia del último ejemplo, donde la distribución de Poisson se centró en torno a su media, estos datos están muy dispersos, por lo que en la siguiente sección se agregará un binomial negativo a estos datos para mejorar la distribución de Poisson.
Crear el conjunto de datos
En este ejemplo, se crea un marco de datos de Pandas y se almacena dentro de la variable conjunto de datos. Este conjunto de datos tiene una columna, “Ocurrencia” con valores de Poisson 2000 y el valor de lambda establecido en 200.
dataset = pd.DataFrame({"Occurrence": np.random.poisson(200, 2000)})
Trazar histograma con el conjunto de datos
Para trazar el histograma, debemos proporcionar tres valores, intervalos de los contenedores (cubo de valores), el inicio de los contenedores y el final de los contenedores. Esto se hace por:
width_of_bin = 15
xstart = 150
xend = 280
bins = np.arange(xstart, xend, width_of_bin)
Una vez que se establece el valor de los intervalos, trace el histograma.
hist = sns.histplot(data=dataset["Occurrence"], kde=True, bins=bins)
Ajuste la curva de distribución de Poisson al histograma
Se requiere la media y el tamaño del conjunto de datos para ajustarse a la distribución de Poisson mediante el trazado de la curva de distribución. En dos nuevas variables, mu y n, se almacenan la media y el tamaño del conjunto de datos, respectivamente.
El algoritmo para trazar la curva de distribución de Poisson es:
bins + width_of_bin / 2, n * (
poisson.cdf(bins + width_of_bin, mu) - poisson.cdf(bins, mu)
)
Por último, la curva se traza en el histograma.
Código completo:
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import poisson
dataset = pd.DataFrame({"Occurrence": np.random.poisson(200, 2000)})
width_of_bin = 15
xstart = 150
xend = 280
bins = np.arange(xstart, xend, width_of_bin)
hist = sns.histplot(data=dataset["Occurrence"], kde=True, bins=bins)
mu = dataset["Occurrence"].mean()
n = len(dataset)
plt.plot(
bins + width_of_bin / 2,
n * (poisson.cdf(bins + width_of_bin, mu) - poisson.cdf(bins, mu)),
color="red",
)
plt.show()
Producción:
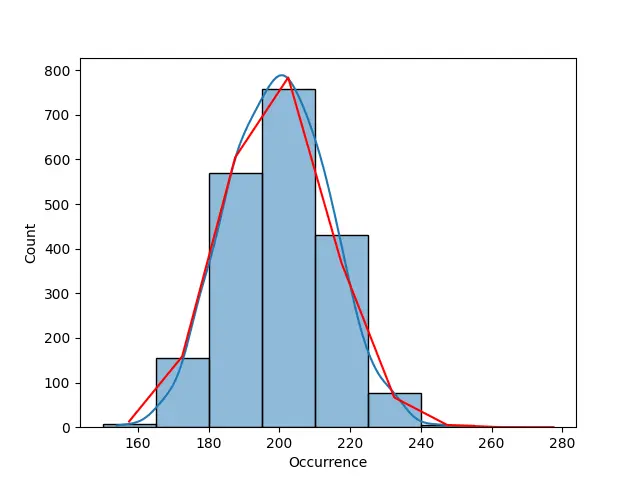
Distribución de Poisson para datos altamente dispersos mediante binomial negativa
Como se indicó anteriormente, los datos dentro de este conjunto de datos están demasiado dispersos, por lo que la curva no se parece perfectamente a una curva de distribución de Poisson. En el siguiente ejemplo se usa un binomio negativo para ajustar la distribución de Poisson.
El conjunto de datos se crea inyectando un binomio negativo:
dataset = pd.DataFrame({"Occurrence": nbinom.rvs(n=1, p=0.004, size=2000)})
El bin para el histograma comienza en 0 y termina en 2000 con un intervalo común de 100.
binwidth = 100
xstart = 0
xend = 2000
bins = np.arange(xstart, xend, binwidth)
Después de crear los contenedores y el conjunto de datos, se traza el histograma:
hist = sns.histplot(data=dataset["Occurrence"], kde=True, bins=bins)
La curva requiere cinco parámetros, varianza(Var), media(mu), p(media/varianza), r(elementos tomados para consideración) y n(elementos totales en el conjunto de datos)
La varianza y la media se calculan en dos variables, varianza y mu.
Var = dataset["Occurrence"].var()
mu = dataset["Occurrence"].mean()
Las siguientes fórmulas se utilizan para encontrar la p y la r:
p = mu / Var
r = mu ** 2 / (Var - mu)
El número total de elementos se almacena guardando la longitud del conjunto de datos en una nueva variable n.
n = len(dataset)
Por último, la curva se traza en el histograma.
plt.plot(
bins + binwidth / 2,
n * (nbinom.cdf(bins + binwidth, r, p) - nbinom.cdf(bins, r, p)),
)
Código completo:
import numpy as np
from scipy.stats import nbinom
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
dataset = pd.DataFrame({"Occurrence": nbinom.rvs(n=1, p=0.004, size=2000)})
binwidth = 100
xstart = 0
xend = 2000
bins = np.arange(xstart, xend, binwidth)
hist = sns.histplot(data=dataset["Occurrence"], kde=True, bins=bins)
Var = dataset["Occurrence"].var()
mu = dataset["Occurrence"].mean()
p = mu / Var
r = mu ** 2 / (Var - mu)
n = len(dataset)
plt.plot(
bins + binwidth / 2,
n * (nbinom.cdf(bins + binwidth, r, p) - nbinom.cdf(bins, r, p)),
color="red",
)
plt.show()
Producción:
Conclusión
Este artículo explica tres formas de ajustar una distribución de Poisson a un conjunto de datos en Python. Después de leer el artículo, el lector puede ajustar la distribución de Poisson sobre conjuntos de datos ficticios de Poisson y conjuntos de datos demasiado dispersos.