Python で Tesseract を使用して画像からテキストを読み取る

PythonでTesseractを使って画像からテキストを読み込めるプログラムの作り方を紹介します。
Python の Tesseract
画像からテキストを読み取る必要がある関数を含むシステムで作業する場合、Python で Tesseract を使用します。 画像からテキストをより正確かつ効率的に読み取るのに役立つ強力な機能を提供します。
この記事では、人気のある OpenCV ライブラリを使用して画像からテキストを抽出する方法についても紹介します。
Tesseract は、光学式文字認識 (OCR) およびその他の画像からテキストへのプロセス用のコンピューター ベースのシステムです。 主に、ラテン アルファベットを使用しない言語でのテキスト認識に使用されます。
このシステムは、テキストやデータのマイニング、教育、翻訳、機械翻訳など、さまざまな目的で使用されています。
Tesseract は、ソフトウェアのオープン ソース バージョンの名前でもあります。 テキスト分類やその他のテキスト関連タスクの自然言語処理や機械学習でよく使用されます。
まず、次のコード行を使用して Python に Tesseract ツールをインストールしましょう。
pip install pytesseract
Tesseract ツールをインストールしたら、画像からテキストを読み取るために例で使用する他の重要なライブラリをインストールします。 まず、次のコマンドで OpenCV をインストールします。
pip install opencv-python
次に、使いやすいコマンドライン インターフェイスを作成するために使用する ArgParse ライブラリをインストールします。 次のコマンドを使用して簡単にインストールできます。
pip install argparse
次に、Python イメージング ライブラリである Pillow ライブラリをインストールします。 このライブラリは、画像処理機能を Python インタープリターに追加します。
以下に示すコマンドを使用して、このライブラリをインストールできます。
pip install Pillow
Python で Tesseract を使用して画像からテキストを読み取る
それでは、Tesseract を使用して、Python で画像からテキストを読み取りましょう。 それを機能させるには、次の手順に従う必要があります。
まず、テキストを読みたいギャラリーから画像をインポートまたはロードします。画像がない場合は、Chrome からダウンロードしてからロードできます。
画像をインポートしたら、読み込んだ画像をバイナリ ファイルに変換します。 最後のステップでは、バイナリ ファイルを Tesseract に送信します。Tesseract は、それらのテキストを検索し、画像からテキストを返します。
以前にインストールしたすべてのライブラリをインポートします。
# python
import cv2
import os
import argparse
import pytesseract
from PIL import Image
以下に示すように、ArgParse 関数 ArgumentParser() を使用して引数パーサーを構築します。
# python
imgArg = argparse.ArgumentParser()
imgArg.add_argument("-i", "--image", required=True, help="Enter path of image folder")
imgArg.add_argument(
"-p", "--pre_processor", default="thresh", help="the preprocessor usage"
)
arguments = vars(imgArg.parse_args())
次のコードで OpenCV ライブラリを使用して、テキストを含む画像を読み取ります。
# python
imageRead = cv2.imread(arguments["image"])
次に、以下に示すように、OpenCV ライブラリを使用して画像をグレースケールに変換します。
# python
imgGray = cv2.cvtColor(imageRead, cv2.COLOR_BGR2GRAY)
次に、if-else ステートメントを使用して、画像がつぶれたりぼやけたりしていないかどうかを確認します。 そうであれば、以下に示すようにスレッシュとブラーを変更できます。
# python
if arguments["pre_processor"] == "thresh":
cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
if arguments["pre_processor"] == "blur":
cv2.medianBlur(gray, 3)
以下に示すように、OpenCV および Tesseract ライブラリを使用してメモリにイメージを追加します。
# python
nameImg = "{}.jpg".format(os.getpid())
cv2.imwrite(nameImg, gray)
imgText = pytesseract.image_to_string(Image.open(nameImg))
os.remove(nameImg)
print(imgText)
ここで、次のコードを使用して画像出力を表示します。
# python
cv2.imshow("Images Uploaded", imageRead)
cv2.imshow("Images Converted In Grayscale", imgGray)
cv2.waitKey(0)
では、上記のコードを次のコードで実行して、どのように機能し、画像からテキストをどれだけうまく読み取れるかを確認してみましょう。
# python
python main.py --image img/read.jpg
お送りした画像は以下の通りです。
画像が処理されると、以下に示すようにグレースケールで保存されます。

コマンドプロンプトに次の出力が表示されます。
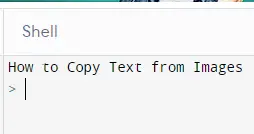
上記の例でわかるように、画像を簡単に使用してテキストを読み取ることができます。 また、必要に応じてそれらを保存したり、コンソールに表示したりできます。

Rana is a computer science graduate passionate about helping people to build and diagnose scalable web application problems and problems developers face across the full-stack.
LinkedIn