Pandas DataFrame DataFrame.to_excel() 함수
-
pandas.DataFrame.to_excel()구문 -
예제 코드: Pandas
DataFrame.to_excel() -
예제 코드:
ExcelWriter를 사용하는 PandasDataFrame.to_excel() -
예제 코드: 기존 Excel 파일에 추가 할 Pandas
DataFrame.to_excel -
예제 코드: 여러 시트를 쓰는 Pandas
DataFrame.to_excel -
예제 코드:
header매개 변수가있는 PandasDataFrame.to_excel -
예제 코드:
index = False일 때 PandasDataFrame.to_excel -
예제 코드:
index_label매개 변수가있는 PandasDataFrame.to_excel -
예제 코드:
float_format매개 변수가있는 PandasDataFrame.to_excel -
예제 코드:
freeze_panes매개 변수가있는 PandasDataFrame.to_excel
Python Pandas DataFrame.to_excel(values) 함수는 데이터 프레임 데이터를 Excel 파일에 단일 시트 또는 다중 시트로 덤프한다.
pandas.DataFrame.to_excel()구문
DataFrame.isin(
excel_writer,
sheet_name="Sheet1",
na_rep="",
float_format=None,
columns=None,
header=True,
index=True,
index_label=None,
startrow=0,
startcol=0,
engine=None,
merge_cells=True,
encoding=None,
inf_rep="inf",
verbose=True,
freeze_panes=None,
)
매개 변수
excel_writer |
Excel 파일 경로 또는 기존pandas.ExcelWriter |
sheet_name |
데이터 프레임이 덤프하는 시트 이름 |
na_rep |
null 값을 나타냅니다. |
float_format |
부동 숫자의 형식 |
header |
생성 된 Excel 파일의 헤더를 지정합니다. |
index |
True이면 데이터 프레임 index를 Excel에 씁니다. |
index_label |
인덱스 열의 열 레이블입니다. |
startrow |
Excel에 데이터를 쓸 왼쪽 상단 셀 행입니다. 기본값은 0입니다. |
startcol |
Excel에 데이터를 쓸 왼쪽 상단 셀 열입니다. 기본값은 0입니다. |
engine |
사용할 엔진을 지정하는 선택적 매개 변수입니다. openyxl 또는xlswriter |
merge_cells |
병합 된 셀에MultiIndex 병합 |
encoding |
출력 Excel 파일의 인코딩. xlwt 작성기를 사용하는 경우에만 필요하며 다른 작성기는 기본적으로 유니 코드를 지원합니다. |
inf_rep |
무한의 표현. 기본값은inf입니다. |
verbose |
True인 경우 오류 로그가 추가 정보로 구성됩니다. |
freeze_panes |
고정 된 창의 맨 아래 및 맨 오른쪽을 지정합니다. 1부터 시작하지만 0부터 시작하지는 않습니다. |
반환
없음
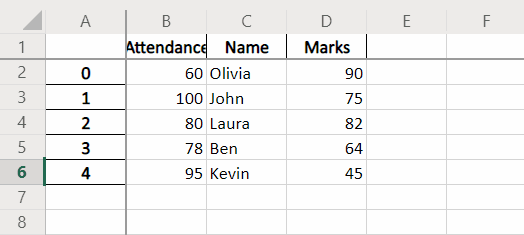
예제 코드: Pandas DataFrame.to_excel()
import pandas as pd
dataframe= pd.DataFrame({'Attendance': [60, 100, 80, 78, 95],
'Name': ['Olivia', 'John', 'Laura', 'Ben', 'Kevin'],
'Marks': [90, 75, 82, 64, 45]})
dataframe.to_excel('test.xlsx')
호출자DataFrame은
Attendance Name Marks
0 60 Olivia 90
1 100 John 75
2 80 Laura 82
3 78 Ben 64
4 95 Kevin 45
test.xlsx가 생성됩니다.

예제 코드: ExcelWriter를 사용하는 Pandas DataFrame.to_excel()
위의 예제는 파일 경로를excel_writer로 사용하고pandas.Excelwriter를 사용하여 데이터 프레임이 덤프하는 Excel 파일을 지정할 수도 있습니다.
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer)
예제 코드: 기존 Excel 파일에 추가 할 Pandas DataFrame.to_excel
import pandas as pd
import openpyxl
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx", mode="a", engine="openpyxl") as writer:
dataframe.to_excel(writer, sheet_name="new")
엔진을openpyxl로 지정해야하지만 기본xlsxwriter는 지정하지 않아야합니다. 그렇지 않으면xlswriter가append 모드를 지원하지 않는다는 오류가 발생합니다.
ValueError: Append mode is not supported with xlsxwriter!
openpyxl은pandas의 일부가 아니므로 설치하고 가져와야합니다.
pip install openpyxl
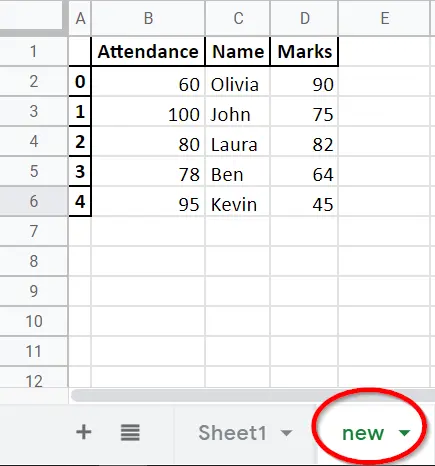
예제 코드: 여러 시트를 쓰는 Pandas DataFrame.to_excel
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, sheet_name="Sheet1")
dataframe.to_excel(writer, sheet_name="Sheet2")
데이터 프레임 객체를Sheet1과Sheet2 모두에 덤프합니다.
columns매개 변수를 지정하면 여러 시트에 다른 데이터를 쓸 수도 있습니다.
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, columns=["Name", "Attendance"], sheet_name="Sheet1")
dataframe.to_excel(writer, columns=["Name", "Marks"], sheet_name="Sheet2")
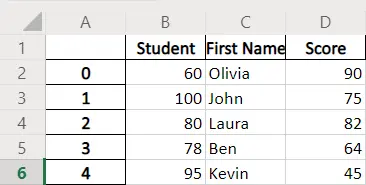
예제 코드: header 매개 변수가있는 Pandas DataFrame.to_excel
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, header=["Student", "First Name", "Score"])
생성 된 Excel 파일의 기본 헤더는 데이터 프레임의 열 이름과 동일합니다. header 매개 변수는 기본 헤더를 대체 할 새 헤더를 지정합니다.
예제 코드: index = False 일 때 Pandas DataFrame.to_excel
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, index=False)
index = False는DataFrame.to_excel()이 헤더 행없이 Excel 파일을 생성하도록 지정합니다.
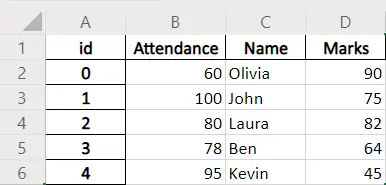
예제 코드: index_label 매개 변수가있는 Pandas DataFrame.to_excel
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, index_label="id")
index_label = 'id'는 색인 열의 열 이름을id로 설정합니다.
예제 코드: float_format 매개 변수가있는 Pandas DataFrame.to_excel
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, float_format="%.1f")
float_format = "%.1f" 는 두 개의 부동 숫자를 갖도록 부동 숫자를 지정합니다.
예제 코드: freeze_panes 매개 변수가있는 Pandas DataFrame.to_excel
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": [60, 100, 80, 78, 95],
"Name": ["Olivia", "John", "Laura", "Ben", "Kevin"],
"Marks": [90, 75, 82, 64, 45],
}
)
with pd.ExcelWriter("test.xlsx") as writer:
dataframe.to_excel(writer, freeze_panes=(1, 1))
freeze_panes = (1,1)은 Excel 파일에 고정 된 맨 위 행과 고정 된 첫 번째 열이 있음을 지정합니다.

Founder of DelftStack.com. Jinku has worked in the robotics and automotive industries for over 8 years. He sharpened his coding skills when he needed to do the automatic testing, data collection from remote servers and report creation from the endurance test. He is from an electrical/electronics engineering background but has expanded his interest to embedded electronics, embedded programming and front-/back-end programming.
LinkedIn Facebook