Implémenter la descente de gradient à l'aide de NumPy et Python
L’apprentissage automatique est une tendance de nos jours. Chaque entreprise ou startup essaie de trouver des solutions qui utilisent l’apprentissage automatique pour résoudre des problèmes du monde réel. Pour résoudre ces problèmes, les programmeurs créent des modèles d’apprentissage automatique formés sur des données essentielles et précieuses. Lors de la formation de modèles, il existe de nombreuses tactiques, algorithmes et méthodes parmi lesquels choisir. Certains pourraient fonctionner, d’autres non.
Généralement, Python est utilisé pour entraîner ces modèles. Python prend en charge de nombreuses bibliothèques qui facilitent la mise en œuvre de concepts d’apprentissage automatique. Un de ces concepts est la descente de gradient. Dans cet article, nous allons apprendre à implémenter la descente de gradient à l’aide de Python.
Descente graduelle
Gradient Descent est un algorithme d’optimisation basé sur des fonctions convexes qui est utilisé lors de la formation du modèle d’apprentissage automatique. Cet algorithme nous aide à trouver les meilleurs paramètres de modèle pour résoudre le problème plus efficacement. Tout en entraînant un modèle d’apprentissage automatique sur certaines données, cet algorithme modifie les paramètres du modèle pour chaque itération, ce qui donne finalement un minimum global, parfois même un minimum local, pour la fonction dérivable.
Lors de l’ajustement des paramètres du modèle, une valeur connue sous le nom de taux d’apprentissage décide du montant par lequel les valeurs doivent être ajustées. Si cette valeur est trop grande, l’apprentissage sera rapide et nous pourrions finir par sous-adapter le modèle. Et, si cette valeur est trop petite, l’apprentissage sera lent et nous pourrions finir par suradapter le modèle aux données d’apprentissage. Par conséquent, nous devons trouver une valeur qui maintient un équilibre et donne finalement un bon modèle d’apprentissage automatique avec une bonne précision.
Implémentation de la descente de gradient à l’aide de Python
Maintenant que nous en avons terminé avec la brève théorie de la descente de gradient, comprenons comment nous pouvons l’implémenter à l’aide du module NumPy et du langage de programmation Python à l’aide d’un exemple.
Nous allons entraîner un modèle d’apprentissage automatique pour l’équation y = 0.5x + 2, qui est de la forme y = mx + c ou y = ax + b. Essentiellement, entraînera un modèle d’apprentissage automatique sur les données générées à l’aide de cette équation. Le modèle devinera les valeurs de m et c ou a et b, c’est-à-dire la pente et l’interception, respectivement. Étant donné que les modèles d’apprentissage automatique ont besoin de données pour apprendre et de données de test pour tester leur précision, nous allons générer les mêmes à l’aide d’un script Python. Nous allons effectuer une régression linéaire pour effectuer cette tâche.
Les intrants de formation et les intrants de test seront sous la forme suivante ; un tableau NumPy à deux dimensions. Dans cet exemple, l’entrée est une valeur entière unique et la sortie est une valeur entière unique. Étant donné qu’une seule entrée peut être un tableau de valeurs entières et flottantes, le format suivant sera utilisé pour favoriser la réutilisation du code ou la nature dynamique.
[[1], [2], [3], [4], [5], [6], [7], ...]
Et les étiquettes de formation et les étiquettes de test seront sous la forme suivante ; un tableau NumPy à une dimension.
[1, 4, 9, 16, 25, 36, 49, ...]
Code Python
Voici la mise en œuvre de l’exemple ci-dessus.
import random
import numpy as np
import matplotlib.pyplot as plt
def linear_regression(inputs, targets, epochs, learning_rate):
"""
A utility function to run linear regression and get weights and bias
"""
costs = [] # A list to store losses at each epoch
values_count = inputs.shape[1] # Number of values within a single input
size = inputs.shape[0] # Total number of inputs
weights = np.zeros((values_count, 1)) # Weights
bias = 0 # Bias
for epoch in range(epochs):
# Calculating the predicted values
predicted = np.dot(inputs, weights) + bias
loss = predicted - targets # Calculating the individual loss for all the inputs
d_weights = np.dot(inputs.T, loss) / (2 * size) # Calculating gradient
d_bias = np.sum(loss) / (2 * size) # Calculating gradient
weights = weights - (learning_rate * d_weights) # Updating the weights
bias = bias - (learning_rate * d_bias) # Updating the bias
cost = np.sqrt(
np.sum(loss ** 2) / (2 * size)
) # Root Mean Squared Error Loss or RMSE Loss
costs.append(cost) # Storing the cost
print(
f"Iteration: {epoch + 1} | Cost/Loss: {cost} | Weight: {weights} | Bias: {bias}"
)
return weights, bias, costs
def plot_test(inputs, targets, weights, bias):
"""
A utility function to test the weights
"""
predicted = np.dot(inputs, weights) + bias
predicted = predicted.astype(int)
plt.plot(
predicted,
[i for i in range(len(predicted))],
color=np.random.random(3),
label="Predictions",
linestyle="None",
marker="x",
)
plt.plot(
targets,
[i for i in range(len(targets))],
color=np.random.random(3),
label="Targets",
linestyle="None",
marker="o",
)
plt.xlabel("Indexes")
plt.ylabel("Values")
plt.title("Predictions VS Targets")
plt.legend()
plt.show()
def rmse(inputs, targets, weights, bias):
"""
A utility function to calculate RMSE or Root Mean Squared Error
"""
predicted = np.dot(inputs, weights) + bias
mse = np.sum((predicted - targets) ** 2) / (2 * inputs.shape[0])
return np.sqrt(mse)
def generate_data(m, n, a, b):
"""
A function to generate training data, training labels, testing data, and testing inputs
"""
x, y, tx, ty = [], [], [], []
for i in range(1, m + 1):
x.append([float(i)])
y.append([float(i) * a + b])
for i in range(n):
tx.append([float(random.randint(1000, 100000))])
ty.append([tx[-1][0] * a + b])
return np.array(x), np.array(y), np.array(tx), np.array(ty)
learning_rate = 0.0001 # Learning rate
epochs = 200000 # Number of epochs
a = 0.5 # y = ax + b
b = 2.0 # y = ax + b
inputs, targets, train_inputs, train_targets = generate_data(300, 50, a, b)
weights, bias, costs = linear_regression(
inputs, targets, epochs, learning_rate
) # Linear Regression
indexes = [i for i in range(1, epochs + 1)]
plot_test(train_inputs, train_targets, weights, bias) # Testing
print(f"Weights: {[x[0] for x in weights]}")
print(f"Bias: {bias}")
print(
f"RMSE on training data: {rmse(inputs, targets, weights, bias)}"
) # RMSE on training data
print(
f"RMSE on testing data: {rmse(train_inputs, train_targets, weights, bias)}"
) # RMSE on testing data
plt.plot(indexes, costs)
plt.xlabel("Epochs")
plt.ylabel("Overall Cost/Loss")
plt.title(f"Calculated loss over {epochs} epochs")
plt.show()
une brève explication du code Python
Le code a les méthodes suivantes implémentées.
linear_regression(inputs, targets, epochs, learning_rate): cette fonction effectue la régression linéaire sur les données et renvoie les poids du modèle, le biais du modèle et les coûts ou pertes intermédiaires pour chaque époqueplot_test(inputs, targets, weights, bias): cette fonction accepte les entrées, les cibles, les poids et les biais et prédit la sortie pour les entrées. Ensuite, il tracera un graphique pour montrer à quel point les prédictions du modèle étaient proches des valeurs réelles.rmse(inputs, targets, weights, bias): cette fonction calcule et renvoie l’erreur quadratique moyenne pour certaines entrées, poids, biais et cibles ou étiquettes.generate_data(m, n, a, b): cette fonction génère des exemples de données pour le modèle d’apprentissage automatique à entraîner à l’aide de l’équationy = ax + b. Il génère les données d’entraînement et de test.metnfont référence au nombre d’échantillons d’apprentissage et de test générés, respectivement.
Voici le flux d’exécution du code ci-dessus.
-
La méthode
generate_data()est appelée pour générer quelques échantillons d’entrées d’apprentissage, d’étiquettes d’apprentissage, d’entrées de test et d’étiquettes de test. -
Certaines constantes, telles que le taux d’apprentissage et le nombre d’époques, sont initialisées.
-
La méthode
linear_regression()est appelée pour effectuer une régression linéaire sur les données d’apprentissage générées, et les poids, les biais et les coûts trouvés à chaque époque sont stockés. -
Les poids et le biais du modèle sont testés à l’aide des données de test générées, et un graphique est dessiné pour montrer à quel point les prédictions sont proches des valeurs réelles.
-
La perte RMSE pour les données de formation et de test est calculée et imprimée.
-
Les coûts trouvés pour chaque époque sont tracés en utilisant le module
Matplotlib(une bibliothèque de traçage de graphiques pour Python).
Sortir
Le code Python affichera l’état d’entraînement du modèle sur la console pour chaque époque ou itération. Ce sera comme suit.
...
Iteration: 199987 | Cost/Loss: 0.05856315870190882 | Weight: [[0.5008289]] | Bias: 1.8339454694938624
Iteration: 199988 | Cost/Loss: 0.05856243033468181 | Weight: [[0.50082889]] | Bias: 1.8339475347628937
Iteration: 199989 | Cost/Loss: 0.05856170197651294 | Weight: [[0.50082888]] | Bias: 1.8339496000062387
Iteration: 199990 | Cost/Loss: 0.058560973627402625 | Weight: [[0.50082887]] | Bias: 1.8339516652238976
Iteration: 199991 | Cost/Loss: 0.05856024528735169 | Weight: [[0.50082886]] | Bias: 1.8339537304158708
Iteration: 199992 | Cost/Loss: 0.05855951695635694 | Weight: [[0.50082885]] | Bias: 1.8339557955821586
Iteration: 199993 | Cost/Loss: 0.05855878863442534 | Weight: [[0.50082884]] | Bias: 1.8339578607227613
Iteration: 199994 | Cost/Loss: 0.05855806032154768 | Weight: [[0.50082883]] | Bias: 1.8339599258376793
...
Une fois le modèle formé, le programme testera le modèle et tracera un tracé avec les prédictions du modèle et les vraies valeurs. Le tracé formé sera similaire à celui illustré ci-dessous. Notez que puisque les données de test sont générées à l’aide du module aléatoire, des valeurs aléatoires seront générées à la volée, et par conséquent, le graphique ci-dessous sera très probablement différent du vôtre.
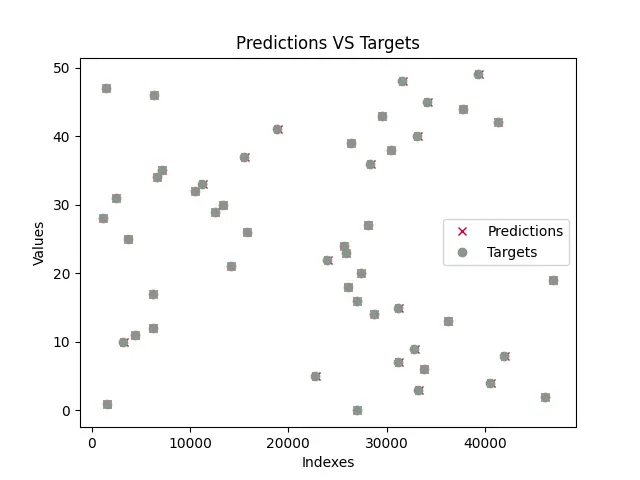
Comme nous pouvons le voir, les prédictions chevauchent presque toutes les vraies valeurs (les prédictions sont représentées par x et les cibles sont représentées par o). Cela signifie que le modèle a presque réussi à prédire les valeurs de a et b ou m et c.
Ensuite, le programme imprime toutes les pertes trouvées lors de la formation du modèle.
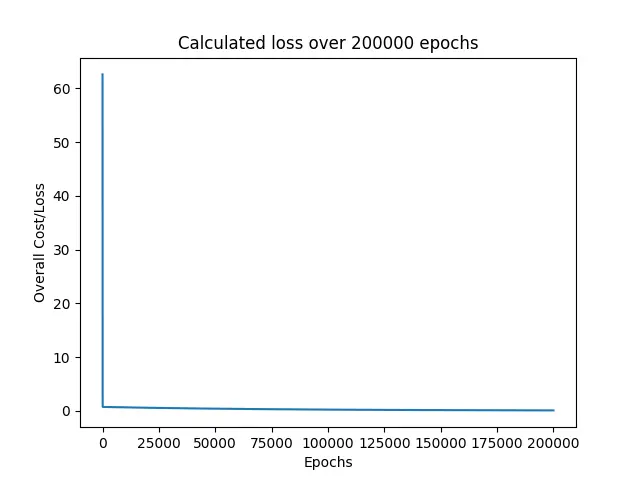
Comme nous pouvons le voir, la perte est immédiatement tombée d’environ 60 près de 0 et a continué à y rester pour le reste des époques.
Enfin, les pertes RMSE pour les données d’entraînement et de test ont été imprimées, ainsi que les valeurs prédites pour a et b ou les paramètres du modèle.
Weights: [0.5008287639956263]
Bias: 1.8339723159878247
RMSE on training data: 0.05855296238504223
RMSE on testing data: 30.609530314187527
L’équation que nous avons utilisée pour cet exemple était y = 0.5x + 2, où a = 0.5 et b = 2. Et, le modèle a prédit a = 0.50082 et b = 1.83397, qui sont très proches des vraies valeurs. C’est pourquoi nos prédictions se chevauchaient avec les véritables cibles.
Pour cet exemple, nous définissons le nombre d’époques sur 200000 et le taux d’apprentissage sur 0.0001. Heureusement, ce n’est qu’un ensemble de configurations qui nous ont donné des résultats extrêmement bons, presque parfaits. Je recommanderais vivement aux lecteurs de cet article de jouer avec ces valeurs et de voir s’ils peuvent proposer des ensembles de valeurs qui donnent des résultats encore meilleurs.

Vaibhav is an artificial intelligence and cloud computing stan. He likes to build end-to-end full-stack web and mobile applications. Besides computer science and technology, he loves playing cricket and badminton, going on bike rides, and doodling.