Python での異なるデータセットへのポアソン分布のあてはめ
- Python での異なるデータセットへのポアソン分布のあてはめ
- Python でポアソン分布に適合する Binned Least Squares メソッド
- 負の二項式を使用して、過度に分散したデータセットでポアソン分布に適合させる
- 負の二項式を使用した高分散データのポアソン分布
- まとめ
ポアソン確率分布は、特定の期間または空間でイベントが発生する可能性を示します。 このデータは、Python を使用してヒストグラムとしてプロットし、イベントの発生率を観察できます。
分布は、データセットに最適な曲線を見つけるために、ヒストグラムまたはその他の構造にプロットできる曲線です。 この記事では、Python を使用してデータ セットにポアソン分布を適合させる方法を説明します。
Python での異なるデータセットへのポアソン分布のあてはめ
SciPy と Python を使用して、一連のデータに複数の分布をプロットし、ポアソン分布に適合させる方法を理解しましょう。
Python でポアソン分布に適合する Binned Least Squares メソッド
この例では、ダミーのポアソン データセットが作成され、このデータを使用してヒストグラムがプロットされます。 ヒストグラムがプロットされた後、ビニングされた最小二乗法は、ポアソン分布に適合するようにヒストグラムに曲線を当てはめます。
プログラムのインポート関数
このプログラムは、次のインポート関数を使用します。
- Matplotlib の数学部門 -
Numpy。 - グラフをプロットするための Matplotlib サブライブラリ
Pyplot。 - カーブ フィットをインポートするための SciPy
curve_fit。 - データセットの
ポアソン。
ポアソン分布のダミー データセットを作成し、データセットを使用してヒストグラムをプロットする
変数 dataset_size は、関数 np.random.poisson() を使用して、4 ~ 20,000 の範囲内のポアソン偏差数で作成されます。 ランダムなポアソン値を持つ配列を返します。
data_set = np.random.poisson(4, 2000)
ヒストグラム データの違いは、新しい変数 bins 内に保存されます。 np.arrange() 関数を使用して、-0.5 から 20 の範囲の値を持つ配列を返し、0.5 を平均差として返します。
bins = np.arange(20) - 0.5
ヒストグラムは plt.hist() 関数を使用してプロットされます。パラメータは次のとおりです。
- 使用されるデータの
data_set。 - 違いのための
bins。 - true に設定されている
density。 - プロットにラベルを追加する
label。
ヒストグラムがプロットされる間、plt.hist() 関数から 3つの値が返されます。この値は、3つの新しい変数 (ヒストグラム ビンの値の entries、ビンのエッジの bin_edges、および patches) に格納されます。 ヒストグラムの個々のパッチ用。
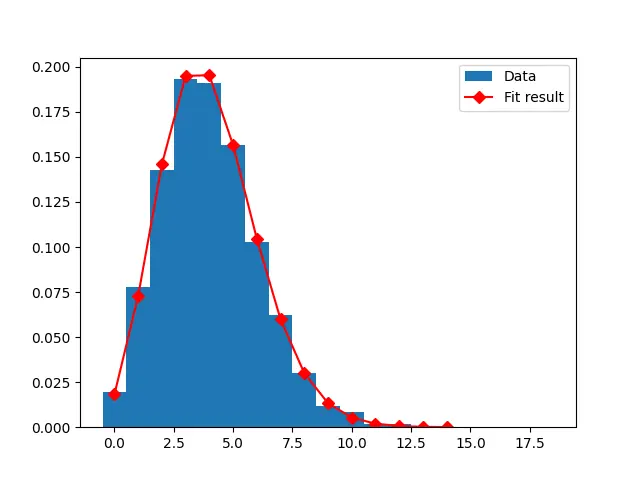
entries, bin_edges, patches = plt.hist(data_set, bins=bins, density=True, label="Data")
カーブ フィットを使用してカーブをヒストグラムにフィットさせる
ヒストグラムがプロットされたら、カーブ フィット関数を使用してポアソン分布をデータに適合させます。 曲線関数は、散布データ セットから最適な線をプロットします。
カーブ フィットには、値の配列をポアソン分布に変換し、曲線がプロットされるパラメーターとして返すフィット関数が必要です。 メソッド fit_function は、k と parameters の 2つのパラメーターで作成されます。
SciPy ライブラリ poisson.pmf を使用してパラメーターを取得します。 pmf は確率質量関数の略で、この関数はランダム分布の度数を返します。
変数 k はイベントが発生した回数を格納し、変数 lamb は popt (縮小二乗和) で、曲線関数の適合パラメーターとして使用されます。
SciPyのcurve_fit関数は、fit_function、middle_bins、およびentriesという3つのパラメータを受け取り、2つの値、すなわちparameters(残差の二乗和を最小化する最適な値)とcov_matrix(parametersの推定共分散)を返します。
parameters, cov_matrix = curve_fit(fit_function, middles_bins, entries)
曲線をプロットするために 15 個の昇順の値のデータセットが作成され、fit_function メソッドを使用してこれらの昇順の値のポアソン分布が適合されます。 プロットの属性が提供され、結果が表示されます。
x_plot = np.arange(0, 15)
plt.plot(
x_plot,
fit_function(x_plot, *parameters),
marker="D",
linestyle="-",
color="red",
label="Fit result",
)
完全なコード:
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
from scipy.stats import poisson
# get random numbers that are poisson deviated
data_set = np.random.poisson(4, 2000)
# the bins have to be kept as a positive integer because poisson is a positive integer distribution
bins = np.arange(20) - 0.5
entries, bin_edges, patches = plt.hist(data_set, bins=bins, density=True, label="Data")
# calculate bin centers
middles_bins = (bin_edges[1:] + bin_edges[:-1]) * 0.5
def fit_function(k, lamb):
# The parameter lamb will be used as the fit parameter
return poisson.pmf(k, lamb)
# fit with curve_fit
parameters, cov_matrix = curve_fit(fit_function, middles_bins, entries)
# plot poisson-deviation with fitted parameter
x_plot = np.arange(0, 15)
plt.plot(
x_plot,
fit_function(x_plot, *parameters),
marker="D",
linestyle="-",
color="red",
label="Fit result",
)
plt.legend()
plt.show()
出力:
負の二項式を使用して、過度に分散したデータセットでポアソン分布に適合させる
この例では、ポアソン分布データ フレームが高度に分散したデータで作成され、ポアソン分布をこのデータに適合させる方法を学習します。
ポアソン分布が平均を中心としていた最後の例とは異なり、このデータは高度に分散しているため、次のセクションでこのデータに負の二項式を追加して、ポアソン分布を改善します。
データセットを作成する
この例では、Pandas データ フレームが作成され、変数 dataset 内に格納されます。 このデータセットには、2000 ポアソン値と 200 に設定されたラムダ値を持つ Occurrence という 1つの列があります。
dataset = pd.DataFrame({"Occurrence": np.random.poisson(200, 2000)})
データセットを使用してヒストグラムをプロットする
ヒストグラムをプロットするには、ビンの間隔 (値のバケット)、ビンの開始点、ビンの終了点の 3つの値を指定する必要があります。 これは次の方法で行われます。
width_of_bin = 15
xstart = 150
xend = 280
bins = np.arange(xstart, xend, width_of_bin)
bins の値が設定されたら、ヒストグラムをプロットします。
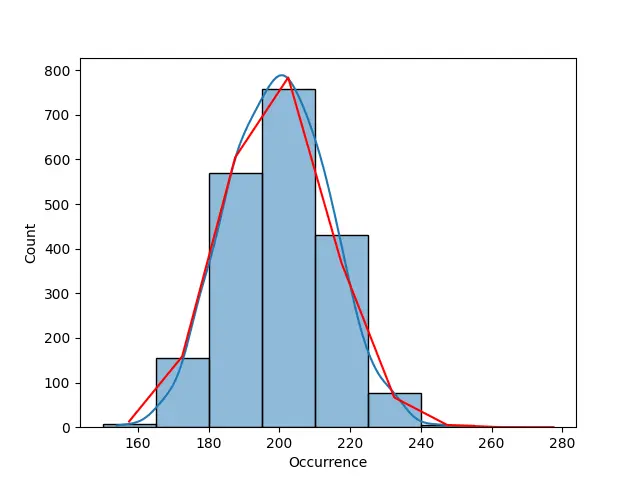
hist = sns.histplot(data=dataset["Occurrence"], kde=True, bins=bins)
ヒストグラムにポアソン分布曲線を当てはめる
分布曲線をプロットしてポアソン分布に適合させるには、データセットの平均とサイズが必要です。 2つの新しい変数 mu と n には、データセットの平均とサイズがそれぞれ格納されます。
ポアソン分布曲線をプロットするアルゴリズムは次のとおりです。
bins + width_of_bin / 2, n * (
poisson.cdf(bins + width_of_bin, mu) - poisson.cdf(bins, mu)
)
最後に、曲線がヒストグラムにプロットされます。
完全なコード:
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import poisson
dataset = pd.DataFrame({"Occurrence": np.random.poisson(200, 2000)})
width_of_bin = 15
xstart = 150
xend = 280
bins = np.arange(xstart, xend, width_of_bin)
hist = sns.histplot(data=dataset["Occurrence"], kde=True, bins=bins)
mu = dataset["Occurrence"].mean()
n = len(dataset)
plt.plot(
bins + width_of_bin / 2,
n * (poisson.cdf(bins + width_of_bin, mu) - poisson.cdf(bins, mu)),
color="red",
)
plt.show()
出力:
負の二項式を使用した高分散データのポアソン分布
前述のように、このデータセット内のデータは過度に分散しているため、曲線がポアソン分布曲線に完全には似ていません。 以下の例では、ポアソン分布に適合するために負の二項式が使用されています。
データセットは、負の二項式を挿入することによって作成されます。
dataset = pd.DataFrame({"Occurrence": nbinom.rvs(n=1, p=0.004, size=2000)})
ヒストグラムのビンは、0 で始まり、100 の一般的な間隔で 2000 で終わります。
binwidth = 100
xstart = 0
xend = 2000
bins = np.arange(xstart, xend, binwidth)
ビンとデータセットが作成されると、ヒストグラムがプロットされます。
hist = sns.histplot(data=dataset["Occurrence"], kde=True, bins=bins)
曲線には、variance(Var)、mean(mu)、p(平均/分散)、r(考慮対象のアイテム)、n(データセット内の合計アイテム) の 5つのパラメーターが必要です。
分散と平均は、variance と mu の 2つの変数で計算されます。
Var = dataset["Occurrence"].var()
mu = dataset["Occurrence"].mean()
次の式は、p と r を見つけるために使用されます。
p = mu / Var
r = mu ** 2 / (Var - mu)
項目の総数は、データセットの長さを新しい変数 n に保存することで保存されます。
n = len(dataset)
最後に、曲線がヒストグラムにプロットされます。
plt.plot(
bins + binwidth / 2,
n * (nbinom.cdf(bins + binwidth, r, p) - nbinom.cdf(bins, r, p)),
)
完全なコード:
import numpy as np
from scipy.stats import nbinom
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
dataset = pd.DataFrame({"Occurrence": nbinom.rvs(n=1, p=0.004, size=2000)})
binwidth = 100
xstart = 0
xend = 2000
bins = np.arange(xstart, xend, binwidth)
hist = sns.histplot(data=dataset["Occurrence"], kde=True, bins=bins)
Var = dataset["Occurrence"].var()
mu = dataset["Occurrence"].mean()
p = mu / Var
r = mu ** 2 / (Var - mu)
n = len(dataset)
plt.plot(
bins + binwidth / 2,
n * (nbinom.cdf(bins + binwidth, r, p) - nbinom.cdf(bins, r, p)),
color="red",
)
plt.show()
出力:
まとめ
この記事では、Python でポアソン分布をデータセットに適合させる 3つの方法について説明します。 この記事を読んだ後、読者はダミーのポアソン データセットと過度に分散したデータセットにポアソン分布を当てはめることができます。